版权信息 书名:大模型应用开发:RAG实战课
ISBN:978-7-115-67185-1
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 黄 佳
责任编辑 秦 健
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
内容提要 在大模型逐渐成为智能系统核心引擎的今天,检索增强生成(RAG)技术为解决模型的知识盲区以及提升响应准确性提供了关键性的解决方案。本书围绕完整的RAG系统生命周期,系统地拆解其架构设计与实现路径,助力开发者和企业构建实用、可控且可优化的智能问答系统。
首先,本书以“数据导入—文本分块—信息嵌入—向量存储”为主线,详细阐述了从多源文档加载到结构化预处理的全流程,并深入解析了嵌入模型的选型、微调策略及多模态支持;其次,从检索前的查询构建、查询翻译、查询路由、索引优化,到检索后的重排与压缩,全面讲解了提高召回质量和内容相关性的方法;接下来,介绍了多种生成方式及RAG系统的评估框架;最后,展示了复杂RAG范式的新进展,包括GraphRAG、Modular RAG、Agentic RAG和Multi-Modal RAG的构建路径。
本书适合AI研发工程师、企业技术负责人、知识管理从业者以及对RAG系统构建感兴趣的高校师生阅读。无论你是希望快速搭建RAG系统,还是致力于深入优化检索性能,亦或是探索下一代AI系统架构,本书都提供了实用的操作方法与理论支持。
推荐语RECOMMENDATION 在推进具身智能落地的实践中,RAG技术正在重构机器人的知识处理范式。本书既有手把手的代码级指导,又包含架构设计的顶层思考,可作为AI工程师的案头工具书,也可作为CTO规划技术栈的决策参考。相信每一位追求智能系统实用价值的读者,都能从本书中获得跨越技术鸿沟的桥梁。
——宇树科技创始人兼CEO 王兴兴
本书系统构建了RAG技术的完整实施框架,涵盖从数据预处理、文本分块到向量存储与检索优化的全流程技术架构。书中深入解析了RAG核心组件的运行机制,并结合可落地的性能评估体系,为开发者提供了构建智能知识系统的全周期方法论。同时,本书还展望了GraphRAG、Multi-Modal RAG等新一代知识引擎的发展趋势。无论是希望了解大模型相关知识的专业人士,还是探索AI应用创新的实践者,都能从本书中获得兼具理论与实践的指导。
——新浪微博首席科学家,AI研发部负责人 张俊林
RAG是一种非通用的实验性技术范式。在实际应用中,通常是为了满足具体业务需求而采用RAG,而非围绕RAG来设计业务。这意味着需要针对不同的场景和问题进行专门的调整、优化,甚至定制化处理。《大模型应用开发 RAG实战课》一书从实现原理到代码实践,全面介绍了RAG技术的应用方法,涵盖了数据导入、文本分块、信息嵌入、向量存储、检索、系统评估及复杂范式等全链路知识,非常适合初级者入门学习。理解这些原理是进行有效优化的基础,读者可以以本书为起点,通过大量实践来深化理解,一定会有所收获。
——360人工智能研究院资深算法专家,老刘说NLP社区作者 刘焕勇
对大多数企业来说,要从大模型中获得生产力与提升运营效率,“招募”成千上万的数字员工是关键途径。然而,管理如此规模的数字员工队伍,即使对有管理万人团队经验的管理者来说,也是一个全新的挑战。企业不仅要借助大模型和流程编排工具,还需将这些技术与自身知识体系深度融合,具备幻觉对抗、权限控制、知识重构与解耦、自动更新以及过程可溯等能力,而实现这些目标的核心技术正是RAG。《大模型应用开发 RAG实战课》一书给我留下了深刻印象,尤其是咖哥精心绘制的技术图解。全书内容紧密贴合企业级RAG的实施路径,非常适合希望在企业中落地AI能力的朋友细读参考。
——杭州萌嘉(TorchV)创始人兼CEO 卢向东(@土猛的员外)
将大模型的通用智能与特定领域知识有效结合,是AI应用落地的核心挑战。RAG为此提供了重要的工程框架。本书深入浅出地剖析了RAG的技术栈与实践要点,对致力于构建高性能、可信赖AI应用的工程师和架构师而言,极具参考价值。
——谷歌AI开发者专家,极客时间“AI大模型系列训练营”作者 彭靖田
序未来奔涌而来:从RAG、AI Agent到MCP和A2A 这是最好的 时代,
也是最坏的 时代;
这是智慧 之春,
也是愚昧 之冬;
这是信仰的 纪元,
也是怀疑的 日子。
——查尔斯·狄更 斯 《双 城记》
好奇怪,大模型时代的时间流仿佛被加 速了。
我的《大模型应用开发 动手做AI Agent》于2024年5月出版之后,一系列新的模型、工具和架构如潮水般 涌现。
OpenAI的o1/o3/o4系列模型能实现深度推理与严谨分析;DeepSeek的V3/R1以极低的训练成本和强大的推理能力,在一夜之间缩短了中美两国在AI大模型领域的差距;AI编程工具Cursor可以快速生成和优化代码,几近替代了初级程序员的日常工作;Anthropic的Computer Use和OpenAI的Operator能够通过屏幕控件直接操控计算机的操作界面;模型上下文协议(Model Context Protocol,MCP)强势登场,旨在为大语言模型(Large Language Model,LLM,简称大模型)提供一个标准化接口,使其能够直接连接并交互外部的数据源和工具;与此同时,Agent2Agent(简称A2A)协议的推出为多智能体协同提供了开放标准,使得不同框架和供应商构建的智能体能够实现无缝 通信。
每一项技术突破都如同汹涌的海浪,不断冲击并拓展着我们对于AI及大模型应用开发的认知边界。新模型迅速取代旧模型,甚至在其广为人知之前便已被更新的技术超越;新工具刚一推出,就有成百上千个类似的竞品紧随其后,令人目不暇接;一本关于新技术的图书尚未出版,可能就已经过时。这或许是技术人员的悲哀,但同时也是他们的 幸运。
这是最坏的时代,这是最好的 时代。
在这个呼啸奔腾的时代,我们置身于滚滚浪潮中,努力捕捉那些闪耀的浪花。这些代表着人类智慧结晶的技术成就,值得我们反复端详,思考它们的 价值。
● 真希望,这些浪花具有代表性,能够在当下为技术人员提供实用指导,使基于大模型的开发变得更加清晰、便捷且得心 应手。
● 真希望,这些浪花具有生命力,是能够在汹涌澎湃的浪潮中沉淀下来的底层技术核心,是能够持续创造实际价值的算法、框架和理论,而不是转瞬即逝的 泡沫。
那么,一个关键问题摆在面前: 技术人员如何在迅猛增长的知识浪潮中筛选精华,去除糟粕,深入理解大模型应用开发的 本质?
我的看法是从两条主线 出发。
第一条主线是 利用大模型的逻辑思维和工具调用能力,在业务和产品的各个层次开发出具有Agentic(代理性)的应用 。这一路径可以参考我在《大模型应用开发 动手做AI Agent》中引用并详细描述的“Agent演化过程的5个层级”。A2A协议的出现为这一方向注入了新的活力,它通过定义智能体之间的通信标准(例如Agent Card、任务管理和消息传递),使得不同框架下的智能体能够协同工作,并动态协商交互 方式。
第二条主线是 做好大模型时代的知识检索 。通俗地说,可以将大模型视为一个汇聚了人类历史上所有智慧与知识的水晶球。然而,获取这些知识是有门槛且不易的。 如何在特定的时间、场景、环境及企业需求下,快速而精准地获取所需的知识,正是大模型时代应用开发需要解决的核心 问题。
基于大模型进行知识检索的应用开发,其复杂程度可高可低。从通过简单的提示词与大模型对话到涉及万亿参数的大模型训练与微调,只要你是通过大模型来获取所需的知识,就是在进行大模型应用开发。随着应用需求难度的增加,逐步引入更复杂的技术以充分发挥大模型的潜力变得尤为 重要。
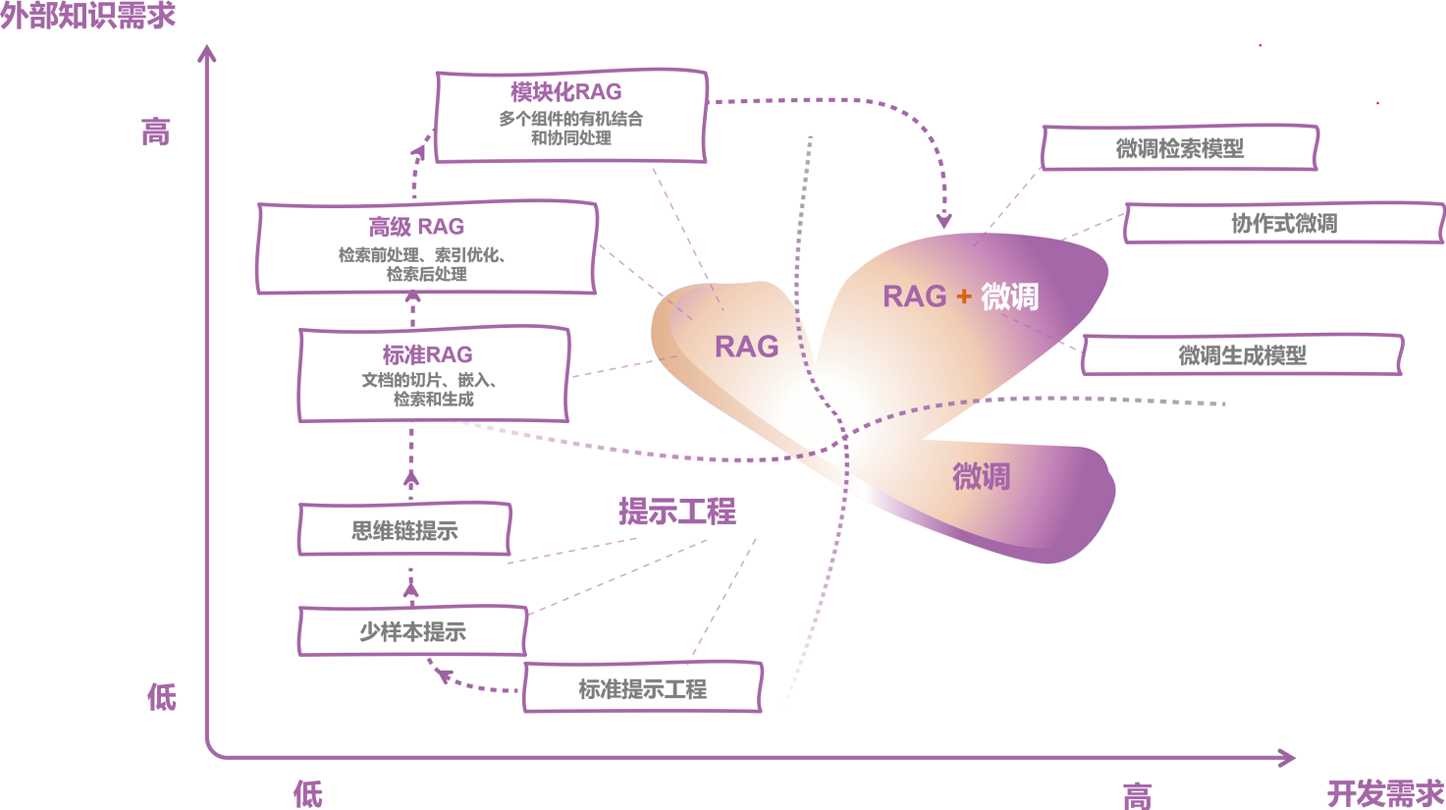
在此过程中,从简单到复杂,从通用到专业,存在一条重要的技术演进路径,覆盖了提示工程、检索增强生成(Retrieval-Augmented Generation,RAG)和模型微调这三大技术 领域。
提示工程(Prompt Engineering)对模型和外部知识的改动需求较低,主要依靠大模型本身的能力;相比之下,一系列微调(Finetuning)技术则需要进一步训练模型,这对开发者提出了更高的技术要求,并增加了成本。 RAG平衡了这两者的特点,对模型改动的需求相对较小,目前处于技术演进路径的核心位置,如图1 所示 。
图1 RAG位于技术演进路径的核心位置(Fan, et al,2024)
让我们从开发者的角度简单解读这条重要技术演进路径中的关键 技术。
起步:标准提示工程 标准提示工程是大模型应用开发中的“Hello World”。 如果你曾经在网页上直接与模型对话,那么恭喜你已经迈出了大模型应用开发的坚实第 一步。
值得注意的是,尽管标准提示工程使用起来非常简单,但它并不意味着低效。朋友圈中广泛流传的“李继刚神级Prompt:汉语新解”就曾备受关注。该案例结合Claude 3.5 Sonnet模型展现出了令人惊艳的效果(见图2),其创意和巧妙之处让人耳目 一新。
图2 大模型通过标准提示工程创建的文案
上面的提示词受到Lisp风格的启发,包含了一些Lisp语法元素的伪代码。这种设计旨 在表达抽象的思想,并借用Lisp的语法元素来清晰地阐述概念和复杂的逻辑关系。当然,这段提示词也可以完全转换为自然语言,在网页中传递给大模型,让大模型根据这一思路解释 新词。
此外,李继刚分享的关于提示词创作过程中的感悟 也给人留下了深刻印象: 并非大模型生成的内容缺乏创意,而是其创造潜力需依赖人类创造力的引导才能充分 释放 。
因此,尽管标准提示工程看似基础,但它是通往更高级大模型应用开发的重要 入口。
思维框架:提示工程的进阶之路 对于开发者,提示工程及其与大模型的交互往往通过程序代码和API(Application Program Interface,应用程序接口)调用来实现。随着对模型输出质量要求的提高,开发者很快就会意识到标准提示工程的局限性。因此,诸如少样本提示、思维链、思维树及ReAct等高级提示技术和大模型思维框架 应运 而生。
图3所示的代码段展示了在调用DeepSeek大模型生成文案时,加入少样本提示示例和思维链 引导,可以更好地满足生成 要求。
图3 通过程序代码和API调用来实现提示工程的过程
通过少样本提示等方式建立起一套思维框架或思维协议,目的是将大模型的思维能力提升至一个新的高度。例如,涂津豪在GitHub网站上发布了一份名为“Thinking Claude”的指南和一个浏览器插件,该指南旨在指导Claude在回答之前进行深入且系统的思考。他说:“我只想探索我们能用Claude的‘深度思维’走多远。当你在日常任务中使用它时,你会发现Claude的内心独白(思考过程)非常有趣。”
而DeepSeek-R1在思维链引导下经过强化学习训练,能够在复杂问题的解答上展现出很强的推理能力。这恰恰证明了这种结合了提示工程与思维框架的方法,使得大模型能够更接近人类的思考方式,从而在文本创作、代码生成以及知识问答等任务中取得更好的效果。
RAG:知识的跃迁 当应用需要引入大量外部知识时,RAG成为关键。这是一种结合信息检索与生成式AI的技术框架,旨在通过从外部知识库中检索相关信息,增强大模型的生成能力,从而提高上下文相关性和回答的准确性。
RAG的核心在于,当大模型面对一个问题时,并非依赖于其在训练过程中“记住”的知识来作答;相反,它可以访问一个外部知识库或文档集,从中检索与当前问题相关的片段,将这些最新或特定领域的外部信息纳入“思考过程”,然后再进行回答生成 。换句话说,RAG使大模型能够“查阅资料”,将静态、受限于训练时间的语言模型转变为能够动态获取信息、实时扩展知识的智能体。如此一来,对大模型的“闭卷考试”瞬间变成了“开卷考试” ,可以想象这种变化对大模型应用效果提升的巨大潜力。
RAG的核心组件包括知识嵌入、检索器和生成器。
● 知识嵌入(Knowledge Embedding) :读取外部知识库的内容并将其拆分成块,通过嵌入模型将文本或其他形式的知识转化为向量表示,使其能够在高维语义空间中进行比较。这些嵌入向量捕捉了句子或段落的深层语义信息,并被索引存储在向量数据库中,以支持高效检索。
● 检索器(Retriever) :负责从外部知识库(向量表示的存储)中查找与用户输入相关的信息。检索器采用嵌入向量技术,通过计算语义相似性快速匹配相关文档。常用的方法包括基于稀疏向量的BM25和基于密集向量的近似最近邻检索。
● 生成器(Generator) :利用检索器返回的相关信息生成上下文相关的答案。生成器通常基于大模型,在内容生成过程中整合检索到的外部知识,确保生成的结果既流畅又可信。
从RAG的执行流程来看,又可以将整个系统进一步细化为以下10个阶段。
● 数据导入(Loading) :将原始数据加载到系统中,通常包括多种格式的文档、数据库和文件。
● 文本分块(Chunking) :将大文档切分为易于处理的小块,以优化检索效率和信息嵌入。
● 信息嵌入(Embedding) :为每个文本块生成向量表示,捕捉其语义信息,便于高效检索。
● 向量存储(Vector Store) :存储生成的嵌入向量及其关联的原始文本,常用工具包括Milvus、Pinecone等。
● 检索前处理(Pre-Retrieval) :对查询进行预处理或转换,提升检索精度,例如通过查询扩展或语义重构。
● 基于索引的检索(Retrieval) :基于知识库构建时所设计的索引结构,从向量存储中查找最相关的文档,并返回给生成器。
● 检索后处理(Post-Retrieval) :对检索到的结果进行清洗、排序或格式化,以便生成器更好地利用。
● 响应生成(Generation) :生成器根据用户输入及检索结果生成最终答案。
● 系统评估(Evaluation) :对生成结果进行质量评估,包括准确性、一致性和覆盖率。
● 复杂检索策略和范式 :在特定场景下,采取各种策略来优化整体性能,如与知识图谱结合、与自主代理结合进行多轮检索或多知识源检索。
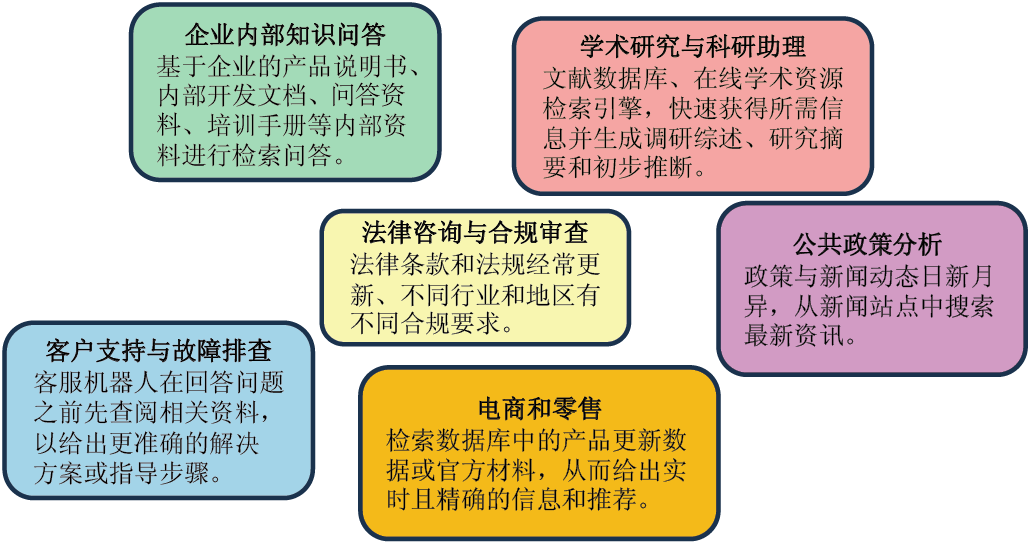
RAG是大模型时代应用开发的一项伟大创新,它弥补了大模型单纯靠参数记忆知识的不足,使之在应对不断变化或高度专业化的问题时具有更强的适应性和灵活性。因此,RAG不仅提高了大模型回答的准确性、时效性和权威性,也为大模型落地各类垂直领域应用提供了广阔的空间和技术基础(见图4)。
图4 RAG在各类垂直领域的应用场景
通过RAG,我们真正实现了“模型的智力”与“人类知识宝库”的有机结合,使得智能系统更加紧密地嵌入实际业务流程,为用户提供始终符合时代、情境、专业要求的智慧服务。可以说,在当前阶段,我所接触到的大模型落地应用项目中,RAG技术栈是最常被采用且最为扎实的选择, 无论从项目数量还是应用质量上看,都超过了AI Agent这条开发路径。(当然,AI知识检索和AI Agent这两条开发路径是你中有我,我中有你,并非互斥关系。)
微调:终点与新起点 当RAG技术手段仍不足以满足应用需求时,可以考虑微调。相比通过提示工程和RAG来优化输出,微调能够从底层直接改进模型的内在参数,使其对特定任务、领域和用例有更强的适应能力。
大模型的微调是一个与RAG、AI Agent开发都截然不同的技术栈,主要涉及深度学习和模型训练优化技术。本书并不过多讨论这些技术。此外,绝大多数“应用级别”的大模型开发也通常止步于微调。
微调和RAG并非没有交集,通过某些特定的微调策略,可将大模型嵌入特定业务场景中,提升RAG系统的性能。
AI Agent与RAG的融合:双轮驱动 AI Agent与RAG作为大模型应用开发的双轮驱动,正在经历深刻的融合。AI Agent的代理属性使其能够主动执行任务、调用工具并与环境交互,而RAG通过知识检索为AI Agent提供了动态的外部信息支持。
二者的结合将催生更强大的智能体系统:AI Agent不仅能“做事”,还能“查资料”以确保决策的准确性和上下文相关性。例如,一个基于RAG的AI Agent在处理客户服务请求时,可以实时检索最新的产品文档或用户历史记录,从而生成更加精准的响应。
MCP与A2A:奔涌而来的未来 这种融合通过MCP和A2A协议的标准化接口得以进一步放大。MCP为AI Agent和RAG系统提供了统一的外部数据和工具接入方式,通过标准化接口打破了模型与外部数据源之间的壁垒,使其能够无缝整合企业内部的数据库、API及其他知识源。而A2A协议则更进一步,通过定义智能体间的通信规范解决了多智能体协作的痛点,使不同生态中的智能体能够“用同一种语言”沟通,协同完成复杂任务。
例如,一个基于AutoGen的财务分析Agent可以通过A2A协议与LangGraph驱动的市场预测Agent协作,实时共享任务状态,并结合RAG检索到的实时市场数据,共同生成综合报告。这种多智能体协同与知识增强的结合,正在将单一的AI应用推向分布式、模块化的智能生态,重塑AI应用的边界,推动从单体智能到协同智能网络的跃迁。
MCP和A2A协议的出现,恰使RAG与AI Agent的应用如涓涓细流汇聚成汹涌的江河,为基于大模型的应用开发注入了全新的动能。未来的AI系统将不再是孤立的模型或应用,而是由无数智能体和知识模块组成的动态网络。开发者能够以前所未有的便捷性,将AI Agent、RAG、MCP和A2A协议的能力整合到业务场景中,构建出高效、灵活且可扩展的解决方案。
智能体不仅能通过RAG获取知识,还能通过A2A协议与其他智能体协同工作,并利用MCP接入全球化的数据和工具资源。在这一生态系统中,创新将以指数级速度涌现,企业和个人将共同见证AI潜力的全面释放。
上述从简单到复杂、从通用到专业的技术演进路径,正是大模型应用开发浪潮中最具代表性的底层内核。作为开发者,我们的任务是在这条技术演进的道路上不断学习、实践和创新。既要夯实那些经得起时间考验的技术基础,也要持续跟进并敏锐捕捉新技术带来的机遇与挑战,以充分发挥大模型的潜力,创造出对个体有用、对企业实用,乃至能够真正改变世界的应用。
RAG作为这一路径的核心技术,尽管其潜力巨大且学习曲线相对平缓,但其所涵盖的技术栈特别广泛,实现过程也伴随着若干难点。数据导入需处理多源异构数据,确保清洗和标准化的高效性;查询预处理过程中的Text2SQL要求准确地将自然语言转换为结构化查询,以应对复杂的数据库模式和动态需求;索引的构建与优化则需要在语义准确性、查询速度和动态更新之间找到平衡。这些挑战构成了RAG开发的核心,也是开发者需要重点攻克的技术障碍。
在大模型时代,下定决心深入学习某项技术的内核是有风险的,因为一些未经充分验证的技术可能很快就会过时。鉴于时间有限而知识资源极其丰富,在选择学习的内容和方法时就需要更加审慎。因此,非常感谢你对我的信任。接下来,让我们一同开启RAG技术的大门,共同探索它所带来的无限可能。
黄佳
2025年春
题记EPIGRAPH 譬如为山,未成一篑,止,吾止也。譬如平地,虽覆一篑,进,吾往也。
——《论语·子罕》
自反而缩,虽千万人,吾往矣。
——《孟子·公孙丑上》
让我来解释一下这两段话,以及为什么我会选择这两段话作为这本书的开篇。
孔子说:“堆土成山,只差一筐土便能完成,却停下来,这是我自己选择的停止。从平地开始,自第一筐土起,不断向上堆积,这是我自己选择的向前。”
曾子对子襄说:“你有勇气吗?我曾经在孔子那里听到过关于大勇的道理:反省自己觉得理亏时,即便面对普通百姓,我难道就不感到害怕吗?反省自己觉得理直时,纵然面对千万人,我也勇往直前。”
技术图书的写作并非易事,在大模型辅助写作的时代,尤其需要保持真诚。从《零基础学机器学习》起步,梯度下降算法引领我进入了一个崭新的成长与学习的世界;《数据分析咖哥十话 从思维到实践促进运营增长》则是我尝试把机器学习技术应用于更广阔数据世界的一次实践;大模型的出现改变了这一切,我试图通过《GPT图解 大模型是怎样构建的》一书揭开其神秘面纱,让普通读者能够理解其训练原理的精妙之处;而《大模型应用开发 动手做AI Agent》恰逢其时地问世,与《大模型应用开发 RAG实战课》一道,为大模型技术的落地实操提供了完整的解决方案——这些图书远非完美,但它们都是我真诚的技术分享。孔子和孟子所言的“真诚”与“勇气”,贯穿于我的求学与创作旅程中的每一天。
《大模型应用开发 RAG实战课》是我写作生涯中迄今为止投入精力最多的作品,或许也是原创性最强的一部。面对一个既崭新又非常实用的主题,我试图构建一个适合初学者理解的认知框架,将各个组件逐一拆解讲解,同时展示它们如何整合在一起。在书中,我没有局限于LangChain或LlamaIndex等具体的RAG框架,也没有拘泥于DeepSeek或OpenAI GPT等特定模型,更没有追逐热点或急于求成,而是努力构建整个RAG技术栈的认知体系和底层架构。然而,当书稿最终完成并交到编辑手中时,我突然感到书中的各个章节似乎还不够透彻。随着我个人学习的速度以及技术的进展,在回顾某些技术栈时,我觉得仍有未尽之处——如果能写得更加深入该有多好。
我对自己所做的事情充满了信心,同时也感到忐忑不安,不确定这些作品是否真的能为读者带来价值。在本书即将问世的这一刻,我用孔子、曾子和孟子的精神来激励自己:“虽千万人,吾往矣!”
也以此与大家共勉:可以不完美,但既然选择向前,就要真诚而勇敢。
楔子 闹市中的古刹 秋天是北京最好的季节。天高云淡,阳光温暖而柔和,洒在大地上,为城市披上一层金色的薄纱。街道两旁的银杏树渐渐变黄,叶子在微风中沙沙作响,时不时有几片缓缓飘落,宛如一封封写满秋日诗意的信笺,轻盈地铺在地上。
没有春天的风沙、夏季的闷热,也没有冬日的严寒。现在空气清新,微风带着一丝丝凉意,吹拂过小雪的脸庞,她的精神为之一振。午饭后走回公司,穿过一条小胡同,看着阳光透过树叶斑驳地洒在老墙上,耳边偶尔传来远处的鸟鸣,宁静而悠然。她的心情也是怡然自得的,因为有一件开心的事儿,她要赶回去和创业搭档咖哥及小冰姐分享(见图1)。
图1 小雪穿梭在小胡同中
咖哥和小冰果然都在,看到小雪进来,齐声开口。
咖哥:项目谈得怎么样?
小冰:到底是哪个客户,这么重要,突然神秘兮兮地约人家吃午餐,连我们俩都不带上?
小雪:嘿嘿,不是我约客户,是客户约我。他们上午去法源寺参观考察,刚巧知道咱们公司在附近,就喊了我过去聊聊。我想着怎么说也得请人家吃顿饭,如果带上你们俩,不是增加成本吗?
咖哥:啥?
小雪:哪承想,人家怎么也不让我买单。唉,早知如此,我就带上你们俩了……
小冰:这!
小雪:哈哈。不过,今天我还真长知识了。他们告诉我,咱们公司附近的法源寺是北京市历史悠久的唐代古刹。我们在这里创业一年多,还不曾去拜访过这座名刹(见图2)。
图2 法源寺,又称悯忠寺,是北京市历史悠久的佛寺
小雪:还有另一件事。咖哥、小冰,咱仨创业这一年多来也够辛苦的,大家都很疲惫。开发团队前一阵子连续熬夜,我都看在眼里。作为CEO,我觉得是时候给大家安排一次团建了。公司里都是年轻人,你们看,咱们下个月安排一次山西之旅,好好玩几天如何?
咖哥和小冰面面相觑,心里都在想:小雪自从创业以来,对花钱的事情一直都很谨慎,怎么突然如此大方?团建的话,去京郊的野三坡、苟各庄,远一点的话,去灵山、金山岭,住一两晚也就可以了。这十来号人去山西一趟,得花多少钱?
看到咖哥和小冰的疑惑,小雪又哈哈笑了起来。
小雪:实话实说啦!其实,我刚刚和来自山西文旅宣传部门的同志签了一个大型的AI+文旅项目。说起来,这件事和《黑神话:悟空》的突然爆火有关。
咖哥和小冰:《黑神话:悟空》 ?
小雪:对啊,《黑神话:悟空》带火了山西旅游(见图3)。山西文旅部门的同志就想借着这个机会把这把火烧得更旺一些。之前,我在一些AI论坛和峰会上介绍过我们之前做的几个文旅相关的项目,例如智能导游、智能解说、景点知识问答库等,刚好也认识了山西文旅部门的赵书记。这一次,赵书记来北京开会,今天的行程是参观法源寺,同时也就和我敲定了一个即将开展的大项目。赵书记说,下个月邀请我们项目组的所有小伙伴去山西实地考察,结合我们之前做的AI文旅项目经验,好好挖掘一下山西省的旅游文化资源……
图3 游戏《黑神话:悟空》带火
咖哥:我说呢。我觉着小雪作为咱公司的CEO,不可能白白花投资人的钱带大家去那么远的地方团建。说到最后,其实还是去做项目,给你卖苦力啊。不过,这个项目还真不是一般的卖苦力,一边做项目一边到此一游,还能熏陶一下中华传统文化,我求之不得。
小雪:那就好。既然咖哥求之不得,今天晚上你就加班吧,人家已经把第一个需求发过来了。客户让你基于这几份文档,搭建一个智能问答检索系统的基本流程和框架。过两天就要看效果,我已经夸下海口,说咖哥干活快。你现在就加班完成一下吧!
咖哥:好嘞!
开篇 RAG三问 咖哥的效率果然很高,仅仅用了一个星期,他连基于《黑神话:悟空》知识库的RAG系统(见图0-1)都搭建好了。
图0-1 咖哥开发的RAG系统
小雪:咖哥,给小冰和其他同事讲一讲这个系统是如何构建的。
咖哥:当然可以,让我们从3个与RAG相关的基本问题开始。
一问 从实际项目展示到底何谓RAG 何谓RAG?
图0-2 RAG的工作流程
RAG的工作流程大致如下。
(1)嵌入与索引 :在系统准备阶段,已对一批文档(例如新闻报道、博客文章、分析报告等)进行分块处理,并将这些文本块转换为嵌入向量。这些嵌入向量会存储在向量数据库中(这个过程也称为索引),以便用于后续检索。
(2)用户输入 :用户向系统提出一个问题或查询。例如:“《黑神话:悟空》是什么类型的游戏?”
(3)检索 :在用户提交查询时,系统会根据用户的问题生成相应的查询向量,并在已建立的向量数据库中检索最相关的文本块。这是RAG的核心步骤——在回答前先查找适合的外部信息。
(4)生成并输出 :将用户原始问题和检索到的文本块一并传递给大模型。大模型在接收到相关上下文信息后,整合用户问题与检索到的信息,生成更准确的回答。在这一过程中,大模型的回答不仅依赖其自身的参数与训练记忆,还结合了更新、更权威的外部参考资料。
RAG通过将信息检索和文本生成相结合,使得大模型的回答更有依据且上下文相关,从而提高了回答的质量、可靠性和即时性。
那么,RAG系统究竟长什么样?如何设计?如果使用LangChain、LlamaIndex、Dify或者Ragflow等框架,可以在30 min之内构建一个RAG系统,但这样做会掩盖很多底层细节,不利于深入探究技术细节。
实际上,咖哥手动构建了一个简易且自主的RAG框架。这个框架并不依赖LangChain或者LlamaIndex等任何开源RAG框架。它有利于在做项目时调试不同的配置,比较不同的文档导入工具、分块工具及向量数据库,选择更合适的嵌入模型以及生成模型,这也有利于帮助理解RAG系统的设计细节。
接下来用这个简易的《黑神话:悟空》问答系统带你一窥RAG系统框架。
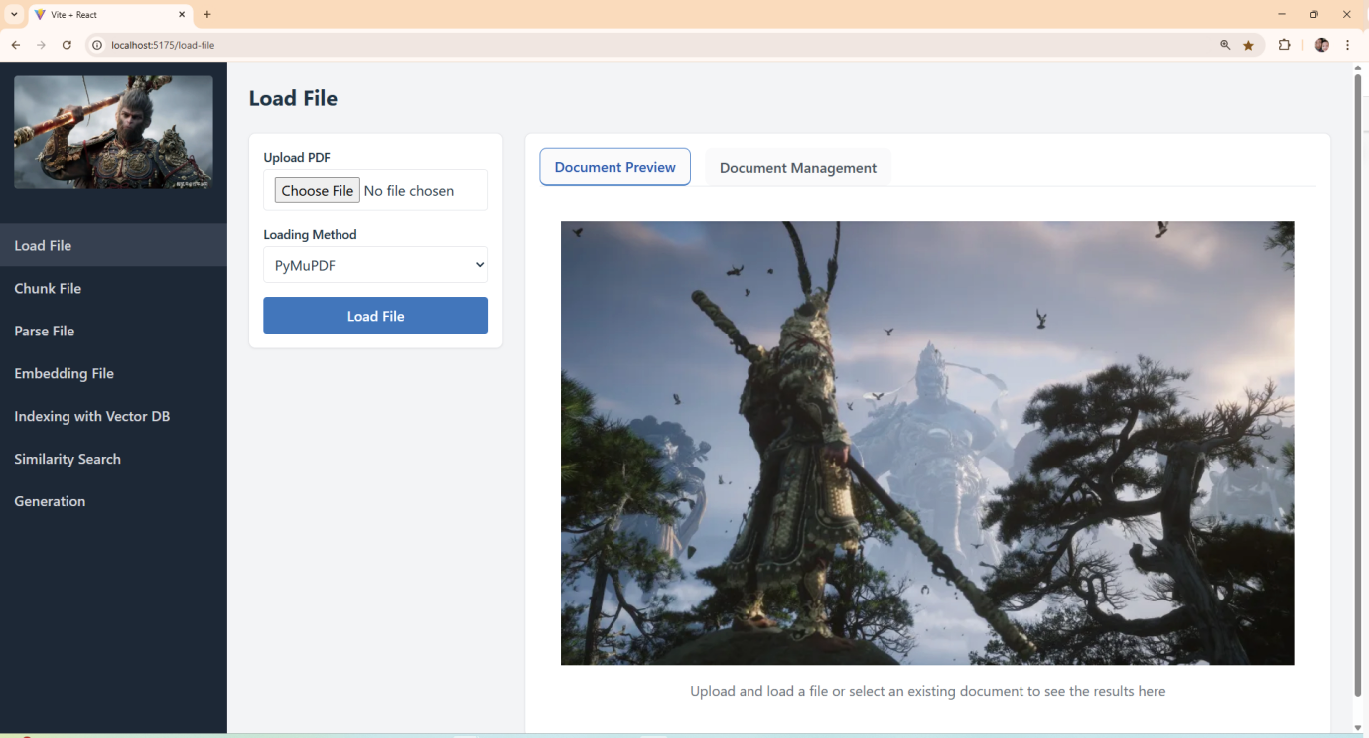
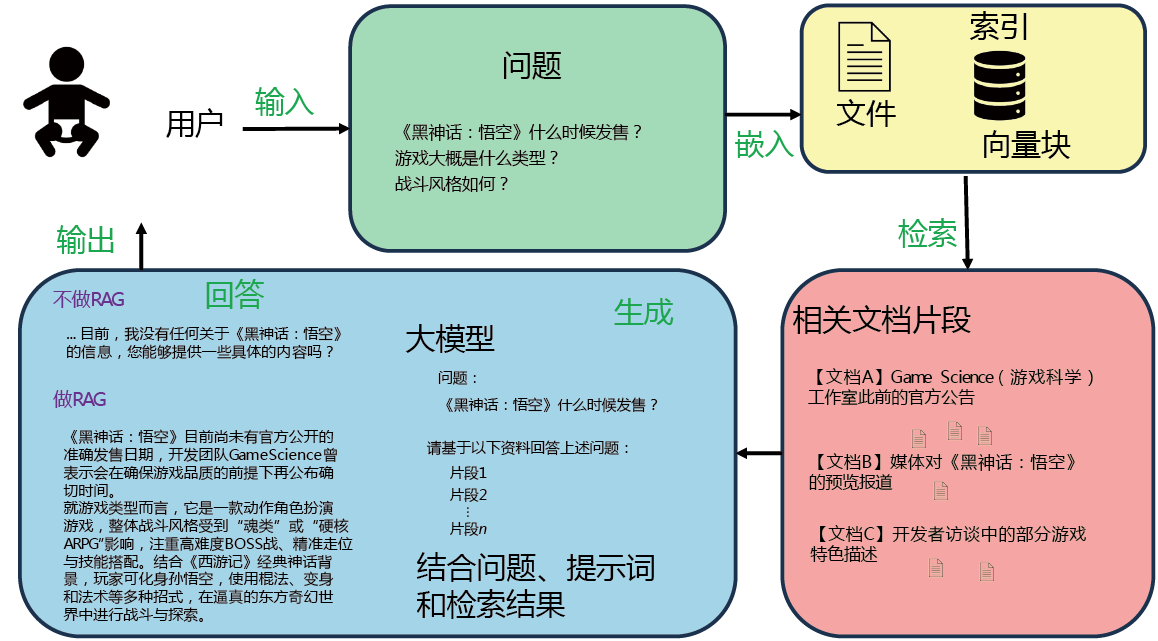
文档的导入和解析 在这个阶段,你需要将原始数据(如PDF文件、纯文本文件、HTML文件甚至图片中的文本)加载到系统中,以便后续进行分块和处理。就像图0-3展示的界面一样,这个简单的RAG系统支持从本地上传PDF文件,然后根据不同的解析方式加载文档。目前,这个系统支持PyMuPDF、PyPDF、Unstructured等不同的文档解析工具。当然,你也可以添加更多的文档解析工具。
图0-3 文档的导入和解析
不同的文档解析工具有各自的特点。在实际项目中,文档格式、结构和排版方式的不同,会导致文本提取质量的差异。下面列举了3款文档解析工具的特点。
■ PyMuPDF:基于MuPDF引擎,通常对PDF文件的解析准确且高效,但在处理复杂排版时,可能会出现字符错位或者换行混乱的问题。
■ PyPDF:作为一款更基础的Python PDF文件解析工具,它对简单的PDF文件处理效果良好。然而,在面对扫描版PDF文件或者具有复杂格式的文件时,其解析质量可能不及MuPDF。
■ Unstructured:这款工具不仅能解析PDF文件,还支持解析各种类型的文件,如HTML文件、Word文档、电子邮件等,并能提供更为高级的结构化输出。对于非PDF格式的文档,或者需要对文档结构(如标题、段落、列表等)进行更细粒度的控制时,它具有明显的优势。
在《黑神话:悟空》问答系统中,会将游戏官方发布的一些游戏设定文档、媒体采访稿、预告片文案或相关背景资料通过这些工具加载进来。具体到各种类型文件如何载入,以及各种解析工具的使用方法,包括解析表格、图片等细节,将会在后续内容中详细讲解。
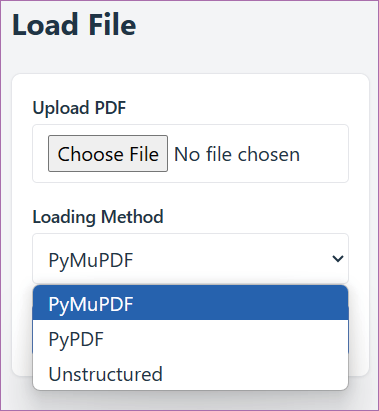
文档的分块 文档成功导入并被解析为纯文本之后,下一步是对文本进行合理的切分(见图0-4)。这是因为在进行检索增强生成时,大模型需要从外部存储中迅速找到与用户查询最相关的文本片段。常见的做法是将长文档切分成较小的文本块,每个文本块可能包含几百个字符或几句话。
图0-4 文档的分块
为何要进行分块? 长文档无法一次性全部加载到大模型的上下文中,即便可以这样做,也非常耗费资源。此外,将长文档切分成多个文本块后,可以对每个文本块独立执行嵌入操作和建立向量索引。在检索阶段,只需将用户查询的向量与这些文本块向量进行计算(例如采用相似度计算),即可快速找到最为相关的文本段落。
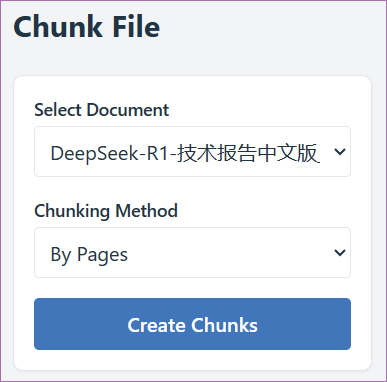
另外,存在多种分块策略,如图0-5所示。例如,对于PDF文件,可以根据页码进行分块(如By Pages),以保留原始的版面布局和分页逻辑。也可以根据固定的字符数或Token数来切分文本,均衡控制每个文本块的大小,便于计算嵌入并进行向量化处理。然而,这种方法可能会破坏句子或段落的语义完整性,因此,依据自然结构(如按照段落、句子)进行切分,更加符合文本的语义构造,使得检索出的内容在语义上更加连贯,更易于大模型理解和回应。
图0-5 分块策略
选择合适的分块策略时,应在语义完整性 和检索粒度 之间寻求平衡。关于这些细节知识,我们将在后续内容中详细探讨。
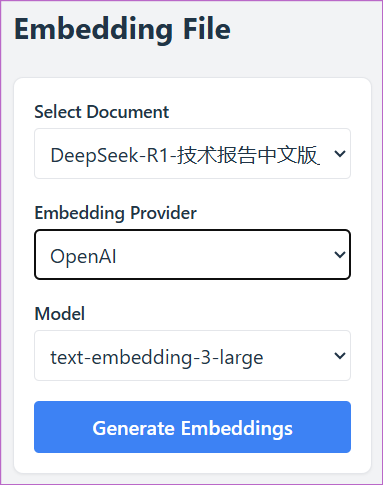
文本块的嵌入 接下来,通过嵌入模型对每个文本块进行向量嵌入,将文本转换为高维向量表示(见图0-6),随后这些向量会被存储到向量数据库中。嵌入模型的选择是可配置的,例如,可以选择OpenAI的text-embedding-3-large、Hugging Face基于transformers库的嵌入模型(如sentence-transformers)、智源研究院的BGE模型、阿里巴巴通义实验室的GTE模型,以及由Cohere、VoyageAI、Jina等提供的嵌入模型。
图0-6 文本块的嵌入
在这个自建的RAG系统中,分块完成后咖哥会调用一个嵌入模型,将每个文本块转换成向量。在代码层面,可以灵活配置和替换嵌入模型。例如,可以先使用OpenAI的embedding服务测试效果,然后切换到本地部署的sentence-transformers模型,以观察差异。
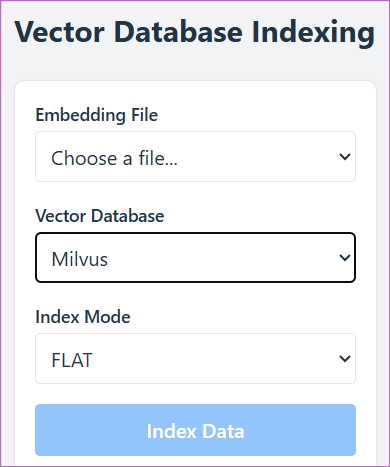
向量数据库的选择 将文本块转换成向量后,将其存储在哪里?接下来该向量数据库上场了。在这一阶段,咖哥会将得到的文本块向量及其关联的元数据(例如所属文档ID、段落位置、主题标签等)写入向量数据库。
向量数据库有多个选择,如图0-7所示。
■ Faiss:由Meta开源的轻量级向量检索库,适合本地快速搭建。
■ Pinecone、Weaviate和Qdrant:均为云端或本地环境下的先进向量数据库方案,提供丰富的API(Application Program Interface,应用程序接口)和可扩展性。
■ Milvus:一款国产开源向量数据库,提供优化的大规模相似度检索策略。
图0-7 向量数据库的
在开发原型系统时,可以先选用Faiss或Chroma这种简单易用的向量数据库,以便快速迭代和调试。当准备部署到生产环境时,再切换到更强大的向量数据库,如Milvus及其完全托管版本Zilliz Cloud。
索引是向量数据库用来高效存储和检索嵌入向量的底层数据结构。它通过组织向量数据,使得在大规模数据中查找相似向量的操作既快速又节省资源。多数向量数据库支持多种索引结构。
■ 平铺索引:也称为扁平索引、线性索引或全量索引等,意味着不必对数据进行降维、压缩或聚类等预处理,直接将所有向量存储在一个平面内,逐一计算查询向量与所有存储向量的距离,以找到最相似的结果。
■ 聚类索引:采用聚类算法(如k-means)将向量划分为多个簇,在查询时首先定位到最近的簇,然后仅在该簇内执行搜索。
■ 量化索引:采用量化技术对向量数据进行压缩存储,同时减少检索过程中的计算复杂度。
■ 图结构索引:这是一种基于图结构的索引方法,通过构建向量间的近邻图来迅速定位相似向量。
关于向量数据库的选择和索引设置的细节,将在后续内容中详细探讨。
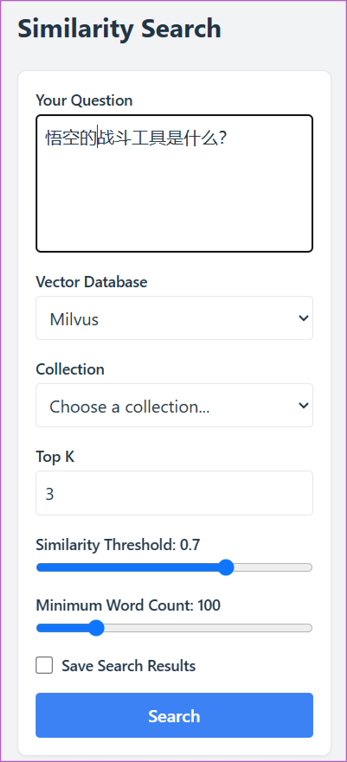
文本块的检索 检索(Retrieval,或称相似度检索)是整个RAG系统中至关重要的一步,其目的是从庞大的向量数据库中迅速找到与用户问题(也称为查询)最相关的信息,为后续生成回答提供上下文支持。
当用户输入问题(例如“悟空的战斗工具是什么?”)时,系统会首先通过嵌入模型将这段自然语言转化为一个高维向量(见图0-8)。这个向量在语义空间中代表用户的查询意图,以便与向量数据库中的文本向量进行相似度匹配。
图0-8 文本块的检索
在检索页面中,用户可以设置以下关键参数。
■ Top K:指定返回的相关结果数量,例如返回相似度最高的3个结果。
■ Similarity Threshold(相似度阈值):设定一个界限,只有相似度分数达到或超过此界限的结果才会被返回。
■ Minimum Word Count(最小词数):通过限制文本块的最小长度,避免返回过于简短或不完整的内容。
系统会在选定的向量数据库中对查询向量执行相似度检索,返回与其语义最接近的文本块。这一步利用之前存储的向量索引结构,实现了高效检索。
检索到的文本块会根据相似度分数进行排序,排序后的列表可以在后台查看,也可以直接作为查询结果呈现给用户。更为常见的情况是,这些检索结果将作为上下文输入生成步骤,供大模型进一步优化答案。
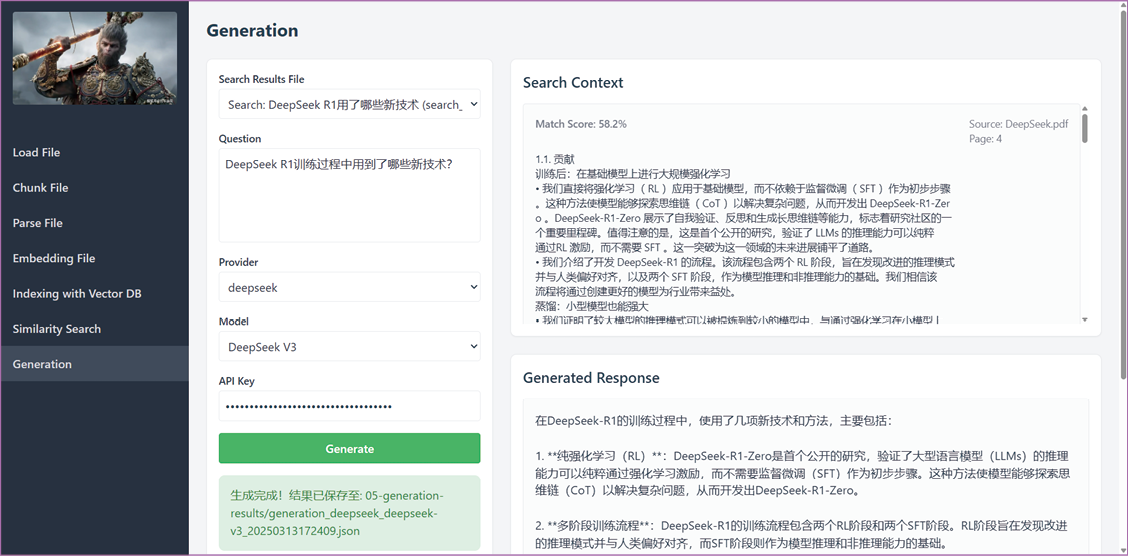
回答的生成 在检索完成后,系统将进入生成阶段。生成界面(见图0-9)会自动把检索到的相关文本块传递给大模型,作为上下文输入,并与用户的问题结合,形成完整的输入信息。然后,系统利用大模型和检索到的文本块来生成针对用户问题的回答。
图0-9 传入大模型的检索结果(右上)和生成的回答(右下)
生成模块的设计重点在于选择合适的大模型。例如,OpenAI的GPT系列模型和Anthropic的Claude系列模型适用于追求高质量回答的场景;Llama和Qwen系列模型由于其免费开源的特点,适合需要灵活部署的情况;DeepSeek、Kimi和ChatGLM等中文模型则更适合中文场景的应用,同时支持本地高效运行。用户可以切换不同的模型,并比较它们在生成质量、响应速度和资源消耗等方面的表现。
提示词同样是调整生成模块的关键因素之一。例如,通过提示词,可以指示模型使用专业术语作答或以通俗易懂的方式解释概念。此外,还可以通过设置选项来使得生成结果多样化,例如,可用温度(temperature)参数控制生成文本的随机性:较高的温度值可产生更具创意性的回答,而较低的温度值则有助于产出更为精确严谨的回答。
至此,你应该已经全面了解了一个清晰的自制RAG系统所需的设计过程。
二问 如何快速搭建RAG系统 提到快速搭建RAG系统,LlamaIndex提供了一个著名的5行代码 示例,非常适合新手快速上手——在获得成就感的同时了解整个RAG的开发架构。
使用框架:LlamaIndex的5行代码示例 在本示例中,咖哥将使用从互联网上获取的游戏设定文档。你可以从咖哥的GitHub仓库中下载相关资料。
首先,搭建相关的开发环境。新建一个Python环境并安装LlamaIndex包。
In
pip install llama-index
由于LlamaIndex的默认嵌入模型和生成模型都是OpenAI家族模型,因此还需要在环境变量中设置OpenAI API Key。(如果没有,也没关系,在后续内容中会介绍如何使用DeepSeek作为替代方案。)
In
export OPENAI_API_KEY=''你的OpenAI API Key''
LlamaIndex的5行代码如下。
In
# 第一行代码:导入相关的库
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 第二行代码:加载数据,形成文档
documents = SimpleDirectoryReader(''data/黑神话'').load_data()
# 第三行代码:基于文档构建索引
index = VectorStoreIndex.from_documents(documents)
# 第四行代码:基于索引创建问答引擎
query_engine = index.as_query_engine()
# 第五行代码:基于引擎开始问答
print(query_engine.query(''《黑神话:悟空》中有哪些战斗工具?''))
Out
在《黑神话:悟空》中,主要的战斗工具包括如意金箍棒等棍棒类武器,玩家可以使用劈棍、戳棍和立棍3种主要棍法进行多样化的战斗选择。
咖哥:看到了吧,在这5行代码中,流程和思路都非常清晰。不过,用这种方式来实现一个简单的RAG系统,有好处也有坏处。
小冰:怎么说?
咖哥:好处自然是简单方便,容易上手。而坏处嘛,在于所有的细节都被封装在LlamaIndex内部,这不利于我们深入了解RAG系统每个环节中的技术细节和内涵。若要深刻理解LlamaIndex中的索引、检索器、问答引擎等组件的技术细节与优化方法,仍需要仔细阅读LlamaIndex的官方文档,并进行大量的实践操作。
如果获取OpenAI API Key遇到困难,可以考虑使用开源的嵌入模型(如智源研究院的BGE系列模型)。在生成模型方面,国产的DeepSeek模型完全可以和GPT系列模型中最强模型相媲美。
要更换嵌入模型,首先需要安装llama-index的HuggingFace接口包。
In
pip install llama-index-embeddings-huggingface
然后,通过HuggingFaceEmbedding来加载开源嵌入模型。
In
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 加载本地嵌入模型
embed_model = HuggingFaceEmbedding(
model_name=''BAAI/bge-small-zh'' # 模型路径名,首次执行时会从Hugging Face社区网站下载
)
同时在构建索引时指定新的嵌入模型。
In
# 构建索引
index = VectorStoreIndex.from_documents(
documents, # 导入的文档
embed_model=embed_model # 设置嵌入模型
)
要更换生成模型,则可以先安装LlamaIndex与DeepSeek等模型的接口包。
In
pip install llama-index-llms-deepseek
随后,导入DeepSeek接口,使用最新的DeepSeek模型完成生成任务。
In
from llama_index.llms.deepseek import DeepSeek
# 创建DeepSeek模型(通过API调用DeepSeek-V3模型)
llm = DeepSeek(
model=''deepseek-chat'',
api_key=''你的DeepSeek API Key'' # 也可以通过环境变量设置DEEPSEEK_API_KEY
)
在创建问答引擎的同时指定新的生成模型。
In
# 创建问答引擎
query_engine = index.as_query_engine(
lm=llm # 设置生成模型
)
当然,你也可以根据上面的方式任意选择自己喜欢的嵌入模型和生成模型。
小雪:那么,构建好索引之后,将其存储在哪里?
咖哥:默认情况下,刚加载的数据以向量嵌入的形式存储在内存中,并在内存中进行索引。添加下面这行代码,可以将上面生成的纯文本文件中的向量数据保存到storage目录中,形成LlamaIndex默认的本地向量索引存储。
In
index.storage_context.persist()
运行程序后,会看到系统生成图0-10所示的本地向量索引存储文件。
图0-10 本地向量索引
小冰:应该如何理解这里所说的“索引”?
咖哥:向量索引作为RAG系统中的核心概念,在此上下文中,首先作为一个动词,指的是存储经过嵌入处理的文档数据的过程,其目的是支持高效的语义搜索。文档在加载后会被切分成多个文本块,每个文本块通过嵌入模型转换成高维嵌入向量,这些嵌入向量与元数据(如文档ID、段落位置等)一起存储在索引中(注意,此时索引作为一个名词)。索引利用底层的数据结构(如HNSW、平铺索引等),实现快速近似最近邻(Approximate Nearest Neighbors,ANN)搜索功能。
在前面的LlamaIndex示例中,VectorStoreIndex 没有连接任何向量数据库,也不涉及复杂的索引算法,默认情况下,只是将数据存储在内存中,但可以通过调用storage_context.persist函数将其保存到磁盘中。检索时仍然使用最直接的平铺索引在内存中完成线性扫描。
你可以查看这个目录下每个文件的内容,观察其存储格式,了解LlamaIndex如何组织和管理嵌入向量,相信这会让你对嵌入向量及其在本地的索引方式有更清晰的理解(关于更多内容,可以参见4.1节)。
使用框架:LangChain的RAG实现 介绍完LlamaIndex的5行代码示例,我们再来看看LangChain如何组织其接口和组件来完成一个基础的RAG系统,同时也看看LangChain和LlamaIndex在RAG实现思路和理念上的异同。
LangChain的安装也非常简单。执行以下命令来安装LangChain。
与LlamaIndex相似,如果需要与其他生态圈内的工具(如Hugging Face、Unstructured等)集成,可能还需要额外安装一些包(见图0-11)。完成本节示例还需要langchain-openai(非必需,可替换为国产模型)、langchain-deepseek(同样需要设置环境变量DEEPSEEK_API_KEY)和langchain-community,此外,还需要网页爬取工具BeautifulSoup。
图0-11 LangChain安装包的生态圈
首先,安装相关的包。
In
pip install langchain-openai # 非必需,可替换为国产模型
pip install langchain-deepseek
pip install langchain-community
pip install beautifulsoup4
export DEEPSEEK_API_KEY=''你的DeepSeek API Key''
LangChain在其文档中将RAG过程分为两个主要阶段——索引(Indexing)和检索加生成(Retrieval+Generation)。
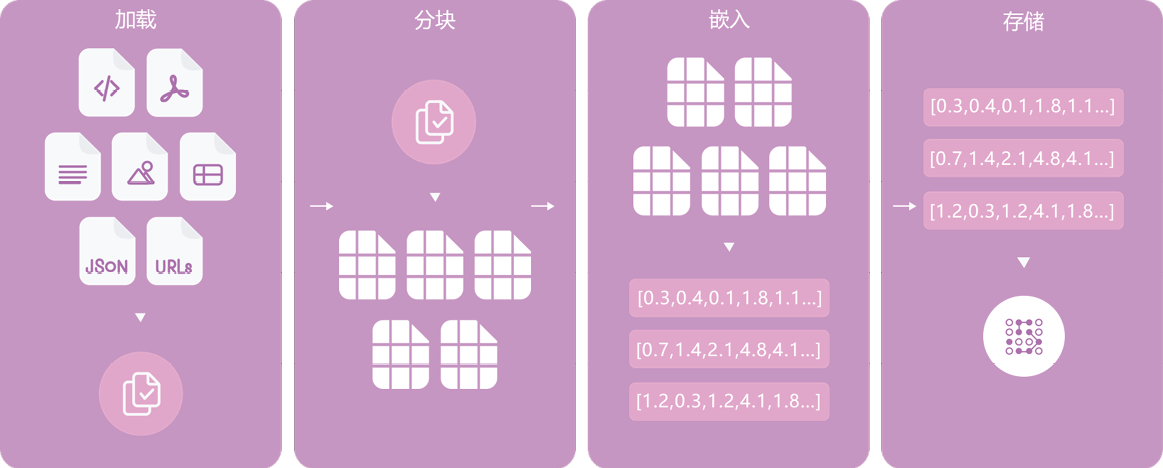
先看一下索引阶段,LangChain将其细化为加载、分块、嵌入和存储4个环节,如图0-12所示。
图0-12 索引阶段的4个环节
首先,利用WebBaseLoader加载相关的网页。当然,LangChain提供了丰富的数据和文档导入工具(也称为数据加载器)供选择。这里仅以导入网页为例。
In
# 加载文档
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=(''https://zh.wikipedia.org/wiki/黑神话:悟空'',) # 这是《黑神话:悟空》的维基百科链接
)
docs = loader.load()
接着,使用RecursiveCharacterTextSplitter对文档进行分块。
In
# 文本分块
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter( # 创建文本分割器
chunk_size=1000, # 设置每个文本块的最大字符数
chunk_overlap=200 # 设置相邻文本块的重叠部分
)
随后,将OpenAIEmbeddings作为嵌入模型创建嵌入向量。
In
# 设置嵌入模型
from langchain_openai import OpenAIEmbeddings
embed_model = OpenAIEmbeddings()
当然,也可以通过LangChain的HuggingFace接口替换OpenAI的嵌入模型。此处需要安装langchain-huggingface和文本嵌入工具包sentence-transformers。
In
pip install langchain-huggingface
pip install sentence-transformers
这样就可以使用开源嵌入模型了,在进行嵌入时可以拥有更多自由度。
In
# 设置嵌入模型,用开源模型替换OpenAI的嵌入模型
from langchain_community.embeddings import HuggingFaceEmbeddings
embed_model = HuggingFaceEmbeddings(
model_name=''BAAI/bge-small-zh'', # 模型的名称,首次运行会从Hugging Face社区网站下载
model_kwargs={'device': 'cpu'}, # 设备为CPU或者GPU(CUDA)
encode_kwargs={'normalize_embeddings': True} # 设置向量值归一化
)
接下来,创建向量存储机制。
In
# 创建向量存储(本例采用内存向量存储机制,不使用外部向量数据库)
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embed_model) # 使用之前定义的嵌入模型创建内存向量存储实例
vector_store.add_documents(all_splits) # 将分割后的文本块添加到向量存储中
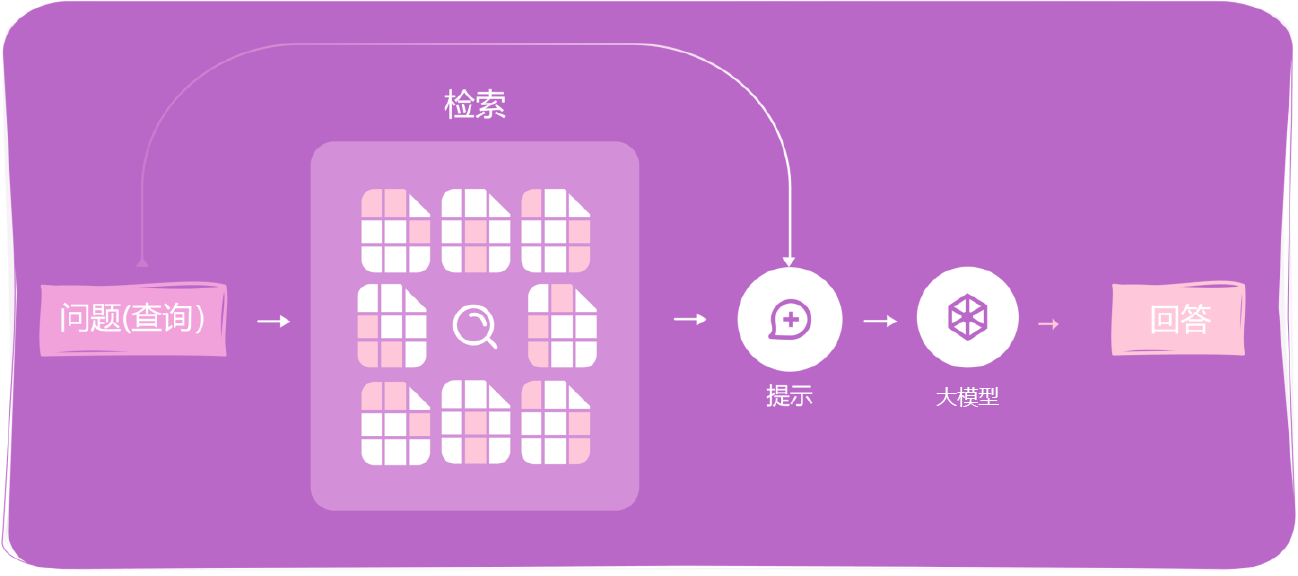
接下来,进入检索加生成阶段(见图0-13)。在这个阶段,首先需要接收用户查询的问题,其次搜索与该问题相关的文本块,接下来将检索到的文本块和初始问题传递给大模型,最后大模型生成回答。
图0-13 检索加生成阶段的各个环节
首先,构建用户查询的问题。
In
# 构建用户查询的问题
question = ''《黑神话:悟空》有哪些游戏场景?"
其次,根据问题,使用前面的向量存储进行检索,并根据检索结果准备传递给大模型的上下文内容。
In
# 在向量存储中搜索相关文档,并准备上下文内容
retrieved_docs = vector_store.similarity_search(
question, # 问题,也就是查询文本
k=3 # 返回前3个最相关的文档
)
docs_content = ''\n\n''.join(doc.page_content for doc in retrieved_docs)
接下来,根据检索得到的上下文,为大模型生成答案构建提示模板。
In
# 构建提示模板
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
''''''基于以下上下文回答问题。如果上下文中没有相关信息,请说
''我无法从提供的上下文中找到相关信息''。
上下文:{context}
问题:{question}
回答:"""
)
最后,使用大模型生成回答。
In
# 使用大模型生成回答
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model=''gpt-4'')
answer = llm.invoke(
prompt.format(
question=question, # 问题,也就是查询文本
context=docs_content # 检索到的文本块,也就是上下文
)
)
print(''\n最终答案:'', answer.content)
生成答案时,可以调整代码,通过ChatDeepSeek调用DeepSeek模型。
In
# 使用大模型生成回答,此处可以使用DeepSeek模型替换OpenAI的模型
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model=''deepseek-chat'', # DeepSeek API支持的模型名称
temperature=0.7, # 控制输出的随机性
max_tokens=2048, # 最大输出长度
api_key=''你的DeepSeek API Key'' # 如果没有设置环境变量,则需要在此指定DeepSeek API Key
)
Out
最终答案:游戏的设定融合了中国的文化和自然地标。例如重庆市的大足石刻、山西省的小西天、南禅寺、铁佛寺、广胜寺和鹳雀楼;贵州省的承恩寺;云南省的崇圣寺;天津市的独乐寺;四川省的安岳石刻、南充醴峰观、新津观音寺;河北省的蔚县玉皇阁、南安寺塔、井陉福庆寺等。
当然,因为DeepSeek公司已经将所有模型开源,因此通过API调用DeepSeek模型并不是唯一的方法,也可以通过LangChain和HuggingFace的接口在本地部署开源模型。需要注意的是,负责生成的大模型对GPU的需求通常比嵌入模型(这些模型通常参数较少)更多。因此,部署一个完整的671B DeepSeek-V3模型或者DeepSeek R1模型需要较高的成本。可以考虑通过Hugging Face社区网站下载DeepSeek公司提供的各种参数规模的蒸馏版模型。
LangChain的RAG整体实现流程与LlamaIndex非常相似。实际上,LangChain(也包括LlamaIndex)在此方面的主要贡献在于提供了多种嵌入模型、向量数据库和大模型的接口,使得我们可以进行无缝切换。
可以看出,LangChain更侧重于各组件的组合和流程的编排 ,并没有像LlamaIndex那样提供大量的内部附加功能。例如,LlamaIndex的5行代码中包括索引的自动生成,而LangChain则需要手动选择一款向量数据库;LlamaIndex的查询引擎自带提示词以及检索和生成的逻辑,而LangChain则需要用户自己设置提示模板后传递给大模型,还需要手工处理大模型返回的结果 。从这个角度来看,LlamaIndex在文档索引和检索算法方面封装了更多的逻辑,并提供了许多专门的优化 ,关于这一点我们将在第4章和第5章中详细讨论。
使用框架:通过LCEL链进行重构 由于LangChain强调流程编排,因此它在2023年末推出了LCEL(LangChain Expression Language,LangChain表达式语言)。这是一种专为构建和组合大模型应用链设计的声明式编程框架,也是新版LangChain的核心组件。它通过简化的语法和统一接口,支持从简单提示词到复杂多步骤链的高效开发与部署。
开发者使用类似Unix管道操作符(|)的语法,将提示模板、模型调用、输出解析器等组件无缝连接,形成可扩展的生产级应用链。
LCEL的核心特点如下。
■ 代码简洁与复用性:相比传统链式代码(如LLMChain),LCEL通过声明式语法减少冗余代码,且无需修改即可从原型迁移到生产环境。
■ 灵活的组合能力:支持复杂逻辑,如并行执行(RunnableParallel)、动态输入传递(RunnablePassthrough)和条件分支。例如,在RAG链中并行检索多个数据源,合并结果后生成回答。
■ 并行加速:通过RunnableParallel执行独立任务(如多检索器调用),或利用RunnableBatch处理输入数据,将串行延迟优化为并行计算,显著提升吞吐量,适合混合I/O与计算密集型场景。
■ 异步高并发:所有LCEL链原生支持.ainvoke()和.abatch()异步接口,可无缝集成至LangServe等异步框架,单节点轻松应对千级并发请求,避免资源阻塞,实现服务器资源利用最大化。
■ 流式低延迟:通过.stream()接口逐块流式输出结果,并结合底层优化确保首个响应Token在毫秒级返回,用户无需等待完整生成即可实时获取内容,提升长文本场景下的交互体验。
■ 中间结果访问与调试:无缝对接LangSmith(链路追踪与监控)、LangServe(API部署)等工具,实时监控或调试复杂链的执行过程,实现全生命周期管理。例如,在RAG链中,可查看检索到的文档和模型生成的中间回答。
■ 输入输出模式验证:支持基于链结构的Pydantic和JSONSchema模式,确保输入输出的数据类型和格式合规,减少运行时错误。
可以使用LCEL链重构前面的RAG系统。
In
# 加载文档
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths = (''https://zh.wikipedia.org/wiki/黑神话:悟空'',)
)
docs = loader.load()
# 文本分块
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
In
chunk_size = 1000, # 每个文本块的大小(字符数)
chunk_overlap = 200 # 相邻文本块之间的重叠字符数
)
all_splits = text_splitter.split_documents(docs)
# 设置嵌入模型
from langchain_huggingface import HuggingFaceEmbeddings
embed_model = HuggingFaceEmbeddings(model_name=''BAAI/bge-small-zh'')
# 创建向量存储
from langchain_core.vectorstores import InMemoryVectorStore
vectorstore = InMemoryVectorStore(embed_model)
vectorstore.add_documents(all_splits)
# 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={''k'': 3}) # 返回前3个检索结果
# 创建提示模板
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(''''''
基于以下上下文回答问题。如果上下文中没有相关信息,请说
''我无法从提供的上下文中找到相关信息''。
上下文:{context}
问题:{question}
回答:'''''')
# 设置语言模型和输出解析器
from langchain_openai import ChatDeepseek
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
llm = ChatDeepSeek(model=''deepseek-chat'')
# 构建LCEL链
chain = (
{
''context'': retriever | (lambda docs: ''\n\n''.join(doc.page_content for doc in docs)), # 上下文
''question'': RunnablePassthrough() # 查询
}
| prompt # 提示词
| llm # 生成模型
| StrOutputParser() # 输出解析器
)
# 执行查询
question = ''《黑神话:悟空》有哪些游戏场景?"
In
response = chain.invoke(question)
print(response)
这段代码通过vectorstore.as_retriever函数把检索器作为一个组件封装在链中,使得整个流程更加模块化和可组合,而前面的LangChain代码中的vector_store.similarity_search函数则是更底层的直接调用。代码也体现了LCEL在构建处理链时的核心语法特性:首先,通过RunnablePassthrough函数构建包含context和question的字典,动态传递原始文档及查询问题;然后,将这些信息传入提示模板;接下来,由语言模型处理;最后,使用StrOutputParser函数解析输出。LCEL使得代码更加简洁明了,易于开发者理解数据的流向,也方便调试和修改。
关于LCEL是否好用,可能因人而异。对于小型RAG系统,如果没有先前使用LCEL的经验,切换为LCEL并非绝对必要。然而,LCEL确实通过其极简的语法和强大的功能抽象解决了大模型应用开发中的模块化组合、生产部署和实时监控等核心问题。
使用框架:通过LangGraph进行重构 截至本书撰写时,在最新的LangChain文档中,RAG的实现示例通过LangGraph来完成。LangGraph通过将应用程序的工作流程表示为图结构,使开发者能够直观地设计和管理复杂的任务流程。
在LangGraph中,图由节点(node)和边(edge)组成,每个节点代表一个独立的操作或任务,而边则定义了节点间的执行顺序和条件。由于“图”相对来说是较为复杂的数据结构和设计模式,因此使用LangGraph实现RAG系统会比传统的线性处理链更加复杂。然而,这种方法也带来了一些额外的好处。
首先,LangGraph提供了更清晰的状态管理。它使用TypedDict显式定义状态,使得状态的流转更容易理解和维护。其次,LangGraph提供了灵活的流程控制,可以轻松地添加条件分支和循环,支持更复杂的检索-生成模式。然后,LangGraph具有更好的可观察性,支持LangSmith跟踪功能,能够可视化流程图以便调试。最后,LangGraph支持多种运行模式(如同步、异步、流式),便于集成到更大的应用中。
接下来使用LangGraph来完成与前面功能类似的RAG系统。
首先,安装LangGraph包。
其次,设置环境变量以启用LangSmith跟踪功能(需要在LangChain网站上注册LangSmith并申请API Key)。
In
export LANGCHAIN_TRACING_V2 = true
export LANGCHAIN_API_KEY = <你的LangSmith API Key>
前面索引部分保持不变,后续用LangGraph来实现检索和生成的代码如下。
In
# 定义RAG提示词
from langchain import hub
prompt = hub.pull(''rlm/rag-prompt'') # 这里我们换一种方式来构建RAG提示词
# 定义应用状态
from typing import List
from typing_extensions import TypedDict
from langchain_core.documents import Document
class State(TypedDict):
question: str
context: List[Document]
answer: str
# 定义检索步骤
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state[''question''])
return {''context'': retrieved_docs}
# 定义生成步骤
def generate(state: State):
from langchain_openai import ChatDeepSeek
llm = ChatDeepSeek(model=''deepseek-chat'') # 大模型
docs_content = ''\n\n''.join(doc.page_content for doc in state[''context'']) # 上下文
messages = prompt.invoke({''question'': state[''question''], ''context'': docs_content}) # 提示词
response = llm.invoke(messages) # 响应(也就是回答)
return {''answer'': response.content}
# 构建和编译应用
from langgraph.graph import START, StateGraph
graph = (
StateGraph(State) # 图的状态定义,用于管理RAG流程中的状态转换
.add_sequence([retrieve, generate]) # 添加检索和生成两个节点的顺序执行序列
.add_edge(START, ''retrieve'') # 设置图的起始点为检索节点
.compile() # 编译图,使其可执行
)
# 运行查询
question = ''《黑神话:悟空》有哪些游戏场景?"
response = graph.invoke({''question'': question})
print(f''\n问题:{question}'')
print(f''答案:{response['answer']}'')
LangGraph还提供了用于可视化应用程序控制流的内置实用程序。
In
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
运行上述代码,将输出图0-14所示的流程。
图0-14 通过LangGraph构建的检索和生成流程
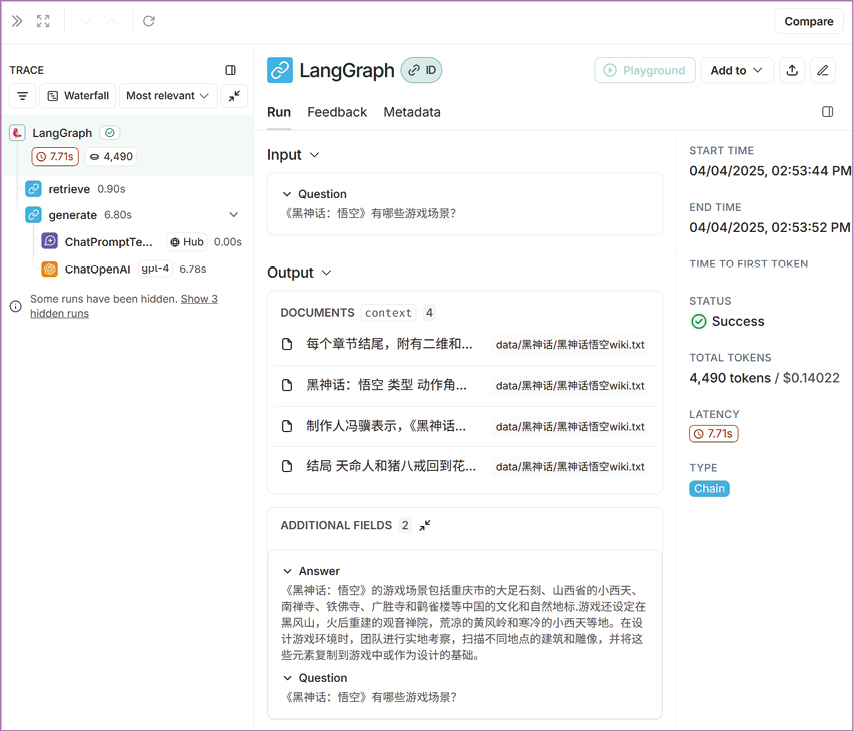
而与大模型交互的细节都被LangSmith所记录(见图0-15)。这也是使用LangGraph和LangChain来实现RAG系统带来的额外好处。
图0-15 LangSmith对RAG流程中与大模型交互的细节进行了清晰的追踪
小冰:咖哥,你讲到这里,我的选择困难症已经犯了。仅LangChain这一个框架,就提供了直接调用模型、LCEL链和LangGraph这3种选择,那我应该怎么选?
咖哥:嗯。LangChain给出了一些指导原则。
■ 如果是单个大模型调用,则不需要LCEL链,直接通过LangChain提供的接口调用底层大模型即可。
■ 如果要实现一个简单的链(例如,包含提示词、大模型、输出解析器以及简单的检索设置等),那么可以选择LCEL链。
■ 如果要构建复杂的链(例如,包含分支、循环、多个代理等),那么可以选用LangGraph。请记住,在LangGraph的各个节点中仍然可以使用LCEL链。
不使用框架:自选嵌入模型、向量数据库和大模型 咖哥:现在我们已经了解了LlamaIndex和LangChain这两个知名大模型框架在搭建RAG系统方面各自的优势。
小冰:什么优势?
小雪:LlamaIndex内部集成了很多索引和检索策略,LangChain/LangGraph则侧重于流程的编排和状态的追踪。尽管这两个框架提供了这么多优势,我们能否不使用这两个框架,从零开始搭建一个RAG系统?
咖哥:当然可以。虽然这种实现方式的代码会多一些,但能让我们更好地理解每个组件的作用,也能根据实际需求进行更灵活的定制。
接下来将使用常用的开源嵌入模型库SentenceTransformers、开源向量数据库Faiss及商业大模型Claude(或国产大模型DeepSeek)来搭建一个RAG系统。
在开始介绍之前,先导入相关的包。
In
pip install sentence-transformers
pip install faiss-cpu # 或者faiss-gpu,视你的操作系统环境而定
pip install anthropic
首先,将游戏相关文档通过一个小型开源向量模型all-MiniLM-L6-v2转换为向量形式,准备将其存入数据库。
In
# 准备文档并进行向量嵌入
docs = [
''《黑神话:悟空》的战斗如同……当金箍棒与妖魔碰撞时……腾挪如蝴蝶戏花。'', # 限于图书篇幅,其他文档略去以保持简洁,余同
''每场BOSS战都是一场惊心动魄的较量……招招险象环生。",
''游戏的音乐如同一首跨越千年的史诗。古琴与管弦交织出战斗的激昂,笛箫与木鱼谱写禅意空灵。而当悟空踏入重要场景时,古风配乐更是让人仿佛穿越回那个神话的年代。"]
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
doc_embeddings = model.encode(docs)
print(f''文档向量维度:{doc_embeddings.shape}'')
其次,准备向量数据库。这里我们选择Faiss来进行索引并存储文档向量,检索过程也将通过Faiss来完成。
In
# 准备向量数据库
import faiss
import numpy as np
dimension = doc_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(doc_embeddings.astype('float32'))
print(f''向量数据库中的文档数量:{index.ntotal}'')
接下来,根据用户提出的问题,再次使用相同的嵌入模型生成问题向量,并检索出与问题相关的文档。
In
# 问题向量生成与相似文档检索
question = ''《黑神话:悟空》的战斗系统有什么特点?''
query_embedding = model.encode([question])[0]
distances, indices = index.search(
np.array([query_embedding]).astype('float32'),
k=3
)
context = [docs[idx] for idx in indices[0]]
print(''\n检索到的相关文档:'')
for i, doc in enumerate(context, 1):
print(f''[{i}] {doc}'')
Out
检索到的相关文档:
[1] 在这个架空的神话世界中,玩家将遇到二郎神、哪吒等。每个角色都有独特的背景故事。
[2] 故事背景设定在大唐以前的妖魔世界,既有传统元素也有新的诠释。
[3] 战斗系统极其硬核,融合中国武术与神话元素,包含各种华丽连招,还能切换不同的战斗姿态。
最后,设计提示词并使用Claude模型根据检索到的上下文生成回答。(此时选择Claude是为了展示生成模型选择的多样化。如果无法获取Claude API Key,可以访问作者的GitHub仓库,使用DeepSeek模型的替代版本的代码。)
In
# 使用Claude生成答案
prompt = f''''''根据以下参考信息回答问题,并给出信息源编号。
如果无法从参考信息中找到答案,请说明无法回答。
参考信息:
{chr(10).join(f''[{i+1}] {doc}'' for i, doc in enumerate(context))}
问题:{question}
答案:''''''
from anthropic import Anthropic
claude = Anthropic(api_key=os.getenv(''ANTHROPIC_API_KEY''))
response = claude.messages.create(
model=''claude-3-5-sonnet-20241022'', # 模型名称来自Anthropic官方文档
messages=[{
''role'': ''user'',
''content'': prompt
}],
max_tokens=1024
)
print(f''\n生成的答案:{response.content[0].text}'')
Out
生成的答案:根据参考信息[3],《黑神话:悟空》的战斗系统具有以下特点。
1. 战斗风格灵活多变,可以在狂猛和灵动两种风格间切换。
2. 武打场面如同武侠小说般生动,招式行云流水。
3. 战斗表现酣畅淋漓,金箍棒与敌人碰撞时火星四溅。
4. 可以施展大开大合的横扫千军,也可以轻盈灵动如蝴蝶戏花。
信息来源:[3]
咖哥:抛弃了LlamaIndex和LangChain之后,RAG系统的构建流程并没有因此变得更加复杂,我认为反而更加清晰了。当然,并非一定要选择使用LlamaIndex和LangChain,除非你确实看中了它们提供的某些附加价值,例如,LlamaIndex中某些对查询进行优化的检索引擎,或是LangSmith提供的追踪功能。
小雪:明白了,咖哥。是否采用框架以及选用哪个框架,应该基于自身项目的需求做出选择。
使用coze、Dify、RAGFlow、FastGPT等工具 随着大模型的爆发,低代码和可视化工具成为快速构建RAG系统的热门技术。比较知名的工具包括coze、Dify、RAGFlow、FastGPT、LangFlow和FlowiseAI等(见图0-16)。这些工具为开发者提供了友好的图形化界面和预定义的模块,降低了复杂度,使得非技术用户也能参与到RAG系统的设计中。
图0-16 低代码和可视化工具
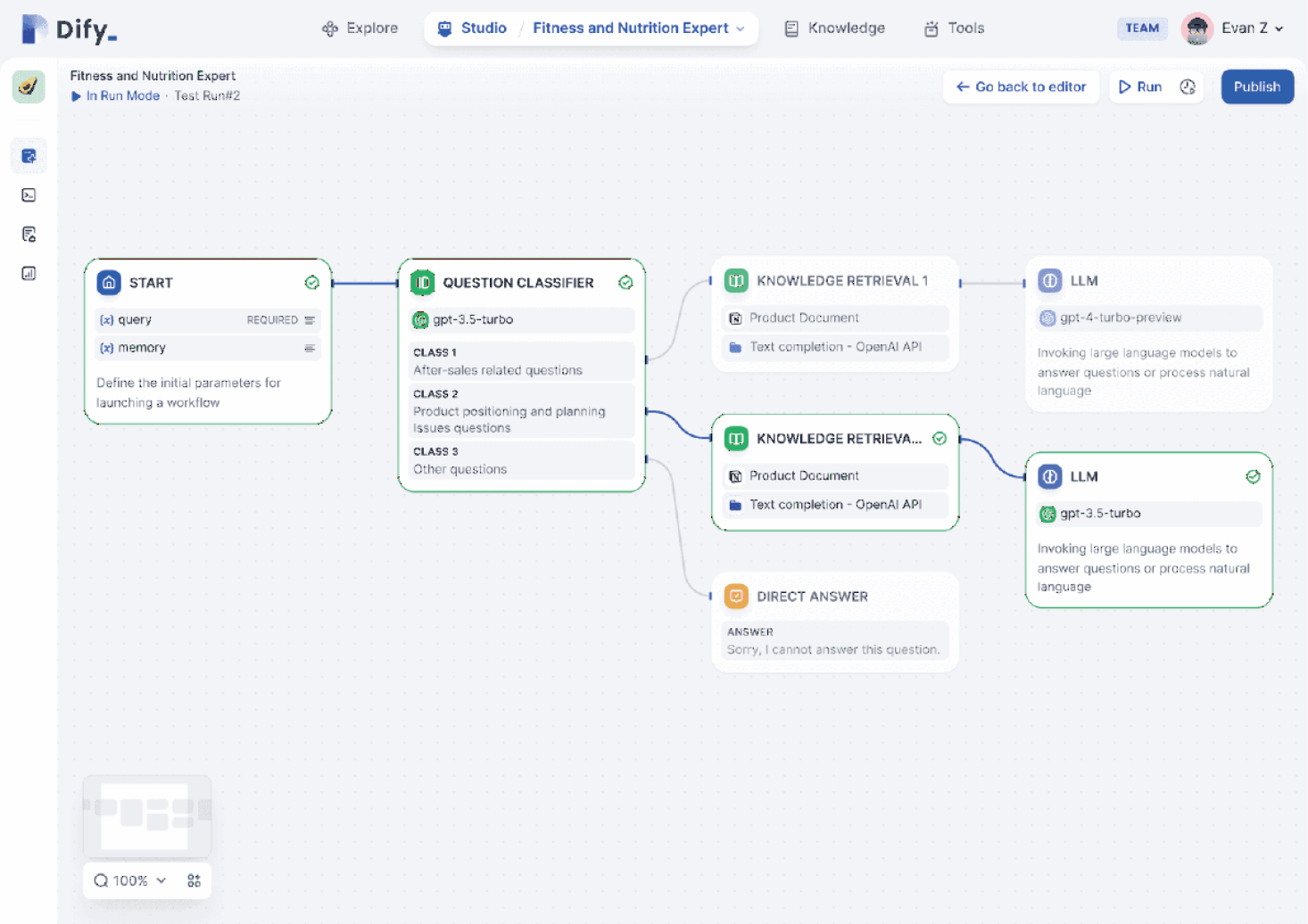
以Dify为例,你可以采用模块化和可视化设计来构建和运行RAG工作流,以便快速理解流程。RAG工作流的设计界面如图0-17所示。
图0-17 RAG工作流的设计界面(图片来源:dify.ai)
图0-17展示的工作流包含输入处理、分类、检索和生成回答等步骤。下面简单介绍下各个模块的作用。
■ START模块接受用户的查询和上下文记忆,定义了工作流的初始输入参数。
■ QUESTION CLASSIFIER模块使用GPT-3.5-turbo模型对问题进行分类。分类结果分为3个类别:售后相关问题、产品定位与规划问题,以及其他问题。
■ 针对当前知识库无法回答的问题(属于第3类问题),在DIRECT ANSWER模块中直接输出“Sorry, I cannot answer this question.”。
■ 针对可以回答的问题,则进入KNOWLEDGE RETRIEVAL模块,根据分类结果选择对应的检索路径,检索产品文档中相关的信息,然后调用大模型的API进行文本生成。
■ LLM模块将根据检索到的文档生成回答,其中,针对不同类型的问题,选择使用不同的大模型来回答。
这一系列低代码工具的特点是其可视化流程清晰易懂,每个模块独立且功能明确,支持条件分支和分类,适用于复杂的检索-生成工作流。当你的RAG或其他AI应用开发完成并发布后,多数低代码工具也会为你的应用提供API,使开发者能够通过这些API调用所生成的AI应用。
低代码工具使RAG系统和AI应用的开发变得更加便捷,但大多数情况下并不涉及RAG组件(如嵌入、索引及检索、生成等)算法级别的优化。想要设计出高质量的RAG系统,仍需要我们对RAG的每个环节进行更细致的探索。因此,本书的重点并不在于低代码工具的使用,而在于如何利用代码以及LangChain、LlamaIndex等框架来优化RAG系统中的每个环节和组件。
三问 从何处入手优化RAG系统 从何处入手优化RAG系统?这个问题更为实际,也更加考验开发经验。优化RAG系统的首要步骤是明确优化的目标与瓶颈。由于RAG系统流程较长,涉及步骤众多,因此,确定影响系统整体性能的关键组件至关重要,也就是需要像侦探一样找出问题所在。
接下来,咖哥将通过两张图片来阐述如何逐步定位出现故障的RAG系统 组件 。
第一张图片来自ABACUS.AI(见图0-18)。该图片不仅展示了RAG系统的结构流程,还简要指出了每个环节中可能存在的优化点。
图0-18 RAG系统的结构流程
根据图0-19,首先从分块策略 入手优化RAG系统。分块策略决定了检索阶段的粒度与上下文的完整性,直接影响后续检索和生成的效果。可以尝试调整分块的大小和重叠程度。例如,增加分块的重叠度能够提升上下文连续性,但同时也会带来存储冗余的问题;而缩小分块的大小能够减少无关信息的引入,但可能会导致语义信息的分裂。
其次,可以优化嵌入策略 。选择一个适合任务的嵌入模型至关重要,目前存在大量的开源模型和商业模型,不同模型在性能和语义捕捉能力上可能存在显著差异。如果你使用的是基于Transformer架构的开源模型,通过微调模型或许能够进一步提升嵌入的语义相关性。此外,考虑使用领域专属的嵌入模型可能会显著提升RAG系统在特定场景下的表现。在优化嵌入策略时,还要注意平衡向量维度大小与计算效率。
接下来是检索器 的优化,主要包括向量数据库的选择,以及索引结构和检索算法的调整。例如,可以从简单的平铺索引逐渐过渡到更高效的IVF或HNSW索引。调整检索的Top K参数和相似度阈值有助于找到更相关的文档片段,同时减少无关内容的引入。此外,动态检索策略(如基于用户问题动态调整检索参数)和一系列索引优化技巧也可能提高检索结果的质量。
然后是上下文生成策略 的优化。在检索到多个相关文档片段后,如何组合这些片段并作为上下文传递给大模型也可能会影响最终生成回答的质量。可以根据语义相关性对检索结果重新排序,可以压缩或者扩充当前检索结果,或者在片段之间加入解释性连接词。此外,上下文的长度需要根据所使用的大模型的最大token数限制进行调整,以充分利用模型的能力而不过载。
大模型的选择 和提示词的设计 也是关键的优化方向。应选择更适合特定任务的模型,并调整生成参数(如温度、Top-p和最大token数)。提示词的设计可以引导模型生成更符合用户需求的回答,例如提供明确的指令或补充上下文信息。
优化的最终步骤是对响应 (即生成的最终回答)的评估 。在生成回答后,可使用标准的自动化评价指标(如BLEU、ROUGE、BERT等),以及与人工评估相结合,来比较不同优化组合下系统的表现。通过实验和评价不断迭代,你可以逐渐找到最优的系统配置,从而提升整个RAG系统的效率和准确性。
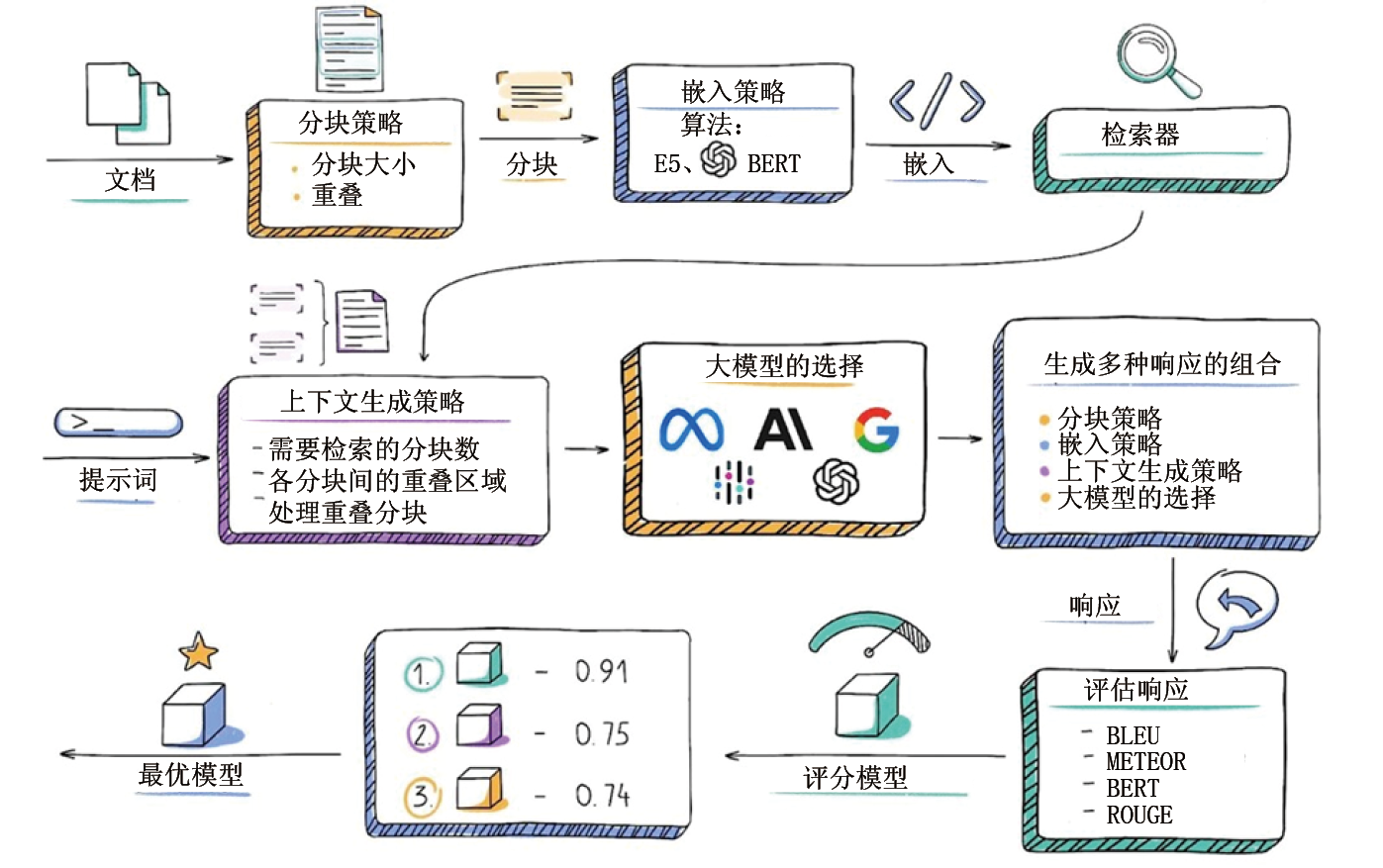
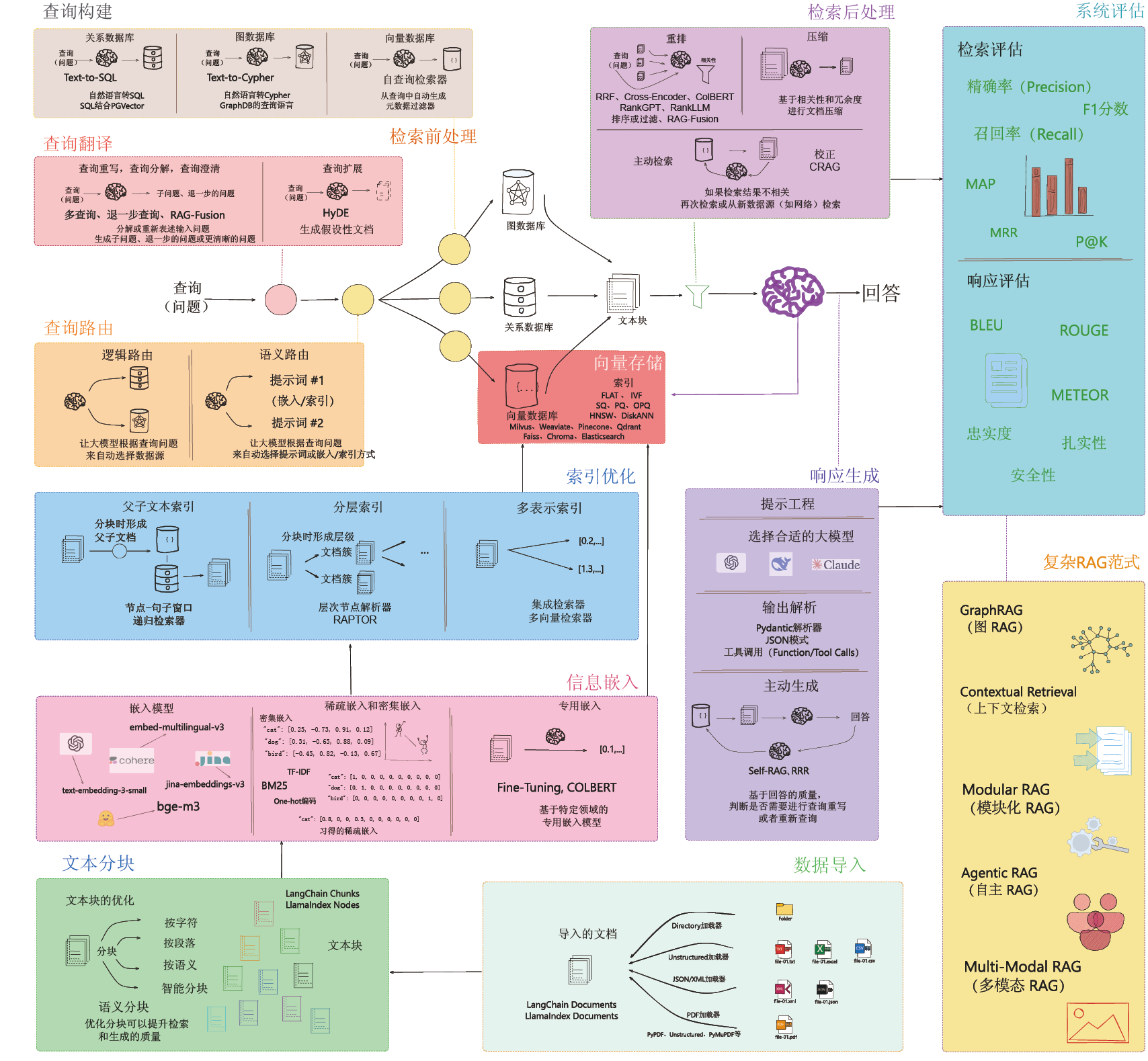
第二张图片则是咖哥基于LangChain的RAG流程图进行增补和重新设计的成果(见图0-19),旨在详尽描述每一个可优化的RAG技术环节。鉴于RAG系统的不断发展,咖哥对整个RAG流程进行了重构,将其划分为十大核心组件(或称环节),以期在技术路径上实现更全面的覆盖。
图0-19清晰地呈现了RAG系统中每个环节的可优化点,从数据导入、文本分块到查询构建,直至响应生成与系统评估,每一步都可通过新技术和设计思路得到改进,每个模块均具备明确的技术路径。基于模块化思维的设计不仅为后续技术迭代提供了极大的灵活性,也为新功能扩展创造了可能。
在接下来的章节中,我们将依据色块分区对各环节点评解析,探讨其技术细节及优化方向。这张精心设计的图片将成为咖哥整个RAG课程的指导性总纲。
现在就让我们正式开始!
图0-19 基于LangChain的RAG流程图的增强版