
详情
本书是一本介绍算法和数据结构基础知识的入门读物。作者通过简单易懂的语言和示例,帮助读者建立坚实的算法和数据结构基础,提高编程技能和解决问题的能力。本
书包含两部分内容。第Ⅰ部分主要介绍什么是算法、递归、搜索算法、排序算法、字符串算法、数学等方面的知识。第Ⅱ部分主要介绍数据结构相关知识,如什么是数据结构、数组、链表、栈、队列、哈希表、二叉树、二叉堆、图等方面的知识。本书提供了大量的练习题和示例代码,帮助读者巩固所学知识并提高编程能力。

书名:数据结构和算法无师自通
ISBN:978-7-115-62455-0
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
著 [美]科里·奥尔索夫(Cory Althoff)
译 张云翼
责任编辑 郭泳泽
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线:(010)81055410
反盗版热线:(010)81055315
The Self-Taught Computer Scientist: The Beginner’s Guide to Data Structures & Algorithms
978-1-119-72441-4
Copyright© 2021 by Cory Althoff
Published by arrangement with Hodgman Literary LLC, through The Grayhawk Agency Ltd.
本书中文简体字版由Hodgman Literary LLC授权人民邮电出版社独家出版。未经出版者书面许可,不得以任何方式复制或抄袭本书内容。
版权所有,侵权必究。
本书是一本介绍算法和数据结构基础知识的入门读物。作者通过简单易懂的语言和示例,帮助读者建立坚实的算法和数据结构基础,提高编程技能和解决问题的能力。本书包含两部分内容。第Ⅰ部分主要介绍什么是算法、递归、搜索算法、排序算法、字符串算法、数学等方面的知识。第Ⅱ部分主要介绍数据结构相关知识,如什么是数据结构、数组、链表、栈、队列、哈希表、二叉树、二叉堆、图等方面的知识。本书提供了大量的练习题和示例代码,帮助读者巩固所学知识并提高编程能力。
本书适合了解Python基础、对计算机科学感兴趣或有相关求职意向的人阅读。
谨以此书献给我的妻子Bobbi和我的女儿Luca。我爱你们!
科里·奥尔索夫(Cory Althoff),作家、程序员、演讲家。他的第一本图书《Python编程无师自通》已以7种语言出版,并将“编程无师自通”这一短语引入大众视野。美国图书管理局将《Python编程无师自通》评为“有史以来优秀的编程书籍”之一,科技博客The Next Web将其列为助力成为更优秀的软件工程师的十本书之一。他通过Facebook群组、博客、专栏、Udemy课程建立了编程无师自通社区,已有逾20万名开发者加入。科里与他的妻子和女儿住在加利福尼亚州。
Hannu Parviainen博士是加那利群岛天文研究所的天体物理学家,负责研究太阳系外行星,该研究所是世界领先的天体物理研究所之一,拥有迄今最大的光学望远镜。此前,他曾在牛津大学做博士后研究员数年,主要研究方向包括科学计算和现代数值方法,并在Python编程语言方面拥有20多年的经验。
我要向所有帮助我完成本书的人表达衷心的感谢。首先是我的妻子Bobbi,她是我一生的挚爱,一直支持着我。我要感谢我的父亲James Althoff,他花了很多时间帮助我完成这本书。还有Steve Bush,非常感谢您阅读我的书并给予反馈。我要感谢项目编辑Robyn Alvarez和技术编辑Hannu Parviainen;感谢编辑Devon Lewis,是他促成了这个项目。最后,我要感谢我的女儿Luca,她是世界上最好的女儿,是她激励我努力工作。我爱你,Luca!没有你们所有人的支持,我不可能完成这本书。非常感谢!
在大学毕业并取得政治学学位后,我才开始编程之旅。离开学校后,我找工作的过程十分艰难。我并不具备雇主们所需要的技能,只能眼睁睁地看着学习更实用学科的朋友们不断找到高薪的工作。而我却一直没有找到工作,赚不到钱,感觉自己很失败。我住在硅谷,周围都是程序员,所以我决定尝试学习编程。我没想到这即将开启我生命中最疯狂、最充实的旅程。
这并不是我第一次学习编程,我曾经尝试过,但并未成功。大一的时候我上过一门编程课,但由于无法理解很快就退掉了这门课程。很遗憾,多数学校都把Java作为教授给学生的第一门编程语言,这对于初学者而言很难理解。我决定自学Python而不是Java,因为Python对于初学者来说更容易学习。但即使是这样一种容易理解的语言,我也险些放弃。我需要从许多不同的来源拼凑信息,这很令人沮丧。我觉得自己形单影只,非常无助。我并没有能够一起学习、相互依靠的学习伙伴。
在我近乎放弃的时候,我开始关注Stack Overflow等在线编程社区。加入社区让我充满动力,我又重拾信心。学习过程颇为坎坷,我也曾想过放弃。而就在做出学习编程这一重大决定后的一年内,我就在eBay担任软件工程师了。一年以前,在客户中心找到一份工作都很困难。而现在,我能为一家知名的科技公司编写程序,每小时能得到50美元的工资。我简直不敢相信!不过,最棒的并不是钱,而是在成为软件工程师之后,我的信心倍增。学习编程后,我觉得我可以完成任何事情。
从eBay离职之后,我开始在帕罗奥托的一家初创公司工作。最终,我决定暂时休假去东南亚背包旅行。天下着雨,在巴厘岛塞米亚克狭窄的街道,我坐在出租车的后座上,突然有了一个想法。在美国,人们都很关心我成为一名软件工程师的经历。硅谷有很多软件工程师,但我与同行们有所不同,因为我没有计算机科学学位。
我的想法是编写一本名为《Python编程无师自通》的书,不仅关于编程,还包括我成为一名软件工程师所学到的一切。换言之,我希望帮助人们走上和我一样的道路。因此,我开始着手为想要自学成为程序员的人们规划一个路线图。我花了一年时间编写了我的第一本书《Python编程无师自通》并自费出版。我不知道会不会有人阅读,可能没有人会读,但我还是想分享我的经验。令我惊讶的是,这本书出版后的几个月就售出数千本。随着书的销售,全世界自学成才的程序员和正在自学的程序员给我发来了很多信息。
这些信息让我备受鼓舞,因此我决定试着解决另一个我在学习编程时遇到的问题:在路上感觉形单影只。我的方案是建立一个称为Self-Taught Programmers的Facebook社群,让程序员可以互相支持。现在这个社群已有6000多位成员,并发展成自学编程者互相帮助、共享知识、分享成功故事的鼓励性群组。如果你也想加入社群,可以访问Facebook,也可以通过The Self Taught Programmer网站订阅我的专栏。
以前,我将自己没有计算机科学学位而从事软件工程师工作的故事发布到网上时,总会收到一些负面评论,他们说没有学位就不可能成为一名程序员。有些人大呼:“你们这些自学成才的程序员以为自己在干什么?你需要学位!不然没有公司会看上你们!”但最近,这些评论少之又少。再遇到这些评论时,我会让他们看看我的社群。在那里,自学成才的程序员在世界各地的公司担任着各种职级的软件工程师。
与此同时,我的书一直很畅销,我成功将其转换成了一门受欢迎的Udemy课程,这超出了我的想象。与这么多优秀的人交流编程学习是一种美妙又令我受宠若惊的经历。我非常高兴能用这本书继续我的旅程。本书是《Python编程无师自通》的续作,如果你还没有读过前一本书,你应该去读一读,除非你已经了解编程的基础知识。本书假设你可以用Python进行编程。如果你还不能做到这一点,请先阅读我的第一本书,或参加我的Udemy课程。总之,请用任何最适合你的资源学习Python。
我的第一本书《Python编程无师自通》介绍了编程和学习编程所需要的专业技能,而本书是对计算机科学的介绍,更具体地说,是对数据结构与算法的介绍。计算机科学是研究计算机及其工作原理的学科。如果你进入大学,想成为软件工程师,那么你的专业不是编程,而是计算机科学。计算机科学专业的学生会学习数学、计算机体系结构、编译原理、操作系统、数据结构与算法、网络编程等课程。
每一个话题都可以成为一部大部头著作的主题,全面介绍已远远超出了本书的范围。计算机科学是一个庞大的学科,你倾尽一生也无法学完。本书并不会介绍在学校取得计算机科学学位要学的所有知识。我的目标是介绍计算机科学中的一些核心概念,以便你作为自学程序员而在几个不同的方面变得突出。
想要自学编程,最重要的两个主题就是数据结构与算法,这也是本书聚焦于这两点的原因。我将本书分为两部分。第Ⅰ部分是对算法的介绍,你会学到什么是算法,什么因素使得一种算法优于另一种算法,你也会学到线性搜索、二分搜索等不同的算法。第Ⅱ部分是对数据结构的介绍,你会学到什么是数据结构,并学习数组、链表、栈、队列、哈希表、二叉树、二叉堆和图。然后,我会总结在读完本书之后你应该做什么,包括后续步骤和其他资源,助你踏上编程的旅途。
在我的上一本书中,我解释了在学习编程之前学习计算机科学是没有意义的。但这并不意味着你可以忽视它,要想成为一名成功的程序员,就必须学习计算机科学。道理很简单:如果你不懂计算机科学,你就很难找到工作。几乎所有招聘程序员的公司都将技术面试作为招聘的一个环节,而技术面试几乎只聚焦于一个主题:计算机科学。更具体地说,就是数据结构与算法。要想进入Facebook、谷歌、爱彼迎等当今热门的公司,你都需要通过聚焦于数据结构与算法的技术面试。如果不具备这两个学科的深度知识,你将在技术面试中被对手“碾压”。技术面试是绕不过去的,你的面试官会问出关于数据结构与算法的细节问题。要想找到工作,你最好知道答案。
此外,当你找到第一份工作之后,你的领导和同事也会期待你了解计算机科学的基础知识。他们如果还需要向你解释为什么复杂度为O(n3)算法并非很好的解决方案,就不会喜欢你。这就是我在eBay的第一份工作中遇到的事情。我团队的成员都是来自斯坦福大学、伯克利大学、加州理工大学的优秀程序员,他们都对计算机科学有很深入的理解,而我则感到不安、难以融入。作为一名自学程序员,学习计算机科学可以帮助你避免这种命运。
另外,学习数据结构与算法也会让你成为一名更优秀的程序员。反馈循环是掌握一项技能的钥匙。所谓反馈循环是指你在练习一项技能时,能立即获得有关自己做得如何的反馈。在练习编程时,并没有反馈循环。例如,你在创建网站时,这个网站可能可以运行,但代码却非常糟糕,并没有反馈机制告诉你代码写得怎么样。但若你学习了算法就不一样了,有许多著名的计算机科学算法用于编写代码并解决问题。把自己的结果与现有算法进行对比,就能立刻得知自己是否写出了一个可接受的解决方案。利用正向反馈循环进行练习,可以提升你的编程技能。
作为一名试图进入软件行业的自学程序员,我犯的最大错误就是没有花足够的时间学习数据结构与算法。如果我学得更多,我的旅程就会变得更加可控。我希望你不要犯同样的错误。
我已经说过,计算机科学是一个庞大的学科,这也是为什么计算机科学专业的学生需要整整4年的时间来学习它:要学的东西太多了。你可能没有4年的时间去学习计算机科学,幸运的是,你也不需要。本书涵盖了作为软件工程师的成功职业生涯中的最重要的内容。阅读本书并不能替代4年制计算机科学专业学位,但阅读本书并结合示例进行练习,可以为你通过技术面试打下良好的基础,让你能够与来自计算机科学专业的团队顺利地合作。作为一名程序员,你也会有显著的提升。
我已经向你证明自学也可以成为专业的程序员,你需要学习计算机科学,尤其是数据科学与算法。但是只有在校外学习编程的人才能阅读这本书吗?当然不是!我们欢迎所有人加入自学社群!我的第一本书在大学生中出奇地受欢迎。一些大学教授甚至与我联系,告诉我他们在编程课堂上使用了我的书。
学习计算机科学的大学生常常问我他们应不应该退学。我的目标是激励尽可能多的人学习编程,因此我想让人们知道,没有计算机科学学位也能开始程序员的职业生涯。而如果你已经在学校学习计算机科学,这也很好,你不应该退学。留在学校吧!即使在学校,你也可以成为我们自学社群的一员,只要你将我们“持续学习”的思想应用在学校的学习中,并且在教授教给你们的东西之外继续学习。
怎么判断自己是否可以开始学习计算机科学了呢?很简单。只要会编程,就可以开始。本书面向任何想要学习计算机科学的人。无论你想填补自己的知识空白,准备技术面试,想提升工作技能,还是想成为一名更优秀的程序员,这本书都是为你准备的。
我没有对口专业的学位也找到了软件工程师的工作,最近我每天都能听到自学程序员的成功故事。作为一名自学程序员,即使没有学位,你也完全可以成为一名成功的软件工程师。我知道这可能是一些人的痛点,因此在我们开始学习计算机科学之前,我想分享一些Facebook群组中的自学程序员的成功故事。
Matt Munson是Facebook自学程序员群组的一员,以下是他的自述。
一切要从我从FinTech离职说起。为了维持生计,我开始打零工:磨眼镜的镜片、修理车辆、管理游乐场,也做过一些小型编程项目。但尽管如此,几个月后,我还是失去了自己的房子。这是一个无家可归的人如何成为程序员的故事。
失业后,我回到了校园。因为我失去了房子,所以只能在车里和帐篷里做作业,这持续了几个月的时间。我的家人也无法帮助我,他们不能理解最低工资远远无法让一个人有所食、有所居。尽管如此,我也不想向朋友求助。9 月,我卖掉了我的卡车,拿上所有的现金,到距离我的家乡蒙大拿州的海伦娜1800多英里[1]外的得克萨斯州的奥斯汀寻找机会。
[1]1800英里约合2900千米。
在一周之内,我参加了两三场面试,但没有一家公司愿意把机会给一个没有技能的流浪汉。几个月后,一些朋友和陌生人在GoFundMe上给我捐款,让我能够生存下去。那个时候,我每天只能吃一顿饭,完全吃不好。我只有成为一名程序员才能逃离这种处境。
最后,我决定再给自己一次机会,我投出大量简历,即使是能力远远达不到的工作。第二天一家小型初创公司让我参加面试。我刮了胡子,穿上了干净的衣服,把头发梳起来,洗了个澡(对于流浪汉而言非常困难),尽量让自己看起来体面。我在面试中解释了自己的处境,以及为什么我要来到奥斯汀,我尽自己所能在面试中表现,即使我并不是最好的候选人,但只要给我机会,我会证明自己一定能成为最好的那位。
我觉得我面试时表现得一团糟,自己的诚实可能毁掉了这次机会。但一个星期以后,在我已经完全放弃之时,这家公司打电话让我参与第二次面试。
面试的时候我感到非常吃惊。老板说他被我的诚实所打动,他愿意给我一次机会。他说我的基础还可以,我就像一个箱子:看起来很稳,但基本什么都没装。他认为我足够顽强到处理他扔给我的所有工作,我可以从中学习。最终他告诉我,我将在12月6日入职。
一年之后,我住在一个比成为程序员之前好得多的公寓中。我受到了同事的尊敬,他们甚至会就公司重大事务征求我的意见。你可以做任何事,成为任何人。不要害怕尝试,即使要冒着失去一切的风险。
Tianni Myers阅读了《Python编程无师自通》这本书,并发邮件告诉了我他在学校外开启编程学习之旅的故事。
我在大学学习传媒专业,我的编程之旅始于一门网页设计课程。当时,我爱好写作,希望找到一份市场营销的工作。但在开始学习编程之后,我的目标变了。我想分享我的自学故事,讲述我如何在12个月内从一个零售收银员变成一个初级网页程序员。
我开始在Code Academy上学习HTML和CSS基础知识。我编写的第一个Python程序是数字游戏:计算机随机选择一个数,用户有3次机会猜中这个数。这个项目和Python语言让我对计算机倍感兴趣。
我的早晨从凌晨4点的一杯咖啡开启。我每天花6~10个小时阅读编程书籍和编写代码。那时我21岁,在Goodwill做兼职来维持生计。那是我最开心的时候,因为我每天的大部分时间都在做我热爱的事情,让许多编程语言成为了我的工具。
有一天,我在Indeed网站上随意地申请工作,并没有期望能够得到回应,但几天后一家营销中介联系了我。我在Indeed上做了一份SQL测试,一次电话面试,一次编程测试,后来就是现场面试。在面试中,网页开发主管和两位高级程序员审查了我代码测试的答案。他们对我的一些答案感到满意,也很惊讶得知我是自学成才的。他们告诉我,我的一些答案比一些高级程序员过去给出的答案还要好。两周之后,他们录用了我。
你如果能克服困难,全心投入,也能像我一样梦想成真。
本书的代码示例均用Python编写而成。之所以选择Python,是因为它容易阅读。全书的代码示例都像这样排版:
for i in range(100):
print("Hello, World!")
>> Hello, World!
>> Hello, World!
>> Hello, World!>>后面的文字表示Python交互式界面的输出。如果示例后面没有>>,则表示这个程序没有任何输出,或者我只是在介绍某个概念,输出并不重要。正文中的等宽字体表示某种形式的代码、代码输出或者编程术语。
要运行书中的示例程序,需要安装Python 3。可以从Python官网下载运行于Windows或UNIX的Python。如果使用Ubuntu,则Python 3默认已安装。注意要下载Python 3,而不是Python 2,本书的一些示例并不能在Python 2环境下运行。
Python有32位和64位两个版本。如果你的计算机是2007年之后购买的,那么它更有可能是64位的。如果不确定,可以上网搜索一下。
如果使用Windows或Mac操作系统,则下载32位或64位的Python,打开文件,按说明操作即可。也可以访问The Self Taught Programmer网站,观看在不同操作系统中安装Python的视频教程。
如果你在安装Python时遇到了问题,在任何在线求助网站发布消息时,确保你将代码放在了GitHub Gist(代码片段管理服务)中。不要发送代码的截图。当别人帮助你时,他们常常需要自己运行一下,如果你发送了一张截图,他们就要手工输入你的所有代码。而如果你把代码上传到GitHub Gist中,他们就可以快速复制并粘贴到集成编程环境中了。
本书的很多章节末尾都设有需要你动脑的编程挑战题。这些挑战题是为了检验你对所学内容的理解,让你成为更优秀的程序员,帮助你为技术面试做好准备。你可以在GitHub的库中找到这些挑战题的答案。
当你在阅读本书、解答挑战题时,我鼓励你使用#selftaughtcoder话题,在Twitter[2]自学社区中分享自己的收获。当你觉得你在编程之旅上取得了令人兴奋的进步时,也请使用#selftaughtcoder话题发送推文,让社区中的其他人能因你的进步而感到鼓舞。也请经常@我:@coryalthoff。
[2]后改名为X。——译者注
在开始计算机科学的学习之前,我还想说最后一件事。如果你开始阅读本书,表示你已经在自学编程。你应该知道,学习一个新技能,例如编程,最困难的并不是它本身,而是坚持下去。坚持学习新事物让我挣扎了数年之久,直到我发现了一个技巧,我想分享给你,那就是“不要打破习惯的链条”。
脱口秀演员杰瑞·宋飞发明了“不要打破习惯的链条”方法,他是在构思第一个脱口秀表演时想出的这种方法。首先,他在房间中挂了一张日历,然后如果他某天写了一个笑话,就在当天的日历上打一个红叉(我更喜欢绿色的对勾)。这就是这个技巧的全部了,事实上这非常有效。
当你开始一个习惯链条(几个连续的绿色对勾),你就不想打破它了。两个连续的绿色对勾会变成5个,然后变成10个、20个。连续的对勾越多,你就越不想打破这个链条。想象一下到了月底,看着自己的日历,你有29个绿色的对勾,只差一天就能成为完美的一个月了,你不可能不想完成当天的任务。杰瑞·宋飞这样说道:
几天之后,你就有了一个链条。坚持下去,链条会越来越长。你会变得喜欢看到这个链条,尤其是几周之后。你唯一要做的就是不要打破这个习惯的链条。
为了保持链条,我做了很多疯狂的事情,例如半夜去健身房锻炼,只为了保持下去。回顾日历的第一个满是绿色对勾的完美月份,没有什么比这感觉更棒的了。如果你想偷懒,回顾一下那一页,想一想当时是如何坚持下来的。
技术类书籍很难读完,我已经数不清在读书这件事上有多少次半途而废了。我尽可能让这本书变得有趣易读,但为了给你多一份保险,试着利用“不要打破习惯的链条”方法确保自己看完这本书。我也与Monday网站合作,创建了免费的自学程序员模板,你可以下载App记录自己的编程连胜纪录。你可以访问Monday网站进行尝试。
说了这么多,准备好学习计算机科学了吗?
让我们开始吧!

本书提供如下资源:
• 配套代码;
• 本书思维导图;
• 异步社区7天VIP会员。
要获得以上资源,您可以扫描右侧二维码,根据指引领取。
作者、译者和编辑尽最大努力来确保书中内容的准确性,但难免会存在疏漏。欢迎您将发现的问题反馈给我们,帮助我们提升图书的质量。
当您发现错误时,请登录异步社区(https://www.epubit.com),按书名搜索,进入本书页面,点击“发表勘误”,输入勘误信息,点击“提交勘误”按钮即可(见下图)。我们会对您提交的勘误信息进行审核,确认并接受后,您将获赠异步社区的100积分。积分可用于在异步社区兑换优惠券、样书或奖品。
我们的联系邮箱是contact@epubit.com.cn。
如果您对本书有任何疑问或建议,请您发邮件给我们,并请在邮件标题中注明本书书名,以便我们更高效地做出反馈。
如果您有兴趣出版图书、录制教学视频,或者参与图书翻译、技术审校等工作,可以发邮件给我们。
如果您所在的学校、培训机构或企业,想批量购买本书或异步社区出版的其他图书,也可以发邮件给我们。
如果您在网上发现有针对异步社区出品图书的各种形式的盗版行为,包括对图书全部或部分内容的非授权传播,请您将怀疑有侵权行为的链接通过邮件发送给我们。您的这一举动是对作者权益的保护,也是我们持续为您提供有价值的内容的动力之源。
“异步社区”是由人民邮电出版社创办的IT专业图书社区,于2015年8月上线运营,致力于优质内容的出版和分享,为读者提供高品质的学习内容,为作译者提供专业的出版服务,实现作译者与读者在线交流互动,以及传统出版与数字出版的融合发展。
“异步图书”是异步社区策划出版的精品IT图书的品牌,依托于人民邮电出版社在计算机图书领域30余年的发展与积淀。异步图书面向IT行业以及各行业使用IT的用户。
本部分内容
■ 第1章 什么是算法
■ 第2章 递归
■ 第3章 搜索算法
■ 第4章 排序算法
■ 第5章 字符串算法
■ 第6章 数学
■ 第7章 自学的激励:玛格丽特·汉密尔顿
无论你是想解开宇宙的秘密,还是只想在21世纪谋求一份事业,基本的计算机编程都是一项必须学习的技能。
——史蒂芬·霍金
所谓算法,是指解决某一问题的一系列步骤。例如,炒鸡蛋的算法是将鸡蛋打到碗里、打散、放入锅中、在炉灶上加热、搅拌、凝固后倒出来。本书的第Ⅰ部分介绍的就是算法,你将学习解决问题(例如,寻找质数)所需的算法,也将学习如何书写新颖、优雅的算法,以及如何对数据进行搜索和排序。
在本章中,你将学习如何比较两种算法,以帮助你分析它们。对程序员来说,理解为什么一种算法优于另一种算法非常重要,因为程序员的主要工作就是编写算法并决定使用何种数据结构。如果你不知道为什么应该选择一种算法而不是另一种,你就不会成为一个高效的程序员。因此本章非常重要。
虽然算法是计算机科学的核心概念,但计算机科学家并没有对其正式定义达成一致意见。关于其定义有许多说法,高德纳(Donald Knuth)的定义是最为人知的。他将算法描述为接受输入并据此产生输出的确定、有效、有限的过程。
确定意味着这些步骤都是清晰、简洁、不模糊的。
有效意味着每个操作都能准确地执行,并最终解决问题。
有限意味着算法在有限的步数后就可以结束。
对这一定义的一个常见补充是正确性,也就是说,一个算法应该总是对给定的输入产生相同的输出,而且这个输出应该是算法所解决的问题的正确答案。
绝大多数算法都能满足这些要求,但也有一些重要的例外。例如,当你创建一个随机数生成器时,你的目标就是产生无法利用输入猜测输出的随机数。另外,有许多数据科学算法并不严格要求正确性。例如,算法给出近似输出就已经够用了,只要这个近似的不确定度是已知的。但在大多数情况下,你的算法还是应该满足前面所说的要求。如果你编写一个炒鸡蛋的算法,却偶尔会得到荷包蛋或水煮蛋,你的用户不会满意。
解决一个问题常常有不止一种算法。例如,将列表排序就有很多方法。如果多种算法都能解决同一个问题,那么如何知道哪一种是最好的(最简单的、最快的、最短的或其他标准的)呢?
评判算法的一个标准是运行时间。算法的运行时间是指计算机执行用Python等编程语言编写的算法所需要的总时间。例如,以下是用Python编写的输出数字1~5的算法:
for i in range(1, 6):
print(i)你可以用Python内置的time模块来测量算法的运行时间,以跟踪计算机执行它所需的时间。
import time
start = time.time()
for i in range(1, 6):
print(i)
end = time.time()
print(end – start)
>> 1
>> 2
>> 3
>> 4
>> 5
>> 0.15141820907592773运行这一程序,它将输出数字1~5,并输出执行所需的时间。在本例中,用时0.15秒。
下面,再运行一次这个程序:
import time
start = time.time()
for i in range(1, 6):
print(i)
end = time.time()
print(end – start)
>> 1
>> 2
>> 3
>> 4
>> 5
>> 0.14856505393981934第二次运行时,你应该会看到不同的运行时间。如果再运行一次,运行时间又会不同。算法的运行时间一直在变化,因为每次运行程序时,计算机可用的算力不同,这会影响程序的运行时间。
另外,在不同的计算机上,程序运行时间也会不同。用算力更弱的计算机运行程序,速度会更慢;用算力更强的计算机运行程序,速度会更快。此外,程序运行的时间还受到编程语言的影响。例如,如果用C语言编写同样的程序,运行速度通常会更快,因为C语言比Python语言更快。
由于算法的运行时间受到众多因素的影响,例如计算机的算力、编程语言等,运行时间通常不是比较两种算法的最好标准。相反,计算机科学家会根据算法所需的步数来比较算法。你可以将算法所需的步数代入表达式,这样就可以在不考虑编程语言或计算机性能的情况下比较多种算法了。让我们看一个例子,这是之前从1数到5的程序:
for i in range(1, 6):
print(i)该程序需要5步(循环体执行5次,每次输出i)。你可以用下列表达式表示算法需要的步数:
f(n) = 5
如果让程序变得更复杂一些,则表达式也会变化。例如,你可能想在每次输出数字的时候,记录已输出的数字之和:
count = 0
for i in range(1, 6):
print(i)
count += i现在,你的算法需要11步。首先,将变量count赋值为0;然后,输出5个数字,并进行5次累加(1+5+5=11)。
下面是算法的新表达式。
f(n) =11
如果将代码中的6改成一个变量会怎样呢?
count = 0
for i in range(1, n):
print(i)
count += i表达式会变成这样:
f(n) = 1+2n
现在,算法的步数取决于n的值。表达式中的1表示第一步:count = 0。在此之后,需要2n步。例如,若n为5,则f (n)=1+2×5。 计算机科学家将描述算法所需步数的表达式中的变量n称为问题规模。在本例中,你可以说对于规模为n的问题,需要的时间为1+2n,用数学记号表示为T (n)=1+2n。
但是描述算法步数的表达式并不是很有用,因为你无法总是可靠地数出算法需要多少步。例如,如果一个算法包含了许多条件语句,你就无法预先知道哪些语句会被执行。但好消息是,作为一名计算机科学家,你并不需要关心算法的精确步数。你想要知道的只是当n变大时,算法的表现如何。大多数算法在小数据集上表现得很好,而在大数据集上会变成灾难。即使是最低效的算法,当n等于1时也能表现得很好。然而在真实世界中,n不太可能是1,而有可能是成千上万,甚至上亿。
要了解一个算法,重要的不是步骤的精确数量,而是当n变大时的数量估计。当n变得很大时,表达式的一部分会掩盖其他部分,使这些部分变得无关紧要。例如,请看下面的Python代码:
def print_it(n):
# 第一个循环
for i in range(n):
print(i)
# 第二个循环
for i in range(n):
print(i)
for j in range(n):
print(j)
for h in range(n):
print(h)在确定算法需要的步数时,程序的哪个部分更加重要呢?你可能会认为每个部分(即第一个循环和第二个嵌套的循环)都很重要,毕竟当n达到10 000时,计算机在每个循环都会输出很多数字。
但事实上,在谈论算法的效率时,下面的代码是无关紧要的:
# 第一个循环
for i in range(n):
print(i)要理解其中的原因,你需要看一看当n变得很大时会发生什么。
下面是算法步数的表达式:
T(n) = n + n**3
如果你有两层嵌套的for循环,各需要n步,则一共需要n**2(n的平方)步。因为如果n等于10,就需要进行10次10步,即10**2步。同理,对于三层嵌套的for循环,就需要n**3步。在此表达式中,若n等于10,则第一个循环需要10步,第二个循环需要103步,即1000步。而当n等于1000时,第一个循环需要1000步,第二个循环需要10003步,即10亿步。
明白了吗?当n变大时,算法的第二部分增长得快得多,第一部分就变得不重要了。例如,如果需要将这个程序用于含100 000 000条记录的数据库,你就完全不需要关心表达式的第一部分了,因为第二部分的步数大得多。对于100 000 000条记录,第二部分的步数是10的24次方,即1后面有24个零,因此这个算法无法使用。而第一部分的100 000 000步则与决策无关。
因为算法的重要部分是当n变大时增长最快的部分,所以计算机科学家使用大O记号表示算法的效率,而不是T (n)表达式。大O记号是一种数学记号,描述了当n的规模增长时,算法的时间或空间需求如何增长(稍后会介绍空间需求相关知识)。
计算机科学家使用大O记号创建了T (n)的数量级函数。数量级是一种分类方法,每一类都比其他类大得多。在数量级函数中,你只关心T (n)中最重要的一项,忽略其他因素。T (n)中最重要的一项就是算法的数量级。下面是大O记号中最常用的数量级,从优(最高效)到劣(最低效)排列:
常数时间
对数时间
线性时间
对数线性时间
平方时间
立方时间
指数时间
每种数量级都描述了一种算法的时间复杂度。时间复杂度是指当n变大时,算法所需的最大步数。
让我们来看一看每种数量级。
最高效的数量级称为常数时间复杂度。无论问题的规模如何,常数时间复杂度算法都需要相同的步数。常数时间复杂度用大O记号记为O(1)。
假设你开了一家网上书店,会向每天光临的第一位顾客赠出一本书。你将顾客存储在名为customers的列表中,算法可能会像这样:
free_books = customers[0]
T (n)表达式为
T(n)=1
无论你有多少顾客,算法都只需要1步。如果顾客数量为1000,算法需要1步;如果顾客数量为10 000,算法也需要1步;如果顾客数量为10亿,算法还是只需要1步。
对于常数时间复杂度的算法,如果将输入的顾客数量标在x轴上,步数标在y轴上,则图像是水平的(见图1.1)。
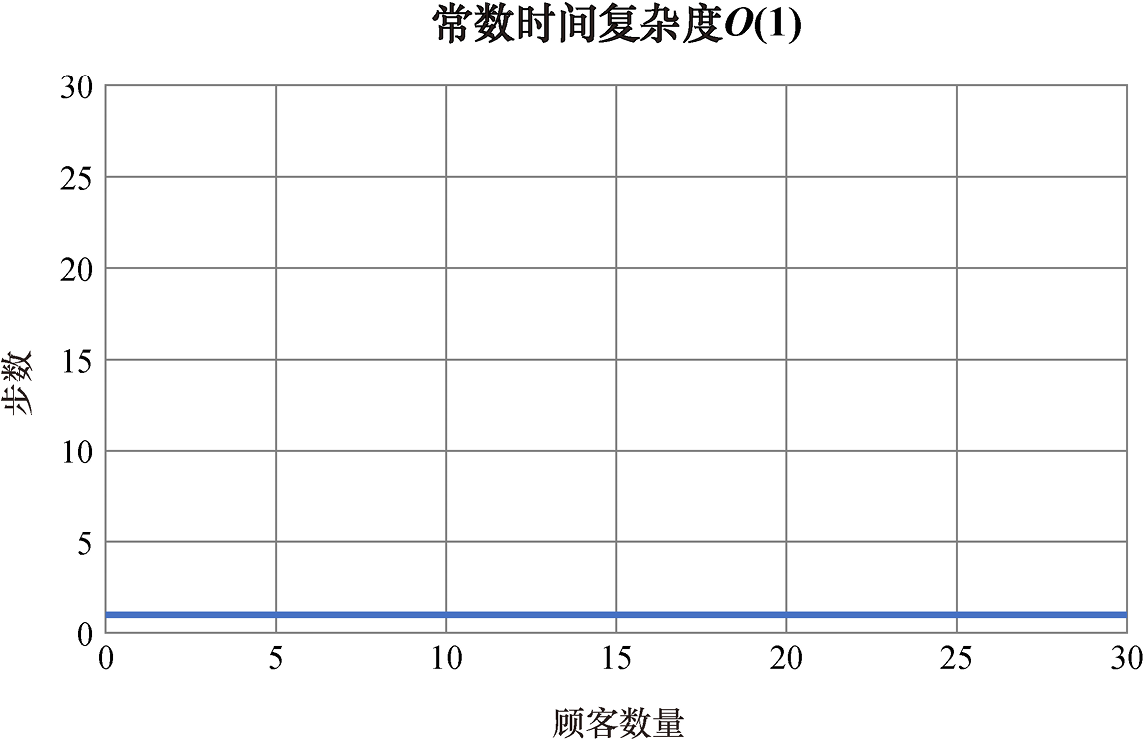
图1.1 常数时间复杂度
可以看到,随着问题规模的增加,算法的步数并不会变大。这是你能编写的最高效的算法,因为数据集增长时,算法运行的时间并不会增加。
对数时间复杂度是第二高效的时间复杂度。对数时间复杂度算法的运行时间与输入规模的对数成正比。二分搜索就是这种复杂度的算法,它在每次迭代中都可以丢弃许多值。如果你还不太清楚,不用担心,因为本书稍后还会深入探讨这部分内容。对数时间复杂度用大O记号记为O(logn)。
图1.2展示了对数时间复杂度算法的图像。
当数据集增大时,对数时间复杂度算法所需的步数增长得很缓慢。
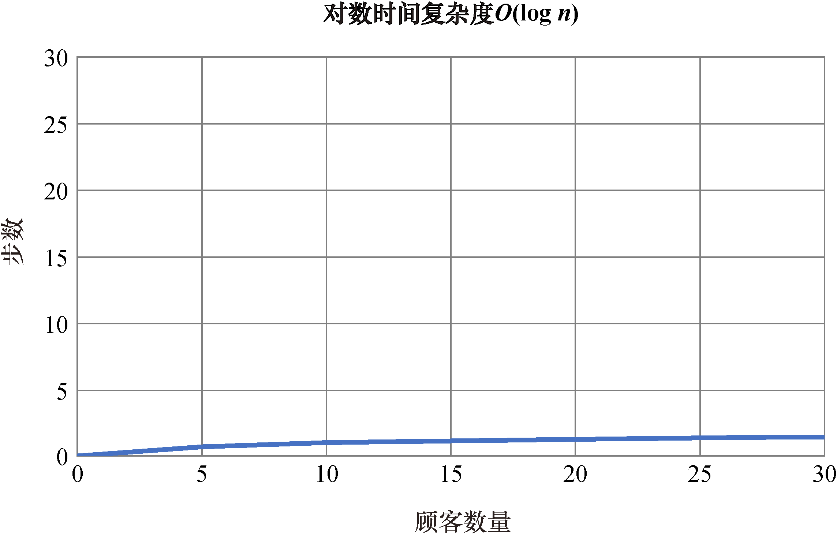
图1.2 对数时间复杂度
下一个高效的算法是线性时间复杂度算法。线性时间复杂度算法的运行时间与问题规模的增长速度相同。线性时间复杂度用大O记号记为O(n)。
假设你想修改免费赠书程序,你不想直接把书赠给每天的第一位顾客,而是在顾客名单中迭代,把书赠给名字以B开头的顾客。不过,你的顾客列表并没有按字母顺序排列,因此只能一个一个地在列表中迭代,才能找到名字以B开头的顾客。
free_book = False
customers = ["Lexi", "Britney", "Danny", "Bobbi", "Chris"]
for customer in customers:
if customer[0] == 'B':
print(customer)如果你的顾客列表中有5位顾客,则程序需要5步。如果有10位顾客,则需要10步;如果有20位顾客,则需要20步,以此类推。
这段程序的时间复杂度表达式为
f(n)=1+1+n
在大O记号中,你可以忽略常数,聚焦于表达式的主要部分:
O(n)=n
在线性时间复杂度算法中,当n变大时,算法的步数以同样的速度增加(见图1.3)。
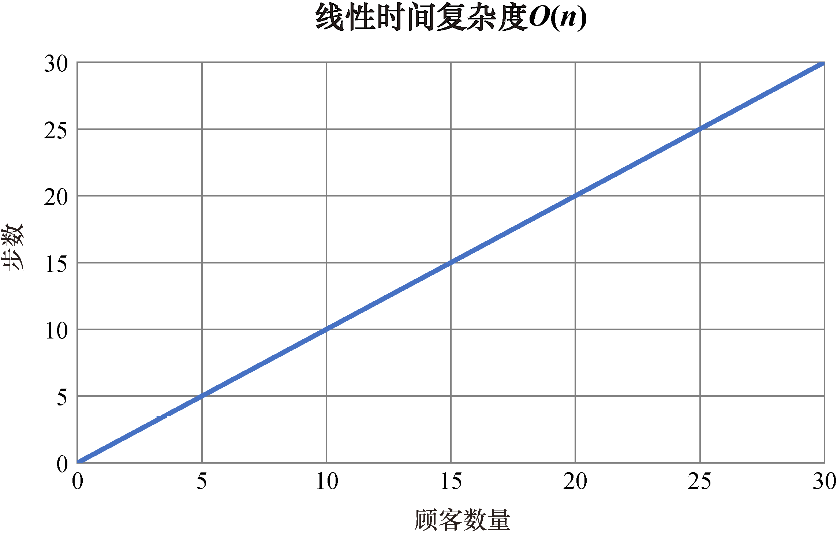
图1.3 线性时间复杂度
对数线性时间复杂度算法的增长率是对数与线性时间复杂度的组合(即乘积)。例如,对数线性时间复杂度算法可以将O(logn)的操作执行n次。对数线性时间复杂度用大O记号记为O(nlogn)。对数线性时间复杂度算法常将数据集分成较小的部分,并独立地进行处理。例如,我们后面要学到的许多高效的排序算法(如归并排序)就是对数线性时间复杂度算法。
图1.4展示了对数线性时间复杂度算法的图像。
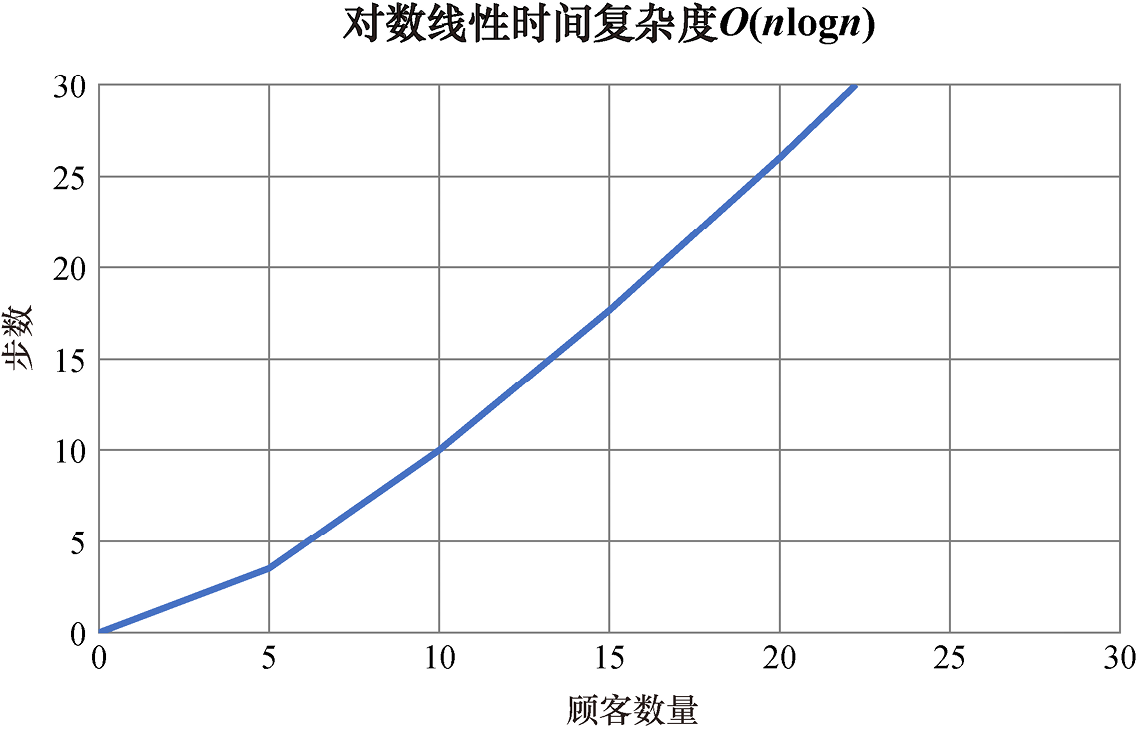
图1.4 对数线性时间复杂度
可以看到,对数线性时间复杂度不如线性时间复杂度高效,但我们即将学到,其复杂度的增长比平方时间复杂度慢一些。
在对数线性时间复杂度之后,下一个高效的时间复杂度是平方时间复杂度。对于平方时间复杂度的算法,其性能与问题规模的平方成正比。平方时间复杂度用大O记号记为O(n2)。
以下是一个平方时间复杂度算法示例:
numbers = [1, 2, 3, 4, 5]
for i in numbers:
for j in numbers:
x = i * j
print(x)这个算法将一个列表中的各个数字与各个数字相乘,将结果保存在变量中并输出。
在本例中,n就是numbers列表的长度,这一算法的时间复杂度表达式为
f(n)=1+n*n*(1+1)
式中(1+1)代表乘法运算与输出语句。在两层for循环中,需要重复这个乘法运算与输出语句共n*n次。上面的表达式可化简为
f(n)=1+(1+1)*n**2
即
f(n)=1+2*n**2
读者也许已经猜到,式中n**2的部分会掩盖其他部分,因此表达式用大O记号记为
O(n)=n**2
在图像上表示平方复杂度算法时,步数的增长比问题规模的增长速度更快(见图1.5)。
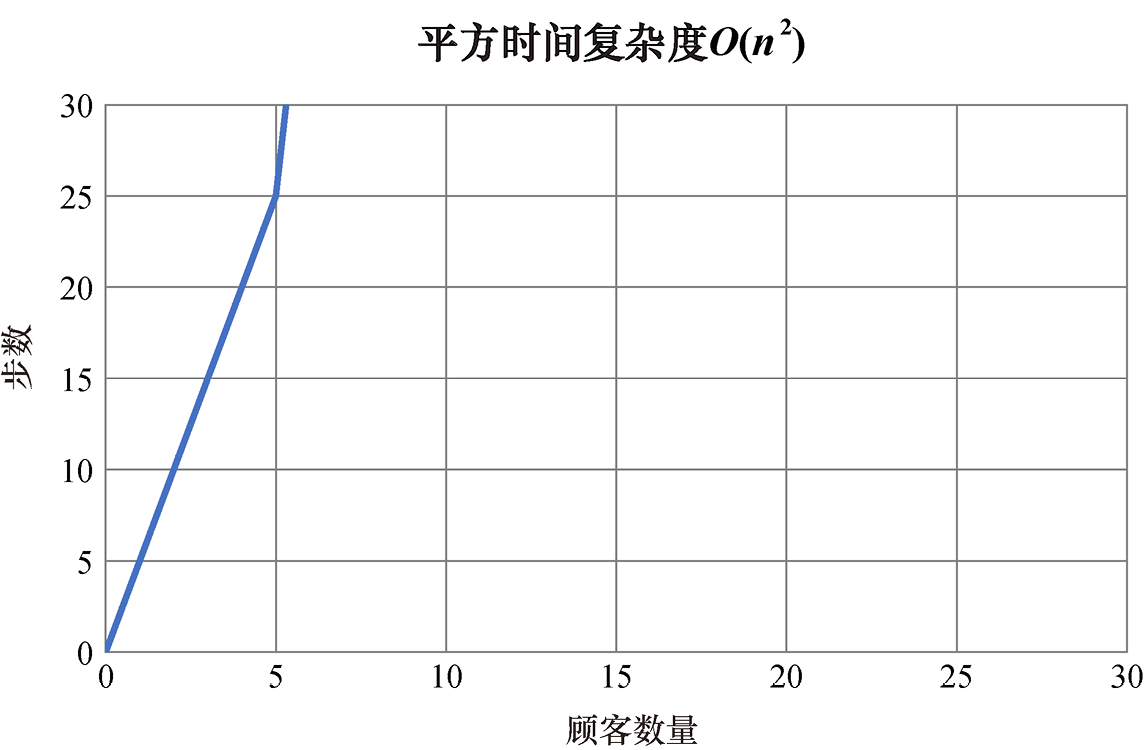
图1.5 平方时间复杂度
一般而言,如果你的算法包含两层嵌套的循环,每层都是从1到n(或从0到n-1),则其时间复杂度为O(n2)。许多排序算法,例如插入排序和冒泡排序(本书后面将会介绍)就是平方时间复杂度算法。
在平方时间复杂度之后是立方时间复杂度。立方时间复杂度算法的性能与问题规模的立方成正比。立方时间复杂度用大O记号记为O(n3)。立方时间复杂度与平方时间复杂度类似,区别仅在于立方时间复杂度的算法中n的幂次不是2,而是3。
以下是一个立方时间复杂度的算法:
numbers = [1, 2, 3, 4, 5]
for i in numbers:
for j in numbers:
for h in numbers:
x = i + j + h
print(x)该算法的表达式为
f(n)=1+n*n*n*(1+1)
即
f(n)=1+2*n**3
与平方时间复杂度的算法类似,上式中最重要的部分是n**3,因为它比其他部分增长得更快,即使式中包含n**2也不重要。因此立方时间复杂度用大O记号记为
O(n)=n**3
两层循环是平方时间复杂度的标志,而三层从0到n的循环则意味着算法是立方时间复杂度。在数据科学或统计学中,你常常会看到立方时间复杂度的算法。
平方和立方时间复杂度都是多项式时间复杂度大家族中的特例。多项式时间复杂度可记为O (na),其中若a=2则为平方时间复杂度,若a=3则为立方时间复杂度。在设计算法时,若有可能,一般应该避免多项式尺度,因为当n变大时,算法会变得很慢。有时你只能选择多项式尺度,但值得欣慰的是,到目前为止,多项式复杂度还不是最差的情况。
最差时间复杂度是指数时间复杂度。指数时间复杂度算法包含以问题规模为指数的项。换言之,具有指数时间复杂度的算法需要c的n次方步。指数时间复杂度用大O记号记为O(cn),其中c为常数。常数的值并不重要,重要的是n位于指数的位置上。
幸运的是,你不会经常遇到指数时间复杂度。指数时间复杂度的一个例子是通过逐一试验的方法猜测一个n位的数字密码,其时间复杂度为O(10n)。
用时间复杂度为O(10n)的算法猜测密码的示例如下:
pin = 931
n = len(pin)
for i in range(10**n):
if i == pin:
print(i)当n变大时,算法的步数增长得极为迅速。当n为1时,算法需要10步;n为2时就需要100步;n为3时就需要1000步。可以看到,一开始,指数算法似乎增长得不快,但最终就会爆炸式增长。猜测一个8位十进制数字的密码需要1亿步,猜测一个10位十进制数字的密码就需要100亿步。指数尺度说明了为什么设置长密码非常重要。如果有人尝试用这种程序猜测你的密码,则很容易猜出一个4位的密码,却无法破解一个20位的密码,因为此时程序运行的时间比人的一生还要长。
猜测密码的方案是暴力算法[1]的一个例子。暴力算法是检验所有可能答案的算法。暴力算法通常很低效,应当作为最后的手段。
[1]“暴力算法”也称“蛮力算法”“枚举算法”。
图1.6对比了几种时间复杂度算法的效率。
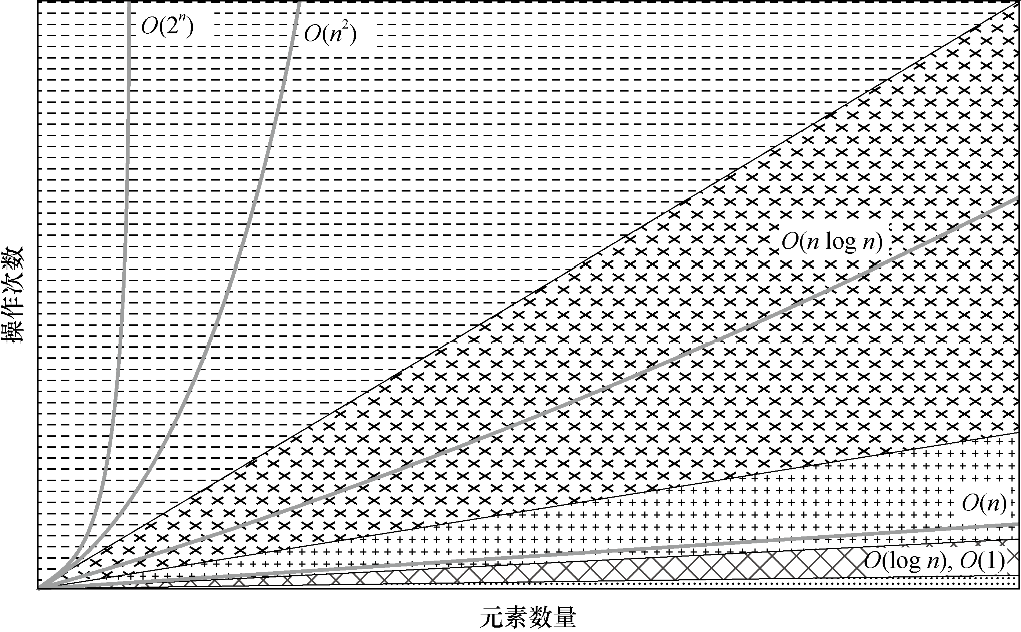
图1.6 大O复杂度图表
算法的性能可能会根据不同的因素(如要处理的数据的类型)发生变化。因此,在评价算法的性能时,你需要考虑最佳、最差和平均情况的复杂度。算法的最佳情况复杂度是理想输入情况下的性能,最差情况复杂度是在可能出现的最坏情况下的性能,而算法的平均情况复杂度则是算法的平均性能。
例如,当你需要在列表中进行逐个搜索时,可能会幸运地发现你要寻找的项目就是列表的第一项。这就是最佳情况复杂度。而如果要搜索的目标不在列表中,只能搜索整个列表,这就是最差情况复杂度了。
在对含有100个元素的列表进行逐一搜索时,平均而言,搜索时间是O(n/2),在大O记号中等同于O(n)。在比较算法时,我们通常优先考虑平均情况复杂度。如果需要做进一步分析,再来比较最佳情况和最差情况的复杂度。
计算机的内存等资源是有限的,因此除了算法的时间复杂度,还需要考虑其对资源的使用。空间复杂度描述了算法需要多少内存空间,包括固定空间、数据结构空间和临时空间。固定空间是指程序所需的内存空间。数据结构空间是指程序存储数据集所需的内存空间,例如你要搜索的列表。算法用于存储数据的内存空间取决于问题输入的规模。临时空间是指算法中间处理步骤所需的内存,例如算法可能需要临时复制一个列表以转移数据。
可以将之前学到的时间复杂度的概念应用于空间复杂度。例如,可以用常数空间复杂度(O(1))的算法计算n的阶乘(即小于或等于n的所有正整数之积):
x = 1
n = 5
for i in range(1, n + 1):
x = x * i这一算法的空间复杂度为常数,这是因为算法所需的空间并不随n的增大而增大。如果你决定将所有乘积的中间结果保存在列表中,那么该算法的空间复杂度就变成了线性空间复杂度(O(n)):
x = 1
n = 5
a_list = []
for i in range(1, n + 1):
a_list.append(x)
x = x * i这一算法的空间复杂度是O(n),因为其对空间的需求会与n同步增长。
与时间复杂度类似,算法可接受的空间复杂度也取决于具体的情况。不过一般而言,算法占用的空间越小越好。
作为一名计算机科学家,你需要理解不同的数量级才能优化你的算法。当尝试改进算法时,你应该聚焦于改变其数量级。例如,假设你有一个含有两层循环的复杂度为O(n2)的算法,别只优化循环内部,关键要看能否去掉两层循环重写算法,这样才能减小数量级。
如果可以用两个非嵌套的for循环编写程序,则算法将变为O(n)复杂度,这对性能是一个重大的提升。这种性能的提升比在复杂度为O(n2)的算法内部的修改有效得多。但是,考虑算法最佳和最差情况也很重要。也许复杂度为O(n2)的算法的最佳情况复杂度是O(n),而数据也恰好符合这一最佳情况。那么此时这个算法就是一个很好的选择了。
对算法的抉择会对真实世界产生重大影响。例如,假设你是一个网页开发者,需要编写算法对顾客的网络请求做出响应。编写的是常数时间还是平方时间复杂度的算法,将决定网页是在一秒内加载(让顾客都很满意),还是需要一分多(可能因加载太慢而流失顾客)。
以下是本章中涉及的一些词汇。
算法:解决某一问题的一系列步骤。
运行时间:计算机执行用Python等编程语言编写算法所需要的总时间。
问题规模:描述算法所需步数的表达式中的变量n。
大O记号:描述当n的规模增长时,算法时间或空间需求如何增长的数学记号。
数量级:每一类都远大于或远小于其他类的分类系统中的一类。
时间复杂度:当n变大时,算法所需的最大步数。
常数时间:无论问题的规模如何,常数时间的算法都需要相同的步数。
对数时间:对数时间算法的运行时间与输入规模的对数成正比。
线性时间:线性时间算法的运行时间与问题规模的增长速度相同。
对数线性时间:对数线性时间算法的增长率是对数与线性时间复杂度的组合(即乘积)。
平方时间:平方时间算法的性能与问题规模的平方成正比。
立方时间:立方时间算法的性能与问题规模的立方成正比。
多项式时间:多项式时间算法的复杂度为O (na),其中若a=2则为平方时间,若a=3则为立方时间。
指数时间:指数时间的算法包含以问题规模为指数的项。
暴力算法:检验所有可能答案的算法。
最佳情况复杂度:算法面对理想输入情况时的性能。
最差情况复杂度:算法面对可能的最差情况时的性能。
平均情况复杂度:算法的平均性能。
空间复杂度:算法需要的内存空间。
固定空间:程序所需的内存空间。
数据结构空间:程序存储数据集所需的内存空间。
临时空间:算法中间处理步骤所需的内存空间,例如你的算法可能需要临时复制一个列表以转移数据。
找出一个你曾经写过的程序。分析并写出其中所涉及算法的时间复杂度。





