
详情
内 容 提 要
R语言中的tidyverse包可以使数据的处理、转换和可视化变得简单、合理且可复制,大大简化了数据整理的过程。本书详细介绍了tidyverse包,主要内容包括R语言基础知识,数据导入,数据整理,数据变换,处理日期、因子与字符串,数据可视化,编程,建模等内容。
本书图文结合,实例丰富,语言通俗易懂,既适合商业数据分析从业者阅读,也适合科研工作者、统计工作者(特别是医学统计从业者)及各大专院校相关专业的师生等学习。

书名:R语言数据科学基础——基于tidyverse
ISBN:978-7-115-60705-8
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
著 高华川
责任编辑 张 涛
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线:(010)81055410
反盗版热线:(010)81055315
R语言中的tidyverse包可以使数据的处理、转换和可视化变得简单、合理且可复制,大大简化了数据整理的过程。本书详细介绍了tidyverse包,主要内容包括R语言基础知识,数据导入,数据整理,数据变换,处理日期、因子与字符串,数据可视化,编程,建模等内容。
本书图文结合,实例丰富,语言通俗易懂,既适合商业数据分析从业者阅读,也适合科研工作者、统计工作者(特别是医学统计从业者)及各大专院校相关专业的师生等学习。
tidyversetidyverse是R语言中一个专门为数据科学开发的R包集合,这些R包的设计理念、语法和数据结构保持一致,为数据科学工作流程提供了优质方案。
图1展示了一个规范化的数据科学工作流程及其各阶段所涉及的tidyverse包。
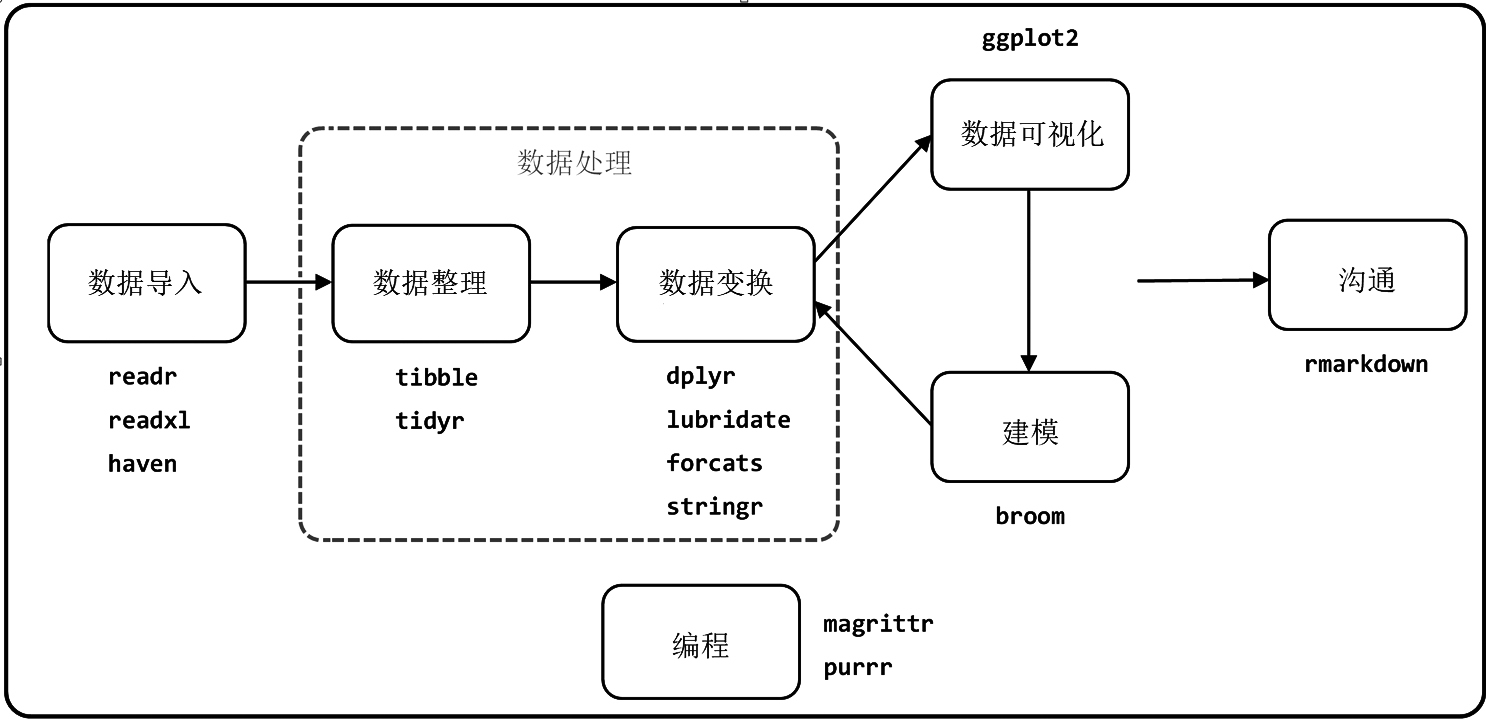
图1 数据科学工作流程
tidyverse的出现给R语言带来了巨大变革,各学科领域均出现了以tidyverse为基础的R包,形成了庞大的tidyverse生态系统。例如,机器学习领域的tidymodels、文本挖掘领域的tidytext、量化金融领域的tidyquant和时间序列分析领域的tidyverts等。掌握tidyverse是学习这些更高阶知识的基础。
本书共10章。
第1章介绍R语言中的对象、数据结构、常用函数、控制语句、管道操作符和自定义函数等基本知识。
第2章介绍利用readr、readxl和haven将CSV、Excel、Stata、SPSS、SAS等外部数据文件导入R语言的方法。
第3章重点讲解整洁数据的概念,以及如何利用tidyr中的函数pivot_longer()和pivot_wider()将原始数据整理为整洁数据。
第4章详细介绍dplyr的功能,包括筛选行、选择列、产生新变量和分组汇总等单表操作,以及根据键变量合并关系数据等双表操作。
第5章内容包括利用lubridate处理日期型变量,利用forcats处理分类变量(即R语言中的因子),以及利用stringr处理字符串等。
第6章讲解的重点内容为ggplot2的绘图语法。此外,该章还会介绍ggplot2的一些扩展R语言包,如latex2exp、showtext和patchwork等,以解决在图形中插入数学公式、使用字体、多图组合排版等问题。
第7章讲解purrr中的map()函数族,其主要作用是扩展向量化运算规则以代替for循环。
第8章介绍如何利用broom将建模过程中的非整洁输出转化为整洁的tibble,还重点介绍了列表列工作流,它能够一次性解决对多个子数据集建模并汇总分析不同模型结果的问题。
第9章讲解R Markdown文档的构成,以及如何利用R Markdown将数据分析过程与结果转化为高质量的文档、报告、演示文稿等。
第10章介绍格点搜索算法、Monte Carlo模拟和Bootstrap,并利用所学的tidyverse知识对这3种方法加以应用。
其中,每章都有“更多学习资源”一节,介绍该章重点内容以外的相关知识及相应学习资源。
及时更新:自tidyverse官方指南R for Data Science出版以来,R、RStudio和tidyverse都经历了多次大的版本更新,引入了很多新的功能和技术,也淘汰了一些过时的函数。本书在参考大量图书、文献和帮助文档的基础上,介绍了本书完稿时新版本的tidyverse,让读者能够了解新的R语言数据科学技术。此外,本书还提供配套的教学课件,当tidyverse发生较大的版本更新时,课件也会随之更新。
详略得当:本书系统地介绍了数据科学工作流程各个阶段及相应的R语言实现技术,每节均有重要知识点的总结,有利于读者对R语言数据科学整体知识结构的把握。
案例丰富:本书会通过具体的例子来讲解每一个R语言函数,以使读者深刻理解该函数的用法。此外,本书还提供了大量练习题,并给出了答案。
粗体表示新术语和重点强调的内容。
等宽字体(constant width) 表示代码,以及正文中出现的R对象,如变量、函数、参数等。
等宽斜体(constant width italic) 表示代码的输出结果(以#>开头)。
等宽黑体(constant width bold)表示R包名称。
本书得到国家社会科学基金项目“基于文本大数据的政策效应评价的方法与应用研究”(20BTJ058)的资助。
感谢天津财经大学统计学院的领导与同事对作者的写作给予的大力支持与鼓励。硕士生魏旗、常欢、田逢雨、马兴兴、樊雯莉、杜萱、王怡曼、吕骁儒、张晓星、徐祎涵等参与了本书的校对工作,在此表示衷心的感谢!感谢人民邮电出版社各位编辑付出的辛勤劳动!最后,特别感谢我的导师——南开大学张晓峒教授和天津财经大学白仲林教授,是他们的谆谆教诲才使我得以在本领域持续发展、研究。
由于本人学识有限,书中的疏漏与不足在所难免,恳请读者批评指正。
联系邮箱:tidyverse_gao@126.com。
本书编辑联系邮箱:zhangtao@ptpress.com.cn。
高华川
本章主要介绍R语言基础知识,包括对象、数据结构、常用函数、控制语句、管道操作符及自定义函数等内容。其中需要重点掌握原子向量、列表、因子和tibble等数据结构,以及一些基本运算规则,比如向量化运算、向量的循环补齐和强制转换等。
在R中,对象是指可以赋值给变量的任何事物,包括数据、表达式、函数,甚至是图形等。对象可以通过赋值操作来产生,赋值符可以是<-[1]或=,但为了养成良好的编程习惯并避免可能会引起的混淆,不建议使用=。如下代码将数值5赋值给一个名为a的对象。
[1] 赋值符<-的RStudio快捷键为Alt 加 -,即同时按Alt与减号键。
a <- 5
输入对象名可以查看对象的内容。
a #> [1] 5
R中的对象名必须遵循以下命名规则:以字母开头(A~Z或a~z),可以包含字母、数字(0~9)、下画线(_)及点(.)。除此以外,不能有任何其他字符,如空格、括号等。
还需要注意的是,R区分大小写。例如,上面代码只定义了对象a,但如果输入A,则会产生错误。
A #> Error in eval(expr, envir, enclos): 找不到对象'A'
➢ 知识点
• R对象命名规则:以字母开头(A~Z或a~z),可以包含字母、数字(0~9)、下画线(_)及点(.)。
• R区分大小写。
数据结构是指用于存储数据的对象类型。可以根据数据的维度(1维、2维或n维),以及数据是否同质(即是否类型相同)来对R的数据结构进行组织,如图1-1所示。
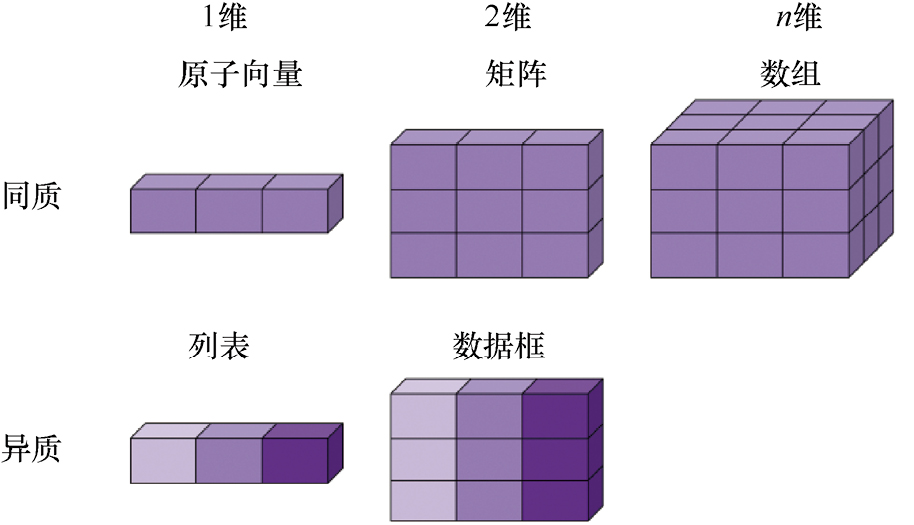
图1-1 数据结构示意图
原子向量是一种同质的一维数据结构,本节将介绍原子向量的类型及其基本运算规则。
函数c()常用于将多个元素组合(combine)成一个原子向量。
w <- c(TRUE, FALSE) w #> [1] TRUE FALSE
每个向量都有两个关键属性,即类型和长度,可以用typeof()和length()查看。
typeof(w) #> [1] "logical" length(w) #> [1] 2
可见w是一个长度为2的逻辑(logical)型向量。
创建整数(integer)型向量需要在整数后面加上L。
x <- c(1L, -3L) x #> [1] 1 -3 typeof(x) #> [1] "integer" length(x) #> [1] 2
seq()能够产生等差数列(sequence)。如下代码能够产生一个从1到5、步长为0.5的等差数列。
y <- seq(from = 1, to = 5, by = 0.5) y #> [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 typeof(y) #> [1] "double" length(y) #> [1] 9
在R中用双精度(double)型来表示实数,因此y是长度为9的双精度型向量。整数型和双精度型统称为数值(numeric)型。
用双引号括起来的字符为字符串。如下代码将产生一个长度为2的字符(character)型向量,其第一个元素为"Hello, world!",第二个元素为"R rocks!"。
z <- c("Hello, world!", "R rocks!")
z
#> [1] "Hello, world!" "R rocks!"
typeof(z)
#> [1] "character"
length(z)
#> [1] 2R中最重要的运算规则便是向量化运算:对单个向量做运算,就是对向量的每个元素做运算;多个向量之间做运算,就是对多个向量的对应元素做运算。由于R中没有“标量”这种数据结构,只有长度为1的向量[2],因此,R的多数算子与函数都是向量化的。下面从最基本的数学运算、比较运算和逻辑运算3个方面来介绍向量化运算的含义。
[2] 为了叙述简洁,本书将长度为1的向量简称为“标量”。
1)数学运算
数学运算是指加、减、乘、除和幂等作用于数值型向量并返回数值型向量的运算。
如下代码产生两个向量x和y。冒号(:)是产生步长为1的等差数列的简便方式,例如1:3即向量(1, 2, 3)。
x <- 1:3 y <- c(2, -4, 6)
对向量x求平方就是对x的每个元素求平方。其中,符号^表示幂运算。
x ^ 2 #> [1] 1 4 9
函数sqrt()表示平方根(square root),等价于x ^ (1/2)。
sqrt(x) #> [1] 1.000000 1.414214 1.732051
向量x乘以向量y得到的并不是向量内积,而是对应元素相乘的积。
x * y #> [1] 2 -8 18
2)比较运算
比较运算是指大于(>)、等于(==)、不等于(!=)等作用于数值型向量并返回逻辑型向量的运算。
比较运算符会先将向量的对应元素做比较,然后返回同长度的逻辑型向量。
x > y #> [1] FALSE TRUE FALSE x <= y #> [1] TRUE FALSE TRUE x != y #> [1] TRUE TRUE TRUE x == y #> [1] FALSE FALSE FALSE
3)逻辑运算
逻辑运算是指逻辑非(!)、逻辑与(&)、逻辑或(|)等作用于逻辑型向量并返回逻辑型向量的运算。
如下代码产生两个逻辑型向量w和z。
w <- c(TRUE, FALSE, TRUE) z <- c(FALSE, FALSE, TRUE)
很容易想到,对一个逻辑型向量取逻辑非会对该向量的每一个元素取逻辑非,两个向量做逻辑与(逻辑或)运算会对两个向量的对应元素做逻辑与(逻辑或)运算。
!w #> [1] FALSE TRUE FALSE w & z #> [1] FALSE FALSE TRUE w | z #> [1] TRUE FALSE TRUE
xor()为逻辑异或,有且仅有一个元素为TRUE时,它才会返回TRUE。
xor(w, z) #> [1] TRUE FALSE FALSE
有时需要只能作用于“标量”并返回“标量”的逻辑运算符,比如if分支语句或while循环语句中的逻辑条件,在这种情况下,“逻辑与”和“逻辑或”应当分别使用&&和||。
a <- TRUE b <- FALSE a && b #> [1] FALSE a || b #> [1] TRUE
3类运算的运算符总结见表1-1。
表1-1 3类运算的运算符总结
|
数学运算 |
比较运算 |
逻辑运算 |
|---|---|---|
|
+ 加法 |
< 小于 |
! 逻辑非 |
|
- 减法 |
> 大于 |
& 逻辑与(适用于向量) |
|
* 乘法 |
<= 小于等于 |
| 逻辑或(适用于向量) |
|
/ 除法 |
>= 大于等于 |
xor 逻辑异或 |
|
^ 幂 |
== 等于 |
&& 逻辑与(适用于标量) |
|
%% 取余 |
!= 不等于 |
|| 逻辑或(适用于标量) |
|
%/% 取整 |
假定有向量(1, 2, 3, 4)和(1, 2)。这两个向量的长度不同,因此从数学角度讲,这两个向量不能做运算。但在R中,会将短向量循环补齐为长向量,即将(1, 2)变为(1, 2, 1, 2),然后再做运算。
1:4 + 1:2 #> [1] 2 4 4 6
如果长向量的长度不是短向量长度的整倍数,R会抛出一个警告信息[3]。
[3] “警告”(warning)与“错误”(error)不同,警告依然会完成运算,而错误会终止运算。
1:5 + 1:2 #> Warning in 1:5 + 1:2: 长的对象长度不是短的对象长度的整倍数 #> [1] 2 4 4 6 6
这种运算规则可能会让初学者产生一些疑惑,但熟悉规则之后,就会逐渐发现其合理之处。尤其是将向量和“标量”一起做运算时,循环补齐规则是最有用的。例如,如果想对向量(1, 2, 3, 4, 5)的每一个元素加2,并不需要先产生向量(2, 2, 2, 2, 2)再与其相加,只需要对其直接加“标量”2即可。
(1:5) + 2 #> [1] 3 4 5 6 7
这一规则同样也适用于其他运算类型。
(1:5) < 3 #> [1] TRUE TRUE FALSE FALSE FALSE
前面介绍了原子向量分为4种类型,有时需要将一种类型的原子向量强制转换成另一种类型。有两种方式的强制转换:显式强制转换和隐式强制转换。
1)显式强制转换
R中有一族函数as.*()用于类型转换,如as.numeric()会将原子向量强制转换为数值型。
x <- c(TRUE, FALSE) as.numeric(x) #> [1] 1 0
当调用as.logical()、as.integer()、as.double()和as.character()这样的函数进行类型转换时,使用的就是显式强制转换。
y <- c(0, -1, -2, pi) # pi为R的保留字符,表示圆周率 as.logical(y) #> [1] FALSE TRUE TRUE TRUE
由此可见,如果将逻辑型转换为数值型,那么FALSE转换为0,TRUE转换为1;如果将数值型转换为逻辑型,那么0转换为FALSE,非0转换为TRUE。
2)隐式强制转换
当上下文环境要求使用特定类型的原子向量时,就会发生隐式强制转换。
一种常见的隐式强制转换发生于在数值环境中使用逻辑型向量时。例如,求和函数sum()要求作用于数值型向量。
v <- (-2):2 v #> [1] -2 -1 0 1 2 sum(v) #> [1] 0
但如果对逻辑型向量求和,那么在求和之前会先将逻辑型向量强制转换为数值型。因此,对逻辑型向量求和就是求TRUE的个数,求均值就是求TRUE的比例。
v < 0 #> [1] TRUE TRUE FALSE FALSE FALSE sum(v < 0) #> [1] 2 mean(v < 0) #> [1] 0.4
原子向量是同质的数据结构,即只能存储同种类型的元素。如果将不同类型的元素组成原子向量,那么R会将所有元素统一转换为复杂度更高、灵活性更强的类型,这是第二种常见的隐式强制转换。
c(TRUE, 1L) #> [1] 1 1 c(1L, 1.5) #> [1] 1.0 1.5 c(1.5, "a") #> [1] "1.5" "a"
下标系统也称为索引系统,用于对向量取子集。假定有如下向量x:
x <- seq(from = 2.1, to = 2.5, by = 0.1) x #> [1] 2.1 2.2 2.3 2.4 2.5
在R中用方括号[]来表示下标。如下代码用于提取x的第3个元素:
x[3] #> [1] 2.3
若要提取向量x的第2个和第5个元素,尝试如下代码:
x[2, 5] #> Error in x[2, 5]: 维度数目不对
可见R抛出错误信息并终止运算。原因在于原子向量是一维的数据结构,因此只能有一个下标,而上面的代码为双下标,只有对矩阵、数据框等二维数据结构才能用双下标。要想提取向量的多个元素,需要将下标组成一个新的向量。
x[c(2, 5)] #> [1] 2.2 2.5 x[1:3] #> [1] 2.1 2.2 2.3
在R的下标系统中,负号表示排除。如下代码提取x的除了第4个元素的其他所有元素:
x[-4] #> [1] 2.1 2.2 2.3 2.5
除了整数型向量,还可以用逻辑型向量作为下标,提取出对应TRUE位置的元素。
x[c(TRUE, FALSE, TRUE, FALSE, TRUE)] #> [1] 2.1 2.3 2.5
更进一步地,也可以用返回逻辑型向量的逻辑表达式作为下标。如下代码提取x中小于2.3的元素:
x[x < 2.3] #> [1] 2.1 2.2
要修改向量元素,可以直接赋值。
x[2] <- 20 x #> [1] 2.1 20.0 2.3 2.4 2.5
同样,要增加向量长度,也可以直接赋值。
x[6] <- 30 x #> [1] 2.1 20.0 2.3 2.4 2.5 30.0
练习1:前面讲到as.*()是一族用于显式强制转换的函数,与之对应的还有一族is.*()函数,用于判断对象是否属于某种类型,例如is.numeric(x)将判断x是否为数值型向量,返回TRUE或FALSE。另外,R用NA(Not Available)表示缺失值。根据以上说明预测如下代码的输出结果。
y <- c(1, NA, -2, NA, 7) is.na(y) y[!is.na(y)]
➢ 知识点
• 原子向量主要有4种类型,按复杂度和灵活性逐渐增加的顺序列出如下。
○ 逻辑(logical)型:TRUE和FALSE。
○ 整数(integer)型:整数(整数后加L)。
○ 双精度(double)型:实数。
○ 字符(character)型:引号括起来的字符。
• 向量化运算:
○ 对单个向量做运算,就是对向量的每个元素做运算;
○ 多个向量之间做运算,就是对多个向量的对应元素做运算。
• 循环补齐:长度不同的向量做运算时,先将短向量循环补齐到与长向量相同的长度之后再做运算。
• 强制转换:
○ 逻辑型转换为数值型时,FALSE转换为0,TRUE转换为1;
○ 数值型转换为逻辑型时,0转换为FALSE,非0转换为TRUE。
• 下标系统:
○ 可以用[]取原子向量的子集;
○ 下标可以是整数型(负数表示排除)或逻辑型向量。
列表是一种异质的一维数据结构,它与原子向量最大的区别是:原子向量中的元素只能是同种类型的,而列表中的元素可以是不同类型的。列表的主要作用是能够将多个对象整合到单个对象中。
可以用list()来创建列表。
l1 <- list("R", 3, TRUE)
l1
#> [[1]]
#> [1] "R"
#>
#> [[2]]
#> [1] 3
#>
#> [[3]]
#> [1] TRUE创建列表时可以为每个元素赋予一个名称,这种列表称为命名列表。
family <- list(name = "Ross", n_child = 2, child_age = c(7, 2), child_name = list("Ben", "Emma"))
family
#> $name
#> [1] "Ross"
#>
#> $n_child
#> [1] 2
#>
#> $child_age
#> [1] 7 2
#>
#> $child_name
#> $child_name[[1]]
#> [1] "Ben"
#>
#> $child_name[[2]]
#> [1] "Emma"此处创建了一个命名列表family,共包含4个元素:第一个元素的名称为name,其中存储了字符串"Ross";第二个元素的名称为n_child,其中存储了数值2;第三个元素的名称为child_age,其中存储了数值型向量(7, 2);第四个元素的名称为child_name,其中存储了一个长度为2的列表。
列表的下标有两种形式:一种是一个方括号[];另一种是两个方括号[[]]。[[]]用于提取列表的单个元素,括号内可以是元素下标,也可以是引号括起来的元素名称。
family[[3]] #> [1] 7 2 family[["child_age"]] #> [1] 7 2
还可以用符号$提取列表的单个命名元素,这时元素名称可以不加引号。
family$child_age #> [1] 7 2
需要注意的是,[[]]不能提取多个元素,但[]可以。
family[[1:2]] #> Error in family[[1:2]]: 下标出界 family[1:2] #> $name #> [1] "Ross" #> #> $n_child #> [1] 2
[]和[[]]的区别在于:[[]]返回列表的单个元素,而[]返回的是一个子列表。
family[[3]] #> [1] 7 2 family[3] #> $child_age #> [1] 7 2
Wickham(2016)这样区分列表元素与子列表:如果把列表x看成装载货物(元素)的火车,那么x[[3]]就是3号车厢中的货物(元素);而x[4:6]就是4~6号车厢(子列表)。
➢ 知识点
• 可以用list()来创建列表。
• 原子向量和列表之间的主要区别:
○ 原子向量是同质的(只能存储同种类型的元素);
○ 列表是异质的(可以存储不同类型的元素)。
• 下标系统:
○ []提取子列表;
○ [[]]提取列表单个元素;
○ $提取列表单个命名元素。
• 原子向量和列表都是一维数据结构(只有一个下标),因此不能类似写为:x[1, 3]。
原子向量和列表统称为向量,它们是最基本的数据结构。在向量的基础上附加“特性”(attribute)能够构建其他类型的向量,这些特殊的向量称为扩展向量。例如:
• 在整数型原子向量上附加“水平”特性,可以构造因子;
• 在原子向量上附加“维度”特性,可以构造矩阵;
• 在列表上附加“列名”“行名”特性,可以构造数据框。
attr()用来查看和设置对象的单个特性值,attributes()用来查看所有的特性值。例如,如下代码创建了一个数值型向量x,其特性为空。
x <- 1:4 attributes(x) #> NULL
如下代码将x的维度特性赋值为c(2, 2),即2行2列,x就会变成一个2×2的矩阵。
attr(x, "dim") <- c(2, 2) x #> [,1] [,2] #> [1,] 1 3 #> [2,] 2 4 attributes(x) #> $dim #> [1] 2 2
向量有3个最重要的特性:
• 名称(name),给每个元素一个名字的字符型向量;
• 维度(dimension),可以将向量转变成矩阵或数组;
• 类(class),R 中的一种面向对象系统。
这3个特性都可以用特定的函数来获取和设置,也就是可以使用names(x)、dim(x)和class(x)来代替attr(x, "names")、attr(x, "dim")和attr(x, "class")。例如,如下代码创建了一个命名向量y,其两个元素1和2的名称分别为"a"和"b"。
y <- c(a = 1, b = 2) y #> a b #> 1 2 names(y) #> [1] "a" "b"
可以直接对names()赋值来设置元素名称。
names(y) <- c("d", "e")
y
#> d e
#> 1 2变量可以分为分类变量和数值变量。分类变量只能在元素已知且有限的集合中取值,且其值不能用于数学运算,只能表达类别。分类变量又分为无序分类变量和有序分类变量。无序分类变量是指没有顺序之分的分类变量。例如,人的性别,即使在数据中将女性编码为0,男性编码为1,也并不意味着二者是有顺序的。有序分类变量表示一种顺序关系,但没有数量关系。例如,如果将人的健康水平分为较差、一般和较好,虽然我们知道健康水平为一般的人状态要好于较差的人,但并不知道好多少。数值变量可以取任意数值,可以同时表达顺序和数量关系。例如,人的年龄,显然30岁的人比29岁的人年长1岁。
分类变量可以由字符型向量表示。例如,如下字符型向量gender可以表示性别这一无序分类变量,其有两个唯一值female和male。
gender <- c("male", "female", "female", "female")
unique(gender)
#> [1] "male" "female"因子(factor)是R中专门用来表达分类变量的数据结构,它可以用factor()由字符型向量来创建。
gender_fct <- factor(gender) gender_fct #> [1] male female female female #> Levels: female male
因子的水平(level)是指分类变量的已知且有限的取值集合,可以用levels()提取。
levels(gender_fct) #> [1] "female" "male"
因子比字符型向量更适合表达分类变量,原因如下。
(1)从分类变量的已知且有限的取值集合这一角度来看。
如果存在变量值输入错误,字符型向量就无法识别不在分类变量取值集合中的值。例如,如下字符型向量gender2中第二个元素被错误地输入为femal,则其有3个唯一值,对于性别这一分类变量来说显然不合适。
gender2 <- c("male", "femal", "female", "female")
unique(gender2)
#> [1] "male" "femal" "female"如果在创建因子时用参数levels设定水平,那么不在水平中的值就会被转换为NA。
gender2_fct <- factor(gender2, levels = c("female", "male"))
gender2_fct
#> [1] male <NA> female female
#> Levels: female male另外,字符型向量也无法记录数据中暂时没有出现的取值。例如,如下字符型向量gender3中仅出现了female,无法反映性别这一分类变量未来可能出现的male这一水平。
gender3 <- c("female", "female", "female", "female")
unique(gender3)
#> [1] "female"而因子会保留暂时没有在数据中出现的水平。
gender3_fct <- factor(gender3, levels = c("female", "male"))
levels(gender3_fct)
#> [1] "female" "male"(2)从分类变量取值可能存在的顺序关系这一角度来看。
假定有如下表示星期的字符型向量week。
week <- c("Wednesday", "Friday", "Saturday", "Friday")因为字符型向量仅存在字典顺序,所以对week进行排序没有意义。
sort(week) #> [1] "Friday" "Friday" "Saturday" "Wednesday"
如果定义因子时没有设定参数levels,则因子的水平默认按照字典顺序排序,如gender_fct,但如果设定了levels,则会按照levels的设定顺序进行排序。因此,如果想要对分类变量的取值按照特定顺序进行排序,则需要在创建因子时设定levels。
week_levels <- c("Monday", "Tuesday", "Wednesday", "Thursday",
"Friday", "Saturday", "Sunday")
week_fct <- factor(week, levels = week_levels)
week_fct
#> [1] Wednesday Friday Saturday Friday
#> Levels: Monday Tuesday Wednesday Thursday Friday Saturday Sunday
sort(week_fct)
#> [1] Wednesday Friday Friday Saturday
#> Levels: Monday Tuesday Wednesday Thursday Friday Saturday Sunday实际上,因子就是附加了水平特性的整数型向量,它会按照levels的顺序将水平值映射为整数1,2,…,K,其中K为水平个数,见图1-2。也就是说,因子真正存储的是这些整数值,但显示的是对应的水平值,见图1-3。因为整数是有顺序的,所以这也相当于规定了水平的顺序。

图1-2 因子week_fct的水平与整数的映射关系
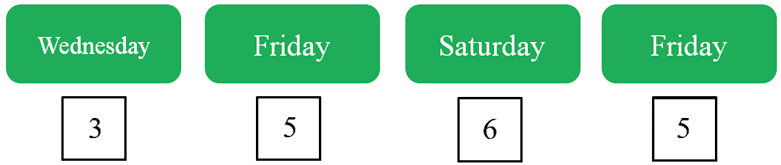
图1-3 因子week_fct的显示与存储
也正是因为字符型向量仅存在字典顺序,所以它无法表达有序分类变量。但如果在创建因子时设定参数ordered = TRUE,则可以表示有序分类变量。
health <- c("good", "poor", "poor", "fair")
health_fct <- factor(health, levels = c("poor", "fair", "good"), ordered = TRUE)
health_fct
#> [1] good poor poor fair
#> Levels: poor < fair < good(3)从对分类变量的专门操作这一角度来看。
字符型向量只能按照字符串进行操作,而对分类变量的一些操作,例如增加、删除、修改水平以及改变水平顺序等,仅适用于因子,详见第5章。
正因如此,在R中需要对分类变量进行操作时通常会隐式地将字符型向量强制转换为因子。为使代码更加清晰,建议字符型向量仅用来表示文本数据,而分类变量均用因子来表示。
还可以通过设定factor()的水平参数levels和标签参数labels将数值型向量编码成因子,且levels的顺序必须和labels相一致。
gender4 <- c(1, 0, 0, 1, 0)
gender4_fct <- factor(gender4, levels = c(0, 1), labels = c("female", "male"))
gender4_fct
#> [1] male female female male female
#> Levels: female malecut()可以将连续型变量离散化以产生因子。如下代码将age离散化为4个水平:(0, 18]之间的取值对应水平juvenile,(18, 45]之间的取值对应水平young,(45, 60]之间的取值对应水平middle_aged,(60, 100]之间的取值对应水平old。
age <- c(60, 70, 39, 50)
cut(age,
breaks = c(0, 18, 45, 60, 100),
labels = c("juvenile", "young", "middle_aged", "old"),
ordered_result = TRUE)
#> [1] middle_aged old young middle_aged
#> Levels: juvenile < young < middle_aged < old➢ 知识点
• 因子是R中专门用于表示分类变量的数据结构。
• 可以用factor()来创建因子:
○ 参数levels可以设定水平值及其排序,若不设定levels,则水平值由唯一值决定,水平排序由字典顺序决定;
○ 参数ordered = TRUE可以表示有序分类变量。
• 建议字符型向量仅用来表示文本数据,而分类变量均用因子来表示。
矩阵是在统计计算等领域常用的一种数据结构,但在数据科学领域极少用到。
matrix()可用于创建矩阵,其参数nrow确定矩阵的行数,ncol确定矩阵的列数。默认按列填充矩阵,如果设定参数byrow = TRUE则按行进行填充。
m1 <- matrix(1:6, nrow = 2, ncol = 3) m2 <- matrix(1:6, nrow = 2, ncol = 3, byrow = TRUE) m1 #> [,1] [,2] [,3] #> [1,] 1 3 5 #> [2,] 2 4 6 m2 #> [,1] [,2] [,3] #> [1,] 1 2 3 #> [2,] 4 5 6
dim()、nrow()和ncol()分别用于求出矩阵的维度、行数和列数。
dim(m1) #> [1] 2 3 nrow(m1) #> [1] 2 ncol(m1) #> [1] 3
矩阵是2维数据结构,需要有两个下标。如下代码提取m1第1行第2列的元素。
m1[1, 2] #> [1] 3
如果一个下标位置为空,则表示提取此维度的所有元素。如下代码可以提取m1第1行的所有元素,以及第1列和第3列的所有元素。
m1[1, ] #> [1] 1 3 5 m1[ , c(1, 3)] #> [,1] [,2] #> [1,] 1 5 #> [2,] 2 6
负号(-)的含义与在其他数据结构中相同,表示排除。
m1[ , -2] #> [,1] [,2] #> [1,] 1 5 #> [2,] 2 6
矩阵实际上是一种附加了“维度”特性的原子向量,因此矩阵也是同质的,并且也要遵守向量化运算规则。
m1 * m2 # 对应元素相乘 #> [,1] [,2] [,3] #> [1,] 1 6 15 #> [2,] 8 20 36 m1 ^ 2 # 每一个元素取平方 #> [,1] [,2] [,3] #> [1,] 1 9 25 #> [2,] 4 16 36
下面列举了一些常用的矩阵运算。
t(m1) # 求转置矩阵 #> [,1] [,2] #> [1,] 1 2 #> [2,] 3 4 #> [3,] 5 6 m3 <- matrix(7:12, nrow = 3, ncol = 2) m4 <- m1 %*% m3 # 矩阵乘法 m4 #> [,1] [,2] #> [1,] 76 103 #> [2,] 100 136 solve(m4) # 求逆矩阵 #> [,1] [,2] #> [1,] 3.777778 -2.861111 #> [2,] -2.777778 2.111111 eigen(m4) # 求特征值(eigen value)与特征向量(eigen vector) #> eigen() decomposition #> $values #> [1] 211.8300524 0.1699476 #> #> $vectors #> [,1] [,2] #> [1,] -0.6042245 -0.8052973 #> [2,] -0.7968141 0.5928712
大部分情况下,数据集都是以数据框的形式存储的。因此,数据框是R数据科学中最常见的数据结构。R中的数据框分为两种:一种是传统数据框data.frame;另一种是现代数据框tibble[4]。由于tibble对data.frame的功能进行了改进,更易于在数据科学领域使用,因此,本节重点介绍tibble。
[4] 本书会交替使用tibble和数据框这两个术语。如果想要强调传统数据框,会使用data.frame。
R诞生于1995年,经过近30年的发展,部分基础功能已经过时。在不破坏现有代码的前提下,很难修改R的基础功能,因此多数革新都是以R包的形式出现的。tibble这一新的数据结构便是以R包tibble实现的。
可以用tibble包中的tibble()按列创建tibble,其参数为已经命名的向量。
library(tibble)
a <- tibble(
x = 1:4,
y = 5,
z = x ^ 2 + log(y)
)
a
#> # A tibble: 4 x 3
#> x y z
#> <int> <dbl> <dbl>
#> 1 1 5 2.61
#> 2 2 5 5.61
#> 3 3 5 10.6
#> 4 4 5 17.6其中,y这一列利用了R的循环补齐功能。在创建tibble时可以利用刚产生的新变量(x和y)来生成另一个新变量(z)。
也可以用tribble()[5]按行创建tibble,其列名以“~”开头,各元素以“,”分隔。
[5] tribble为transposed tibble的缩写,transpose意为转置。
b <- tribble(
~x, ~y, ~z,
"male", 1, TRUE,
"female", 2, FALSE
)
b
#> # A tibble: 2 x 3
#> x y z
#> <chr> <dbl> <lgl>
#> 1 male 1 TRUE
#> 2 female 2 FALSE从数据结构是否同质的角度讲,tibble与列表类似,都是异质的数据结构,其不同的列可以存储不同类型的向量。例如b中的x这一列为字符型,y为双精度型,z为逻辑型。实际上,tibble是一种特殊的命名列表,其所有元素都是长度相同的向量。由于tibble的列类似于列表的元素,因此可以通过[[]]和$来提取tibble中单个列的元素。
a[[1]] #> [1] 1 2 3 4 b$y #> [1] 1 2
[]可以提取tibble的多个列,且总是返回一个子tibble。
a[c(2, 3)] #> # A tibble: 4 x 2 #> y z #> <dbl> <dbl> #> 1 5 2.61 #> 2 5 5.61 #> 3 5 10.6 #> 4 5 17.6 a[3] #> # A tibble: 4 x 1 #> z #> <dbl> #> 1 2.61 #> 2 5.61 #> 3 10.6 #> 4 17.6
从数据结构维度的角度讲,tibble又与矩阵类似,都是二维的数据结构,可以用双下标来提取特定位置的值。
a[2, 3] #> # A tibble: 1 x 1 #> z #> <dbl> #> 1 5.61 a[1, c(1, 2)] #> # A tibble: 1 x 2 #> x y #> <int> <dbl> #> 1 1 5 b[ , 2] #> # A tibble: 2 x 1 #> y #> <dbl> #> 1 1 #> 2 2
总体来看,tibble兼具列表和矩阵的特点:如果用单下标来选取tibble的列,则tibble的行为像列表;如果用双下标来选取tibble的值,则tibble的行为像矩阵。
利用tibble()或tribble()创建的tibble通常作为示例数据使用。一般情况下,数据框都来自外部数据导入,或者某些函数的处理结果。例如,R包palmerpenguins中的数据集penguins便是一个tibble,其中包含了生活在南极洲Palmer群岛的3类企鹅的信息(见图1-4和图1-5[6]),共有344组观测、8个变量。
[6] 图1-4和图1-5来自palmerpenguins包的主页。
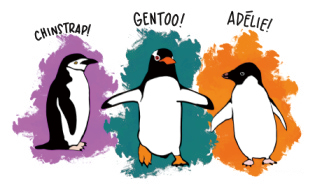
图1-4 企鹅类别
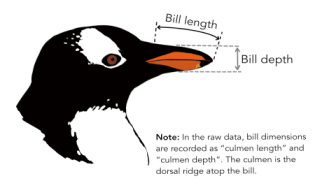
图1-5 企鹅喙的长度与深度
pacman::p_load(palmerpenguins) penguins #> # A tibble: 344 x 8 #> species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g #> <fct> <fct> <dbl> <dbl> <int> <int> #> 1 Adelie Torgersen 39.1 18.7 181 3750 #> 2 Adelie Torgersen 39.5 17.4 186 3800 #> 3 Adelie Torgersen 40.3 18 195 3250 #> 4 Adelie Torgersen NA NA NA NA #> 5 Adelie Torgersen 36.7 19.3 193 3450 #> 6 Adelie Torgersen 39.3 20.6 190 3650 #> 7 Adelie Torgersen 38.9 17.8 181 3625 #> 8 Adelie Torgersen 39.2 19.6 195 4675 #> 9 Adelie Torgersen 34.1 18.1 193 3475 #> 10 Adelie Torgersen 42 20.2 190 4250 #> # ... with 334 more rows, and 2 more variables: sex <fct>, year <int>
企鹅数据集中各列的含义及类型如下。
• species:企鹅的种类。因子型(简写为fct),有3种水平——Adelie、Chinstrap和Gentoo。
• island:企鹅来自南极洲Palmer群岛上的哪座岛屿。因子型,有3种水平——Biscoe、Dream和Torgersen。
• bill_length_mm:喙的长度。单位:毫米。双精度型(简写为dbl)。
• bill_depth_mm:喙的深度。单位:毫米。双精度型。
• flipper_length_mm:鳍的长度。单位:毫米。整数型(简写为int)。
• body_mass_g:体重。单位:克。整数型。
• sex:性别。因子型,有两种水平——female和male。
• year:研究的年份。整数型。
从企鹅数据集的打印结果可以看出,tibble这一数据结构的打印形式有如下3个特点:
(1)会显示tibble的维度(多少行多少列);
(2)会显示每一列的类型;
(3)为了避免在显示行数或列数很多的tibble时输出占满控制台,会只显示前10行,并且显示的列数也是适合屏幕的[7],还会提示还有多少行多少列没有显示。这一特点非常适合大数据集。
[7] 在控制台输入如下代码可以控制tibble的默认打印方式:
• options(tibble.print_max = m, tibble.print_min = n)表示如果多于m行,则只打印出n行;
• options(tibble.print_min = Inf)表示总是打印所有行;
• options(tibble.width = Inf)表示总是打印所有列。
在了解数据框概要信息时,有两个函数较为有用:str()能够提供R对象的结构信息;summary()能够提供R对象的统计汇总信息。
str(penguins) #> tibble [344 x 8] (S3: tbl_df/tbl/data.frame) #> $ species : Factor w/ 3 levels Adelie","Chinstrap",..: 1 1 1 1 1 1 1 ... #> $ island : Factor w/ 3 levels "Biscoe","Dream",..: 3 3 3 3 3 3 3 ... #> $ bill_length_mm : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 ... #> $ bill_depth_mm : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 ... #> $ flipper_length_mm: int [1:344] 181 186 195 NA 193 190 181 195 193 ... #> $ body_mass_g : int [1:344] 3750 3800 3250 NA 3450 3650 3625 4675 3 ... #> $ sex : Factor w/ 2 levels "female","male": 2 1 1 NA 1 2 1 2 ... #> $ year : int [1:344] 2007 2007 2007 2007 2007 2007 2007 2007 ... summary(penguins) #> species island bill_length_mm bill_depth_mm #> Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10 #> Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60 #> Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30 #> Mean :43.92 Mean :17.15 #> 3rd Qu.:48.50 3rd Qu.:18.70 #> Max. :59.60 Max. :21.50 #> NA's :2 NA's :2 #> flipper_length_mm body_mass_g sex year #> Min. :172.0 Min. :2700 female:165 Min. :2007 #> 1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007 #> Median :197.0 Median :4050 NA's : 11 Median :2008 #> Mean :200.9 Mean :4202 Mean :2008 #> 3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009 #> Max. :231.0 Max. :6300 Max. :2009 #> NA's :2 NA's :2
R包skimr中的skim()会给出比str()和summary()更全面的汇总信息,是数据科学中常用的函数。
pacman::p_load(skimr) skim(penguins) #> -- Data Summary ------------------------ #> Values #> Name penguins #> Number of rows 344 #> Number of columns 8 #> _______________________ #> Column type frequency: #> factor 3 #> numeric 5 #> ________________________ #> Group variables None #> -- Variable type: factor ------------------------------------------------------ #> # A tibble: 3 x 6 #> skim_variable n_missing complete_rate ordered n_unique top_counts #> * <chr> <int> <dbl> <lgl> <int> <chr> #> 1 species 0 1 FALSE 3 Ade: 152, Gen: 124, Chi: 68 #> 2 island 0 1 FALSE 3 Bis: 168, Dre: 124, Tor: 52 #> 3 sex 11 0.968 FALSE 2 mal: 168, fem: 165 #> -- Variable type: numeric ----------------------------------------------------- #> # A tibble: 5 x 11 #> skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100 hist #> * <chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> #> 1 bill_length_mm 2 0.994 43.9 5.46 32.1 39.2 44.4 48.5 59.6 ▃▇▇▆▁ #> 2 bill_depth_mm 2 0.994 7.2 1.97 13.1 15.6 17.3 18.7 21.5 ▅▅▇▇▂ #> 3 flipper_length_mm 2 0.994 201. 14.1 172 190 197 213 231 ▂▇▃▅▂ #> 4 body_mass_g 2 0.994 4202. 802. 2700 3550 4050 4750 6300 ▃▇▆▃▂ #> 5 year 0 1 2008. 0.818 2007 2007 2008 2009 2009 ▇▁▇▁▇
可以通过data.frame()来按列创建data.frame。
df <- data.frame(
name = c("Jack", "John", "Jessica"),
graduate = c(FALSE, TRUE, TRUE),
score = c(70, 90, 80)
)
df
#> name graduate score
#> 1 Jack FALSE 70
#> 2 John TRUE 90
#> 3 Jessica TRUE 80下面以iris数据集为例进行讲解。iris是R包datasets[8]中数据结构为data.frame的数据集,存储了150朵鸢尾花的花萼长度(Sepal.Length)、花萼宽度(Sepal.Width)、花瓣长度(Petal.Length)、花瓣宽度(Petal.Width)和类别(Species)5个变量。data.frame不具有tibble的打印特点,例如在控制台输入iris会显示其所有行和列,从而会充满整个控制台,并且不会显示各列的类型与数据集的维度信息。
[8] datasets是R基础包,无须安装和加载。
如果想利用tibble的优势,可以用as_tibble()将data.frame转换为tibble。
as_tibble(iris) #> # A tibble: 150 x 5 #> Sepal.Length Sepal.Width Petal.Length Petal.Width Species #> <dbl> <dbl> <dbl> <dbl> <fct> #> 1 5.1 3.5 1.4 0.2 setosa #> 2 4.9 3 1.4 0.2 setosa #> 3 4.7 3.2 1.3 0.2 setosa #> 4 4.6 3.1 1.5 0.2 setosa #> 5 5 3.6 1.4 0.2 setosa #> 6 5.4 3.9 1.7 0.4 setosa #> 7 4.6 3.4 1.4 0.3 setosa #> 8 5 3.4 1.5 0.2 setosa #> 9 4.4 2.9 1.4 0.2 setosa #> 10 4.9 3.1 1.5 0.1 setosa #> # ... with 140 more rows
由于有些比较旧的函数不支持tibble这种现代数据结构,有时可能需要用as.data.frame()将tibble转换为data.frame,例如as.data.frame(penguins)。
通过如下代码打开tibble的帮助文档可以查看更多tibble的特性及其与data.frame的区别。
vignette("tibble", package = "tibble")➢ 知识点
• 数据科学中常用tibble这一数据结构来存储数据集。
• tibble和列表都是异质的数据结构,单下标可以提取tibble的列中的元素:
○ [[]]和$提取tibble的单个列;
○ []可以提取tibble的多个列,且总是返回一个子tibble。
• tibble和矩阵都是二维的数据结构,双下标可以提取tibble的值。
常用数学函数的总结见表1-2。
表1-2 常用数学函数的总结
|
函数 |
作用 |
备注或示例 |
|---|---|---|
|
|
绝对值 |
|
|
|
平方根 |
|
|
|
三角函数 |
|
|
|
自然对数 |
|
|
|
指数 |
|
|
|
向上取整(大于等于 |
|
|
|
向下取整(小于等于 |
|
|
|
向0取整(向0方向截取 |
|
|
|
将x四舍五入到n位小数 |
|
常用统计函数的总结见表1-3。
表1-3 常用统计函数的总结
|
函数 |
作用 |
备注或示例 |
|---|---|---|
|
|
均值 |
|
|
|
中位数 |
R没有提供求众数的函数 |
|
|
方差 |
|
|
|
标准差 |
|
|
|
协方差 |
|
|
|
相关系数 |
|
|
|
求和 |
|
|
|
最小值 |
|
|
|
最大值 |
|
|
|
取值范围 |
即同时返回最小值和最大值 |
|
|
分位数 |
返回向量 |
R服从缺失值原则,即如果x中有缺失值,那么以上统计函数也会返回缺失值。好在这些函数都有参数na.rm,如果设定na.rm = TRUE,那么在做运算时会提前把缺失值去掉。
x <- c(1, 2, NA, 3) mean(x) #> [1] NA mean(x, na.rm = TRUE) #> [1] 2
练习2:运行如下代码,并通过运行结果了解缺失值NA和空值NULL的区别。
x <- c(1, 2, NA, 3) y <- c(1, 2, NULL, 3) length(x) length(y) mean(x) mean(y)
在R中,统计分布函数的命名形式为:
[rdpq]distribution_abbreviation()
首字母表示有关统计分布的4类操作:
• r表示生成随机(random)数;
• d表示求密度(density)函数的值;
• p表示求分布函数的值,即返回值是概率(probability);
• q表示求分布函数逆函数的值,即返回值是分位数(quantile)。
首字母之后是分布函数的简写。例如,正态(normal)分布简写为norm。有关正态分布的4种函数及其功能见表1-4。
表1-4 有关正态分布的4种函数及其功能
|
函数 |
功能 |
|---|---|
|
|
产生正态分布随机数 |
|
|
求正态密度函数在某点的值 |
|
|
求正态分布概率 |
|
|
求正态分布分位点 |
在控制台输入?rnorm可以打开有关正态分布的4种函数的帮助文档,发现均值参数mean的默认值为0,标准差参数sd的默认值为1,即如果不设定mean和sd的值,将默认为标准正态分布N(0, 1)。如下代码可以生成来自N(0, 1)的10个随机数。
rnorm(10) #> [1] 0.76759940 0.49516312 0.56447931 -0.33915325 -1.07372475 0.48091479 #> [7] -1.70065497 -0.05524973 0.35989199 -0.12659350
也可以设定均值参数和标准差参数。如下代码可以生成来自N(-5, 9)的10个随机数[9]:
[9] 注意rnorm()中设定的是标准差参数sd,而正态分布的数学表示N(μ, σ2)中的σ2为方差。
rnorm(10, mean = -5, sd = 3) #> [1] -10.596272 -3.343484 -3.981940 -5.615956 -13.171890 -9.194688 #> [7] -9.050093 -3.038397 -0.439610 -11.495256
N(1, 4)的密度函数在x = 0处的取值为:
dnorm(0, mean = 1, sd = 2) #> [1] 0.1760327
N(0, 1)的下2.5%分位点为:
qnorm(0.025) #> [1] -1.959964
N(0, 1)的分布函数在x = 1.96时的取值为:
pnorm(1.96) #> [1] 0.9750021
表1-5列举了一些常用的统计分布函数。在控制台输入?Distributions可以查看R所支持的所有统计分布函数。
表1-5 常用统计分布函数
|
中文分布名称 |
英文分布名称 |
R函数(*代表rdpq) |
|---|---|---|
|
正态分布 |
Normal |
|
|
t分布 |
t (student) |
|
|
卡方分布 |
Chisquare |
|
|
F分布 |
F |
|
|
泊松分布 |
Poisson |
|
|
指数分布 |
Exponential |
|
|
二项分布 |
Binomial |
|
|
均匀分布 |
Uniform |
|
练习3:
(1)求出标准正态分布的上2.5%分位点;
(2)求出标准正态分布随机变量X取值大于1.96的概率;
(3)求出标准正态分布的密度函数在(-2, -1.99, …,-0.01, 0, 0.01, …, 1.99, 2)处的取值;
(4)生成来自χ2(5)(自由度为5的卡方分布)的10个随机数;
(5)求出t(100)(自由度为100的t分布)的下2.5%分位点。
你产生的随机数可能和本书产生的随机数不同,且运行两次同样的产生随机数的代码所产生的随机数也不同。原因在于,每次生成随机数时,函数都会使用一个不同的随机数种子。因此每次生成的随机数均不相同。在实际数据科学工作中,尤其是科研工作中,为了满足结果的可重现要求,通常会用set.seed()设定同一个随机数种子,以让不同的人产生的随机数相同,从而能够复现其他人的研究结果。
set.seed()要求对于任意一个整数,只要此整数相同,所有人产生的随机数均相同。
set.seed(123) rnorm(10) #> [1] -0.56047565 -0.23017749 1.55870831 0.07050839 0.12928774 1.71506499 #> [7] 0.46091621 -1.26506123 -0.68685285 -0.44566197
R中的代码是按照从上到下的顺序执行的。但有时我们可能希望仅在满足某条件的情况下执行某些代码(分支语句),或重复执行某些代码(循环语句)。分支语句和循环语句统称为控制语句。控制语句在统计计算等领域非常重要,但在本书后面章节中极少用到。读者可以在控制台输入?Control打开控制流的帮助文档进行了解。
为理解本节内容,特约定如下符号。
• condition:表示返回值为TRUE或FALSE的逻辑条件。
• statements:表示一条或多条R代码。
• var:表示某一变量。
• vector:表示某一向量。
if分支语句较为简单,其用法为[10]:
[10] 如果控制语句中的statements中只有一条语句,那么可以不写大括号{}。
if (condition) {
statements
}含义是:当条件condition为TRUE时,执行{}中的代码statements,否则跳过。
if-else分支语句最为常见,其用法为:
if (condition) {
statements1
} else {
statements2
}含义是:当条件condition为TRUE时,执行代码statements1;否则执行代码statements2。
需要注意的是,若执行了某一分支语句,则另一分支语句不会执行。如下代码由于执行了else后的语句,if后的语句并不执行,因此不存在变量p。
r <- 2
if (r == 4){
p <- 1
} else {
q <- 4
}
p
#> Error in eval(expr, envir, enclos): 找不到对象'p'
q
#> [1] 4如果程序有多条分支,可以将if-else嵌套起来,如三分支语句if-else if-else的用法为:
if (condition1) {
statements1
} else if (condition2) {
statements2
} else {
statements3
}含义是:当条件condition1为TRUE时,执行代码statements1;否则,当条件condition2为TRUE时,执行代码statements2;否则,执行代码statements3。
如果有很多分支,可以考虑使用多分支语句switch()。
for循环语句常用于循环次数已知的情况,其用法为:
for(var in vector){
statements
}含义是:变量var取向量vector中的第1个元素,并执行代码statements;然后var取vector中的第2个元素,再次执行代码statements;直到var遍历vector中的所有元素,共执行length(vector)次代码statements。
v <- c(5, 12, 13)
for (j in v) {
print(j ^ 2)
}
#> [1] 25
#> [1] 144
#> [1] 169假定想要求出如下的示例数据集tbl的每一列的均值。
set.seed(123) tbl <- tibble( a = rnorm(10), b = rnorm(10), c = rnorm(10) )
seq_along()与1:length()的作用基本相同,但seq_along()更不容易出错。例如,tbl有3列,因此seq_along(tbl)的返回值为(1, 2, 3)。
seq_along(tbl) #> [1] 1 2 3
可以首先产生一个向量output以备存储tbl的列均值,然后让j在tbl的各列进行循环求均值,并存储在output的对应位置。
output <- rep(NA, times = length(tbl))
output
#> [1] NA NA NA
for (j in seq_along(tbl)) {
output[j] <- mean(tbl[[j]])
}
output
#> [1] 0.07462564 0.20862196 -0.42455887while循环语句常用于在满足某条件时才运行代码,否则终止循环的情况,因此其循环次数通常是未知的。while循环语句的用法为:
while (condition) {
statements
}含义:只要condition的值为TRUE,则一直执行代码statements,直到condition的值为FALSE为止。
j <- 1
while (j <= 10) {
j <- j + 4
}
j
#> [1] 13break和next语句可以提前跳出循环。两者的区别在于:break语句是指直接终止循环,而next语句是指进行下一次循环。
下面代码使用next语句。
s <- 0
for (j in 1:4) {
if (j == 3) next
s <- s + j
}
j
#> [1] 4
s
#> [1] 7由于j取值为3时会进行下一次循环,所以j会遍历完向量(1, 2, 3, 4),即j的最终取值为4。
下面代码使用break语句。
s <- 0
for (j in 1:4) {
if (j == 3) break
s <- s + j
}
j
#> [1] 3
s
#> [1] 3由于j取值为3时会直接终止循环,所以j的最终取值为3。
在控制语句中,如果需要多个条件取“逻辑与”或者“逻辑或”,应当用&&或者||,因为condition只能取标量TRUE或FALSE,不能为逻辑向量。另外,有两个逻辑运算函数(any()和all())常用于控制语句中的condition。给定一个逻辑向量x,如果x的任意一个元素为TRUE,则any(x)的返回值为TRUE,只有所有元素均为FALSE,才会返回FALSE;只有x的所有元素均为TRUE,all(x)的返回值才为TRUE,任意一个元素为FALSE,all(x)便会返回FALSE。
set.seed(123)
x <- rbinom(3, size = 1, prob = 0.9)
y <- rbinom(3, size = 1, prob = 0.9)
if (any(x == 0) || any(y == 0)) print("Zero encountered!")
#> [1] "Zero encountered!"某些复杂的统计计算经常用到循环语句,如果这些计算非常耗时,那么,在R运行时,我们并不知道运算进行到了哪一阶段。最简单的解决方法是创建一个计数变量j,并在statements中加入print(j),使得每次循环都会打印出变量j的取值,从而了解程序已经运行了多少次。更好的办法是为程序加入进度条,可以在控制台输入?txtProgressBar打开txtProgressBar()的帮助文档了解添加进度条的方法。
假定有如下向量x:
x <- c(-1, 2, pi, NA)
要求先对x的每一个元素取绝对值,然后求新向量的均值,最后对均值四舍五入到2位小数。
第一种方法是先对向量x取绝对值并将结果赋值给对象y。然后再对y求均值,并将结果赋值给z,由于y中有缺失值,需要设定参数na.rm = TRUE。最后,对z四舍五入到2位小数时需设定round()函数的参数digits = 2。
y <- abs(x) z <- mean(y, na.rm = TRUE) r <- round(z, digits = 2) r #> [1] 2.05
这种方法的缺点在于产生了一些不重要的中间对象,如y和z。第二种方法是将3个函数嵌套起来。
round(mean(abs(x), na.rm = TRUE), digits = 2) #> [1] 2.05
这种方法的代码需要从“内”向“外”阅读。如果嵌套的函数较多,或者函数有很多参数需要设定,那么这种代码书写方式很容易让人读不懂。
第三种方法是利用R包magrittr提供的一种称为管道操作符(%>%)的运算工具[11]。
[11] 2021年5月18日发布的R 4.1.0版本开始新增内置的管道操作符(|>)。可以在RStudio的菜单栏Tools→ Global Options→Code→Editing→Use native pipe operator, |> (require R 4.1+)来选择采用内置管道操作符(|>)。由于已经存在大量基于magrittr管道操作符(%>%)的代码,而代码风格很难短时间内改变,因此本书依然采用(%>%)形式的管道操作符。管道操作符的RStudio快捷键为Ctrl + Shift + M。
library(magrittr) x %>% abs() %>% mean(na.rm = TRUE) %>% round(digits = 2) #> [1] 2.05
%>%能够将左边的对象作为输入参数传递给右边的函数。对于只有一个参数的函数abs()而言,x %>% abs()等同于abs(x);对于有多个参数的函数mean()而言,%>%将左边的对象传递给右边的mean()作为第一个参数,即abs(x) %>% mean(na.rm = TRUE)等价于mean(abs(x), na.rm = TRUE)。最后,将此步运行结果再传递给round()作为第一个参数。因此程序最终运行结果与前两种方法相同,但显然利用管道操作符能够避免前两种方法的缺陷。
这个例子体现了%>%的最常见应用场景:将一类复杂的串行任务分解为多个简单任务,每一个简单任务都可以用一条代码解决,然后用%>%将每条代码按步骤连接起来便可完成复杂任务。
另外,如果不想将左边对象作为函数的第一个参数,可以用英文句号(.)作为函数某参数的占位符,从而将左边对象传递给右边函数作为.参数。如下代码以企鹅数据集中的body_mass_g为被解释变量,以flipper_length_mm和sex为解释变量建立二元线性回归模型。其中,lm()是用OLS拟合线性回归模型的函数,summary()用于查看模型拟合结果。
reg_model <- penguins %>% lm(body_mass_g ~ flipper_length_mm + sex, data = .) summary(reg_model) #> #> Call: #> lm(formula = body_mass_g ~ flipper_length_mm + sex, data = .) #> #> Residuals: #> Min 1Q Median 3Q Max #> -910.28 -243.89 -2.94 238.85 1067.73 #> #> Coefficients: #> Estimate Std. Error t value Pr(>|t|) #> (Intercept) -5410.300 285.798 -18.931 < 2e-16 *** #> flipper_length_mm 46.982 1.441 32.598 < 2e-16 *** #> sexmale 347.850 40.342 8.623 2.78e-16 *** #> --- #> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 #> #> Residual standard error: 355.9 on 330 degrees of freedom #> (11 observations deleted due to missingness) #> Multiple R-squared: 0.8058, Adjusted R-squared: 0.8047 #> F-statistic: 684.8 on 2 and 330 DF, p-value: < 2.2e-16
tibble和magrittr都是tidyverse的组成部分[12]。这两个R包也体现了tidyverse的两个主要优势:
[12] 虽然magrittr是tidyverse的非核心包,但其中的管道操作符已经被几个核心包封装,因此只需要加载tidyverse便可使用%>%。
(1)所有tidyverse构成包的主要函数都以tibble为输入和输出,保持了数据结构的一致性;
(2)整套工作流程以操作符%>%连接,使得代码简洁、清晰可读。
➢ 知识点
• %>%的用法:将左边的对象作为输入参数传递给右边的函数。
○ 做第一个参数(最常见用法)。
■ x %>% f() ⇔ f(x)。
■ x %>% f(y) ⇔ f(x, y)。
○ 做“ . ”参数:y %>% f(x, . , z) ⇔ f(x, y, z)。
前面提到R中没有提供求众数的函数,但可以根据众数的定义编写几行代码来完成任务。
假定有如下向量x。
x <- c(11, 12, 13, 12, 11)
table()可以求出各值出现频数的列联表。
tab <- table(x) tab #> x #> 11 12 13 #> 2 2 1
tab为一个命名向量,其中2、2和1为各元素的取值,11、12和13为各元素的名称,表示在向量x中11出现了2次,12出现了2次,13出现了1次。
which()能够求出一个逻辑型向量中取值为TRUE的元素的下标。如下代码将tab中最大值的下标赋值为ind。
ind <- which(tab == max(tab)) ind #> 11 12 #> 1 2
注意向量ind的取值为1和2,而11和12为元素名称。最后用此下标提取tab中的元素。
tab[ind] #> x #> 11 12 #> 2 2
如果求众数是你经常需要做的一项操作,那么以上代码可能经常需要复制、粘贴。对于常用任务,最好的方法是自己编写一个函数。在R中定义一个函数时,其结构看起来大致如下:
function_name <- function(arg1, arg2, ...){
statements
return(object)
}其中,function_name是自定义的函数名;function()的括号内是函数所需要输入的参数(argument)。两个大括号{}内部称为函数体,包括完成一项任务的代码statements,以及用return()设定的函数返回值。
将前面求众数的代码封装至一个名为my_mode()的函数中。
my_mode <- function(x){
tab <- table(x)
ind <- which(tab == max(tab))
mod <- tab[ind]
return(mod)
}在控制台运行以上产生自定义函数的代码之后,函数my_mode()就可以像R自带函数一样进行调用。
为演示此自定义函数的用法,需要先产生一组数据。从λ取值为5的泊松分布中产生20个随机数记为向量a。
set.seed(1234) a <- rpois(20, lambda = 5) a #> [1] 2 6 5 6 7 6 1 3 6 5 6 5 4 8 4 7 4 4 3 3
调用my_mode()求出a的众数。
my_mode(x = a) #> 6 #> 5
这表明a的众数为6,且众数共出现了5次。
调用函数时若不指定参数名,则按参数位置进行匹配。由于my_mode()只有一个参数x,因此以上代码也可以简写为my_mode(a)。
在实际编写函数时,通常需要返回多个对象。例如,在求众数的例子中,我们既想知道众数是多少又想知道众数出现的次数。由于R函数只能返回一个对象,因此可以将众数及其出现次数打包为一个列表,然后返回此列表。
my_mode2 <- function(x){
tab <- table(x)
ind <- which(tab == max(tab))
mod <- tab[ind]
mode <- as.numeric(names(mod))
freq <- as.numeric(mod)
list(mode = mode, frequency = freq)
}以上函数中没有用return()来返回值, R会默认返回最后一行代码的值。
set.seed(4321) b <- rpois(20, lambda = 5) b #> [1] 4 8 4 2 7 6 7 8 5 5 9 2 4 6 5 4 8 2 3 2 my_mode2(b) #> $mode #> [1] 2 4 #> #> $frequency #> [1] 4 4
这表明b的众数为2和4,这两个数值均出现了4次。由于my_mode2()返回的是一个列表,因此可以采用列表的下标系统提取列表元素。
my_mode2(b)$mode #> [1] 2 4
这个例子中的函数只有一个参数,实际上大部分函数都有多个参数。函数的参数大体上可以分为两类:数据以及控制计算过程的细节。为了使自定义的函数便于管道操作,建议数据参数放在前面,细节参数放在后面,且一般都有默认值。例如,可以将1.5节中的代码封装为一个函数。
my_fun <- function(x, digits = 2, na.rm = FALSE){
x %>%
abs() %>%
mean(na.rm = na.rm) %>%
round(digits = digits)
}其中的x是需要操作的数据参数,digits和na.rm为细节参数。x没有设定默认值,这类参数是调用函数时必须设定的参数。而digits = 2和na.rm = FALSE表示digits的默认值为2和na.rm的默认值为FALSE,在调用函数时如果不设定这两个参数,就会采用它们的默认值。
x <- c(-1, 2, pi, NA) my_fun(x) #> [1] NA my_fun(x, digits = 4, na.rm = TRUE) #> [1] 2.0472
R中有很多函数,例如sum()和c(),都有一个特殊的参数,即...,它能够捕获任意数量的未匹配参数。
sum(1, 3, NA, 5, na.rm = TRUE) #> [1] 9 c(1, 3, NA, 5) #> [1] 1 3 NA 5
➢ 知识点
函数由以下3部分组成。
• 函数名:一般为动词,能够简短又清楚地描述函数的作用。
• 参数:函数所需输入,也称为名义参数。
○ 多分为两类:数据以及控制计算过程的细节。
○ 为便于管道操作,建议数据参数放在前面,细节参数放在后面,且有默认值。
○ 运行函数时若不指定参数名,则按参数位置进行匹配。
• 函数体:{完成一项任务的代码} 。
○ 函数通常返回最后一个语句的值。
○ 如果要返回多个对象,将其打包为列表。
实际工作中,通常采用RStudio项目(project)来完成一项任务。
(1)创建一个RStudio项目。
依次单击菜单栏File→New Project→New Directory→New Project,打开New Project对话框。在对话框中填写项目文件夹名称及其所在目录,见图1-6。在单击Create Project按钮后,会打开一个新的RStudio对话框,同时会在E:/rproj下创建一个名为r4ds的文件夹作为项目目录,并在此目录下自动创建一个名为r4ds.Rproj的项目文件。
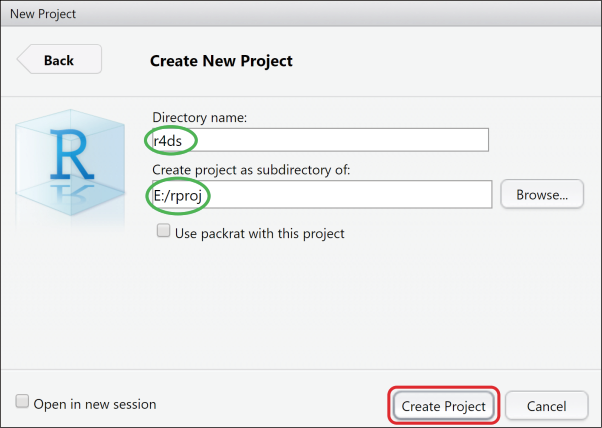
图1-6 新建RStudio项目
(2)新建一个R脚本,并在R脚本中输入代码进行工作。
依次单击菜单栏File→New File→R Script,打开R脚本窗口,在脚本窗口输入以下代码并运行[13]。
[13] 在脚本中运行某一行代码需要将光标放在该行,然后利用RStudio快捷键(Ctrl + Enter);如果要运行多行代码,需要选中这些代码后再用快捷键。撤销脚本中上一次操作的RStudio快捷键为Ctrl + Z,反撤销的快捷键为Ctrl + Shift + Z。
pacman::p_load(tidyverse, palmerpenguins)
ggplot(penguins) +
geom_point(aes(bill_length_mm, bill_depth_mm, color = species))
ggsave("mypic.png")此处用ggplot做出一幅统计图形,并将其保存为mypic.png,模拟了一次简单的数据科学任务。工作完成后可以关闭RStudio。
打开项目文件所在目录,除了项目文件(r4ds.Rproj),你还会发现一个历史命令文件(.Rhistory)和一个输出的图形文件(mypic.png)。双击项目文件r4ds.Rproj将其打开,会回到上次工作终止的地方,可以继续进行工作。
工作目录(working directory),即文件系统中的一个文件夹,与特定工作相关的所有文件都放在此工作目录中,包括数据、R脚本、分析结果以及图形等输出结果。RStudio在控制台左上方显示的路径便是当前工作目录路径[14],见图1-7。
[14] 也可以通过getwd()来得到当前工作目录。setwd()可以将工作目录修改为其他文件夹,其对应的菜单式操作为:Session → Set Working Directory → Choose Directory…。

图1-7 工作目录路径
可见,利用RStudio项目进行数据科学工作的主要优点如下。
(1)便于管理各种文件:项目文件夹被自动设置成当前工作目录。
(2)便于后续工作:关闭RStudio会话之后,重新打开项目文件,会回到上一次操作的R脚本。
练习4:创建一个RStudio项目,并新建一个R脚本文件。在学习本书的同时在脚本窗口中输入本书的所有代码,并查看运行结果。
好的编程风格会使你编写的代码更易于理解。最好从初学R时就养成良好的编程习惯,并保持自己的编程风格一致。本节介绍Wickham(2016)中推荐的编程风格。
如果创建的对象较多,或者需要用多个单词让对象名具有描述性,那么对象名最好遵循某种命名规则。下面是两种推荐命名规则。
• snake case:所有单词均小写,单词间用下画线(_)分隔,如hadley_uses_snake_case。
• camel case:首单词均小写,其他单词仅首字母大写,单词间无分隔符,如othersUseCamelCase。
变量名尽量是名词,而函数名尽量为动词,最好是简洁而有意义的名称。另外,建议对象名中不要用点(.),尤其是自定义函数的名称。还应尽量避免使用现有函数名或保留字符来为新对象命名。以下3个例子所代表的情况应该尽量避免,原因在于,T和F是逻辑值TRUE和FALSE的缩写,c()和sum()都是已存在的函数。
T <- FALSE c <- 5 sum <- function(x) mean(x)
所有中缀运算符(包括+、=、<-、%>%等)的两边使用空格[15]。
[15] 在RStudio中使用<-和%>%的快捷键,会自动在<-和%>%的左右两端加上空格。
my_work_flow <- my_fun(x, digits = 4, na.rm = TRUE)
小括号两边加空格,函数调用除外。
if (x == 1) print(x) for (j in 1:5) print(j)
逗号前面不加空格,后面加一个空格。
b <- c(1, 2, 3)
:和::两边不需要空格。
a <- 1:5 ggplot2::economics
为了对齐等号或赋值符,可以使用额外的空格。
list( total = x + y + z average = (x + y + z) / n )
二维及以上数据结构的下标系统中,省略的位置要加空格。
m[2, ]
if、while以及function的后面通常会有一对大括号{}。左边的大括号不能独占一行,它后面应该新起一行。右边的大括号应该独占一行,除非它后面是else。大括号内的代码要缩进,且缩进时使用两个空格(尽量不要使用Tab键),这样通过左侧的空白就可以很容易地知道代码的层次。
my_fun2 <- function(x) {
print(x)
}
for (i in 1:5) {
for (j in 6:10) {
cat("i + j =", i + j, "\n")
}
}R中的注释符为#,且只有行注释而没有块注释。每行的注释都应该以注释符(#)和一个空格开始。在R脚本中使用RStudio快捷键Ctrl + Shift + R可以打开插入注释行的窗口(见图1-8),利用注释行可以将大量代码分割成容易理解的代码块。
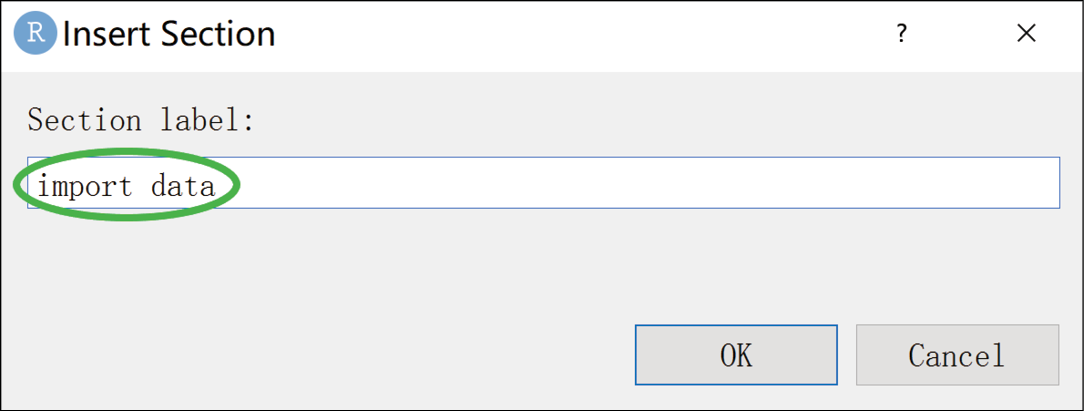
图1-8 插入注释行窗口
例如,可以利用如下3行注释将代码分割为数据导入、数据整理和数据变换3部分。
# import data ------------------ # tidy data -------------------- # transfrom data ---------------
学会在遇到问题时获取帮助是学习R的重要技能。下面根据经常遇到的3类问题来介绍如何获取并利用外部资源。
(1)我知道我想要做什么,但是不知道用哪些R包可以实现。
在网站R documentation中能够非常方便、快捷地搜索发布在CRAN和Bioconductor上的R包及其函数,搜索到的信息包括R包的简介、安装方法、函数的用法及例子等。
还有一种搜索方法是使用R包packagefinder,它提供了一个RStudio插件(Addins),能够非常方便地搜索发布在CRAN上的R包。安装完packagefinder之后,单击RStudio菜单栏下面的Addins下拉按钮,并选择packagefinder(见图1-9),之后会弹出R包搜索窗口。在下拉文本输入框内输入要搜索的英文关键词(例如,若要学习面板数据模型,可以输入panel data model),单击Search按钮就会在窗口下面显示出相应的R包及其相似性得分等(见图1-10)。
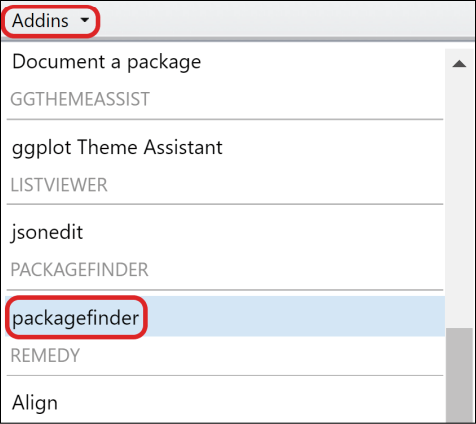
图1-9 RStudio插件所在位置
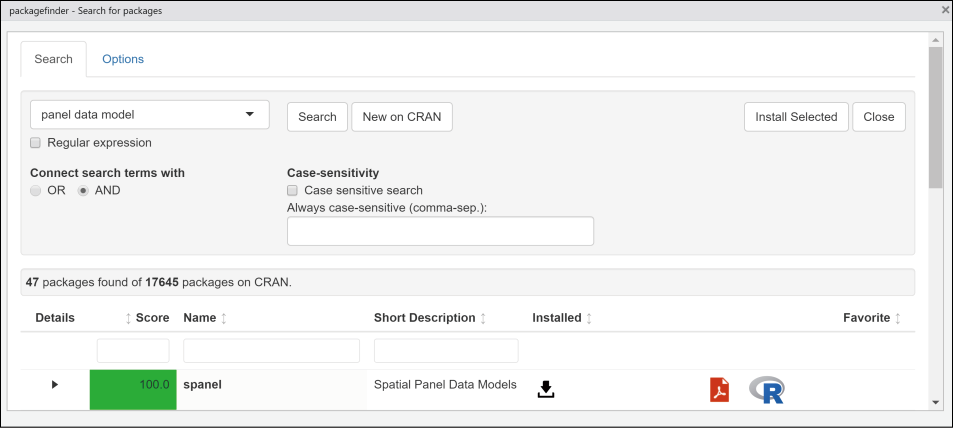
图1-10 R包搜索窗口
(2)我知道哪个R包能解决问题,但不知道如何学习这个R包。
假定想要学习专门用于线性面板数据模型的R包plm。
library()除了能够加载R包,还可以通过设定其参数help查看R包的基本信息。
library(help = "plm")
基本信息中有3部分最有用。
• URL:通常为R包的主页,可以在主页学习包的用法。
• 索引:包中所包含的函数和数据的简要信息。
• 说明文档(vignette):有些较为成熟的R包会有一些说明文档来介绍此R包中的重要概念以及函数的用法。
vignette()可用于查看某R包中包含哪些说明文档,也可以用于查看具体的说明文档。
vignette(package = "plm")
vignette("plmPackage", package = "plm")(3)我知道用哪个函数来解决问题,但我忘了这个函数如何使用、有哪些参数。
可以用help()来打开函数的帮助文档。
help(plm)
还有一种简单的方式是使用问号(?)。如果想要查看某种运算符的帮助文档,需要把运算符用双引号括起来。
?plm ?"%>%"
帮助文档最上面显示了这个函数的名称及其所属的R包,例如plm()帮助文档中左上角的plm {plm}表示函数plm()属于plm包,其中大括号{}内为R包的名称。下面包括函数功能的描述、用法、参数、细节、返回值及例子等。
RStudio是非常成熟的IDE,为用户学习R提供了很多帮助,比如打开RStudio界面右侧的Help窗口并单击小房子按钮,会打开有关R的很多帮助资源,其中最有用的是CRAN Task Views和RStudio Cheat Sheets部分,见图1-11。CRAN Task Views页面按照任务将R包进行了分类;而RStudio Cheat Sheets页面提供了Posit公司制作的一些常用包的速查表,这些速查表也可以通过单击菜单栏Help → Cheatsheets来打开。
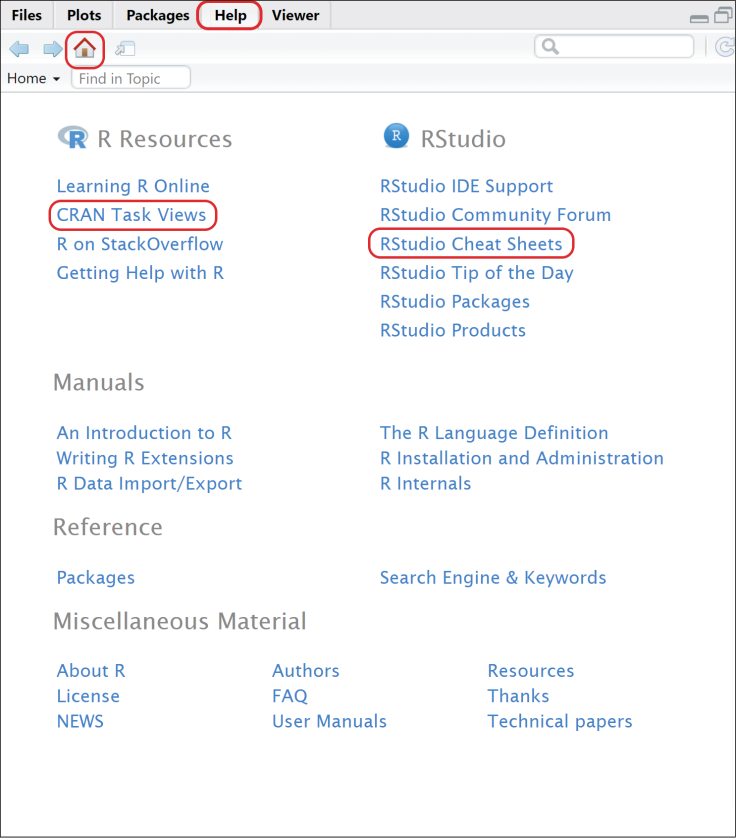
图1-11 RStudio自带的帮助资源
R的主版本每年更新一次,次版本每年也会发布两三个,要想应用R的最新功能就要定期更新自己计算机中的R版本。R的版本更新需要使用R包installr中的函数updateR(),代码如下:
pacman::p_load(installr) updateR()
然后根据弹出的窗口提示完成R的版本更新。
RStudio和R包的更新较为简单,只需要重新安装。单击RStudio菜单栏Help → Check for Updates,可查看当前最新的RStudio版本;单击RStudio菜单栏Tools→Check for Package Updates,可查看有哪些可更新的R包。
R包formatR能够对R代码进行格式化、整洁化,以增加代码的可读性,这对初学者学习并养成良好的编程风格非常有用。尤其是此包提供了基于shiny的GUI(图形用户界面),能够将自己的代码非常方便地转换为看起来比较专业而又整洁的代码。
练习1
y <- c(1, NA, -2, NA, 7) is.na(y) # 判断y是否为缺失值NA,返回同长度的逻辑型向量 #> [1] FALSE TRUE FALSE TRUE FALSE y[!is.na(y)] # 返回y中的非NA元素 #> [1] 1 -2 7
练习2
x <- c(1, 2, NA, 3) y <- c(1, 2, NULL, 3) length(x) #> [1] 4 length(y) #> [1] 3 mean(x) #> [1] NA mean(y) #> [1] 2
缺失值NA是指这里有一个值(所以x的长度为4),但不知道这个值是多少(所以也不知道x的均值是多少)。
空值NULL是指这里什么都没有(所以y的长度为3,且可以直接求y的均值)。
练习3
(1)标准正态分布的上2.5%分位点:
qnorm(0.025, lower.tail = FALSE) #参数lower.tail用于设定是左尾还是右尾 #> [1] 1.959964 qnorm(0.975) #> [1] 1.959964
(2)标准正态分布随机变量X取值大于1.96的概率:
pnorm(1.96, lower.tail = FALSE) #> [1] 0.0249979 pnorm(-1.96) #> [1] 0.0249979
(3)标准正态分布的密度函数在(-2, -1.99, …,-0.01, 0, 0.01, …, 1.99, 2)处的取值:
x <- seq(from = -2, to = 2, by = 0.01) y <- dnorm(x)
(4)来自χ2(5)(自由度为5的卡方分布)的10个随机数:
rchisq(10, df = 5) # 参数df用于设定自由度(degree of freedom) #> [1] 11.030657 3.058415 5.854305 3.724335 2.903232 4.882625 1.989249 #> [8] 9.497231 1.944263 7.838689
(5)t (100)(自由度为100的t分布)的下2.5%分位点:
qt(0.025, df = 100) #> [1] -1.983972





