
详情
计算机系统是计算机专业的常见课程,也是学习编程中的重要一环。本书为计算机系统的入门图书,介绍了现代计算机系统的主要硬件和软件。本书按抽象层次设置各章节,前半部分从常用于编写操作系统的C语言基础知识逐步衍生,介绍了现在计算机的组成、结构、操作系统原理、汇编语言,后半部分介绍了各种架构的代码优化方法、使用共享内存实现并行计算、多核CPU环境下的内存管理等。
本书适合作为计算机系统相关课程的参考教材,也适合有编程基础的人拓展阅读。

书名:深入解析计算机系统
ISBN:978-7-115-63815-1
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
著 [美] 苏珊娜·J. 马修斯(Suzanne J. Matthews)
蒂亚·纽霍尔(Tia Newhall)
凯文·C. 韦布(Kevin C. Webb)
译 李玉博 王艺铭
责任编辑 郭泳泽
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线:(010)81055410
反盗版热线:(010)81055315
Copyright © 2022 by Suzanne J. Matthews, Tia Newhall, and Kevin C. Webb. Title of English-language original: Dive into Systems, A Gentle Introduction to Computer Systems, ISBN 9781718501362, published by No Starch Press Inc. 245 8th Street, San Francisco, California United States 94103. The Simplified Chinese-edition Copyright © 2026 by Posts and Telecom Press Co., Ltd under license by No Starch Press Inc. All rights reserved.
本书中文简体字版由No Starch Press Inc.授权人民邮电出版社独家出版。未经出版者书面许可,不得以任何方式复制或抄袭本书内容。
版权所有,侵权必究。
计算机系统是计算机专业的常见课程,也是学习编程过程中的重要学习内容。本书是计算机系统的入门图书,介绍了现代计算机系统的主要硬件和软件。本书按抽象层次设置各章节,从常用于编写操作系统的C语言的基础知识逐步衍生,先介绍现代计算机的组成、结构、操作系统原理、汇编语言,再介绍各种计算机体系结构的代码优化方法、使用共享内存实现并行计算、多核CPU环境下的内存管理等。
本书可以用作计算机系统入门课程的教材,也可作为操作系统、计算机体系结构、编译器、计算机网络、数据库、并行计算等进阶课程的参考用书。
在当今数字化时代,计算机系统已成为我们生活中不可或缺的一部分。从个人计算机到超级计算机,从智能手机到物联网设备,计算机系统无处不在,而且每时每刻都在影响我们的生活和工作方式。与计算机打交道的人越多,就有越多的人尝试深入理解计算机系统。
本书以通俗易懂的语言,从C语言基础知识出发,介绍了汇编语言、计算机组成原理,并以此为基础详细讲解了代码分析及优化、并行计算及分布式系统,为读者呈现了一幅完整而清晰的计算机系统全景图。与传统计算机类教材相比,本书的魅力在于不仅介绍了多款实用工程工具(如内存分析工具、编译工具等),还涉及安全方面的知识,展示了诸如溢出等经典问题的相关案例及其背后的原理。
本书主要由李玉博、王艺铭翻译。宋墨文、王祉豫、崔磊、王玮也参与了本书的翻译和审校工作。我们既有对计算机系统的热爱,又有对知识传播的热忱,希望通过我们的努力,让更多的读者(尤其是计算机专业的学生和从业者)轻松地阅读并理解本书。
对于本书的翻译,我们秉持了“信、达、雅”这一经典准则。在准确传达作者意图和观点的基础上,兼顾译文的通顺流畅。在具体翻译方法上,我们参考了英国翻译理论家彼得·纽马克(Peter Newmark)的观点,根据原文特征将其归类为信息型文本,采用交际翻译策略,尽可能使译文与原文的阅读体验接近。对于本书中出现的专业术语,我们不仅参考了相关工具书,也参考了《计算机组成原理》《C Primer Plus(第6版)中文版》等经典读物,以争取使译文符合计算机专业读者的阅读习惯。
感谢所有在翻译过程中给予我们帮助和支持的人,尤其是计算机专业和翻译专业的朋友们,他们的专业建议让我们受益匪浅。由于译者水平有限,书中难免存在翻译欠妥的地方,敬请读者批评指正。
李玉博 王艺铭
2025年2月于北京
我们想要感谢以下人员。因为他们的帮助,本书才得以完成。
本书的每一章都经过了几位计算机科学教授的专家评审。我们非常感谢那些担任正式审稿人的教师。你们的洞察力、提出的建议,再加上投入的时间,提高了本书的严谨性和精确性。具体而言,我们要感谢以下各位的贡献:
Jeannie Albrecht(威廉姆斯学院)、John Barr(伊萨卡学院)、Jon Bentley及Anu G. Bourgeois(佐治亚州立大学)、Bill Jannen(威廉姆斯学院)、Ben Marks (斯沃斯莫尔学院)、Alexander Mentis(西点军校)、Rick Ord(加州大学圣地亚哥分校)、Martina Barnas(印第安纳大学布卢明顿分校)、David Bunde(诺克斯学院)、Stephen Carl(西沃恩南方大学)、Bryan Chin(加州大学圣地亚哥分校)、Amy Csizmar Dalal(卡尔顿学院)、Debzani Deb(温斯顿-塞勒姆州立大学)、Saturnino Garcia(圣地亚哥大学)、Tim Haines(威斯康星大学)、Joe Politz(加州大学圣地亚哥分校)、Brad Richards(普吉特海湾大学)、Kelly Shaw(威廉姆斯学院)、Simon Sultana(弗雷斯诺太平洋大学)、Cynthia Taylor(欧柏林学院)、David Toth(森特学院)、Bryce Wiedenbeck(戴维森学院)、Daniel Zingaro(多伦多大学密西沙加分校)。
2018年秋季,本书的alpha版本在西点军校试用。2019年春季,西点军校和斯沃斯莫尔学院试用了本书的beta版。2019年秋季,本书推出了“早期用户计划”,使美国各地的教师能够在各自的院校试用稳定版本。早期用户计划对我们有很大的帮助,因为它帮助我们深入了解了学生和教师使用本书的宝贵经验。我们利用收到的反馈意见来改进和加强本书的内容,非常感谢每一位帮助我们调查的师生。
以下人员在2019年秋季至2020年春季学年期间,在其所在院校使用了本书作为教科书:
John Barr(伊萨卡学院)、Chris Branton(杜利大学)、Dick Brown(圣奥拉夫学院)、David Bunde (诺克斯学院)、Doug MacGregor(西科罗拉多大学)、Jeff Matocha(沃希托浸会大学)、Keith Muller(加州大学圣地亚哥分校)、Crystal Peng(帕克大学)、Bruce Char(德雷塞尔大学)、Vasanta Chaganti(斯沃斯莫尔学院)、Bryan Chin(加州大学圣地亚哥分校)、Stephen Carl(西沃恩南方大学)、John Dougherty(哈弗福德学院)、John Foley(史密斯学院)、Elizabeth Johnson(泽维尔大学)、Alexander Kendrowitch(西点军校)、Bill Kerney(克洛维斯社区学院)、Deborah Knox(新泽西学院)、Leo Porter(加州大学圣地亚哥分校)、Lauren Provost(西蒙斯大学)、Kathleen Riley(布林莫尔学院)、Roger Shore(高点大学)、Tony Tong(惠顿学院马萨诸塞分校)、Brian Toone(桑福德大学)、David Toth(森特学院)、Bryce Wiedenbeck(戴维森学院)、Richard Weiss(长青州立大学)。
 在当今世界,学习编程备受人们重视,编程被奉为人生成功的金钥匙。尽管有许多编码训练营,小学也在教授编程知识,但计算机本身往往被视为次要的事情——在培养下一代计算机科学家的讨论中,计算机正变得越来越无足轻重。
在当今世界,学习编程备受人们重视,编程被奉为人生成功的金钥匙。尽管有许多编码训练营,小学也在教授编程知识,但计算机本身往往被视为次要的事情——在培养下一代计算机科学家的讨论中,计算机正变得越来越无足轻重。
本书旨在为读者提供一本简单、清晰且易于理解的计算机系统入门读物。为了编写出有效的程序,程序员必须了解计算机的底层子系统和体系结构。本书力求使所有人都能够了解计算机系统概念。本书特别适合已具备计算机科学入门知识、对Python有一定了解的学生阅读。如果你正在寻找一本书来为你介绍Python中的基本计算机原理,我们建议你先阅读How To Think Like a Computer Scientist with Python。
本书旨在对计算机系统的相关主题进行简单、清晰的介绍,包括C编程、计算机体系结构基础、汇编语言和多线程。将计算机系统比喻为海洋非常合适。正如人们认为现代生命起源于原始海洋的深处一样,现代编程也源自早期计算机体系结构的设计和构建。初代程序员通过研究第一台计算机的硬件图纸,从而创建了第一个程序。
然而,随着生命(和计算机)开始远离其诞生的海洋,海洋开始被视为一个可怕和危险的地方,那里住着怪物。古代航海者习惯将海怪和其他神话生物的图片放置在未知的水域中,并标注文字警告“这里有海怪”。同样,随着计算机越来越远离其机器级别的起源,有关计算机系统的话题也变成了许多计算机专业学生心中的“海怪”。
在撰写本书的过程中,我们希望鼓励学生慢慢地深入计算机系统相关主题。尽管从表面看,海洋可能是一个黑暗而危险的地方,但对于那些勇于潜入海面之下的人来说,那里有一个美丽而令人惊叹的世界。同样,通过深入研究代码背后的体系结构,学生可以对计算机有更深入的了解,从而学会欣赏它。
本书不会将你直接扔进茫茫大海,而是假设你只具备基本的计算机科学知识,旨在帮助你初步了解计算机系统的相关主题。本书涵盖的主题包括C编程、逻辑门、二进制、汇编语言、内存层次结构、线程和并行处理等。我们设计的章节尽可能相互独立,以便广泛适用于各种课程。
最后,我们希望我们的书是一份有生命力的文档,由计算机领域的同行进行评审,并随着计算机领域的持续发展而不断演变。如果你有任何反馈意见,请与我们联系。我们很乐意听到你的意见!
本书涵盖了与计算机系统相关的主题,范围十分广泛,特别适用于计算机系统导论、计算机组成导论等中级课程。此外,本书还可以为操作系统、编译器、并行和分布式计算以及计算机体系结构等高级课程提供背景资料。
本书并非全面介绍所有计算机相关主题。它不包括对某些主题(如操作系统、计算机体系结构或并行和分布式计算)的深入讨论或全面介绍,也不可替代专门用于高级课程的教材。相反,它侧重于介绍计算机系统、在理解计算机如何运行程序的背景下系统中的常见主题,以及如何设计程序以便在系统中高效运行,为学习更高级的系统主题提供公共知识库和技能集。
本书的主题可以视为计算机的分层切片。在最底层,我们讨论程序的二进制表示,以及设计用于存储和执行程序的电路,并通过基本门构建一个能够执行程序指令的简单CPU。在接下来的层级,我们介绍操作系统,重点关注操作系统支持运行程序和管理计算机硬件的功能,特别是实现多道程序设计和支持虚拟内存的机制。在最高层,我们介绍C编程语言及其如何映射到底层代码,如何设计高效代码,编译器优化和并行计算。通读全书的读者将对用C(和Pthreads)编写的程序如何在计算机上执行有基本的了解,并在此基础上,知道一些可以改变程序结构以提高程序性能的方法。
虽然从整体来看,本书是对计算机的分层切片,但每一章都尽可能独立编写,以便教师根据自己的特殊需求混合搭配使用。图1是各章的依赖关系图,但章内各节的依赖关系的层次可能没有整个章节那么深。
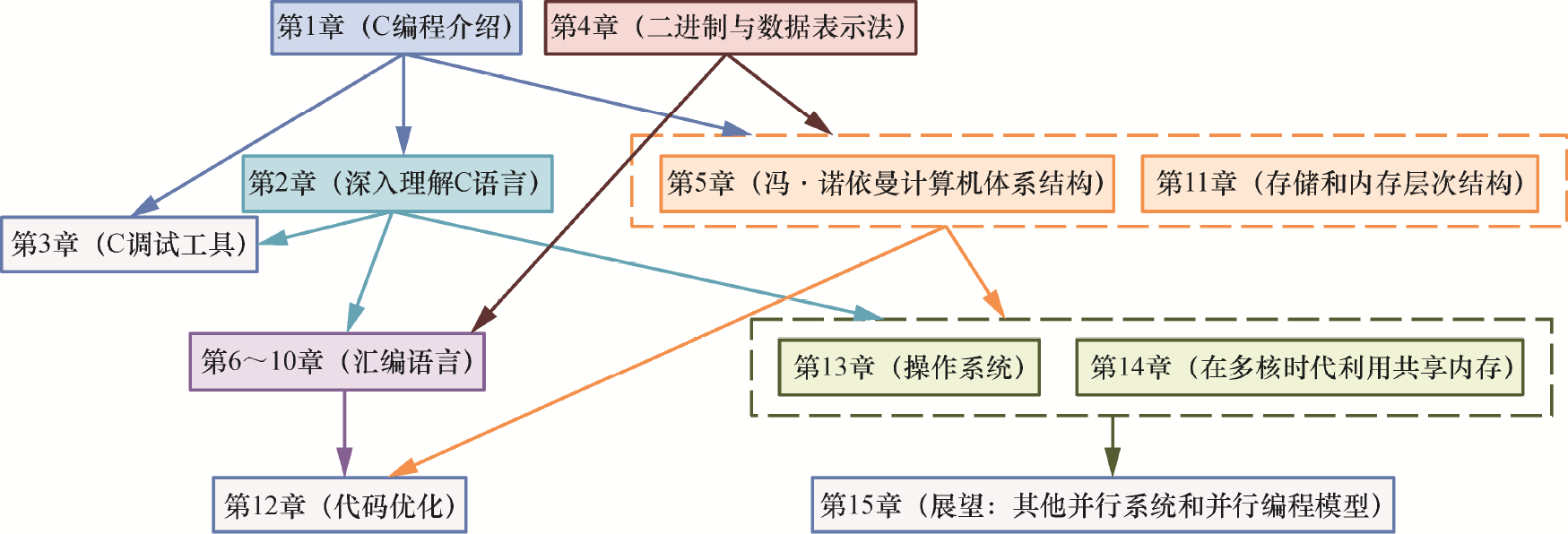
图1 本书各章的依赖关系
第1章介绍C编程基础知识,包括编译和运行C程序。我们假设读者已经接触过某种编程语言的编程入门知识。我们将比较C语法与Python语法的示例,以便熟悉Python的读者了解它们之间的转换关系。然而,阅读或理解本章并不需要具备Python编程经验。
第2章涵盖大部分C语言内容,尤其是指针和动态内存。此外还详细阐述了第1章的主题,并讨论了C语言的一些高级特性。
第3章介绍常用的C调试工具(GDB和Valgrind),并说明它们如何用于调试各种应用程序。
第4章涵盖将数据编码为二进制形式、C类型的二进制表示、二进制数据的算术操作以及算术溢出。
第5章介绍从逻辑门到基本CPU构造的冯·诺依曼计算机体系结构。我们通过算术、存储和控制电路来描述时钟驱动执行和指令执行的阶段。我们还简要介绍了流水线技术、一些现代计算机体系结构特性以及计算机体系结构简史。
第6~10章涵盖从基本算术表达式到函数、栈以及数组和结构体访问的C代码到汇编代码的转换。我们介绍了3种不同指令集体系结构的汇编编程:32位及64位x86汇编编程和ARM汇编编程。
第11章介绍存储设备、内存层次结构及其对程序性能、局部性、缓存的影响,以及Cachegrind性能分析工具。
第12章介绍编译器优化、针对性能设计程序、代码优化技巧以及对程序性能进行量化测量。
第13章介绍操作系统的核心抽象及其背后的机制。我们主要关注进程、虚拟内存和进程间通信。
第14章介绍多核处理器、线程和Pthreads编程、同步、争用条件(race condition)和死锁。该章还包括一些关于测量并行性能(加速比、效率、阿姆达尔定律)、线程安全和高速缓存一致性的高级主题。
第15章介绍分布式内存系统和消息传递接口(MPI),硬件加速器和CUDA,以及云计算和MapReduce的基础知识。
本书可以作为计算机系统主题课程的主要教材,其个别章节也可在涉及更深入主题的其他高级课程中使用,以提供拓展信息。
以作者所在的两所院校为例,我们一直将该书用作以下两门不同的中级课程的主要教材。
• 斯沃斯莫尔学院的“计算机系统导论”课程。章节顺序:4、1、5、6、7、10、2、11、13、14。
• 西点军校的“计算机组成”课程。章节顺序:1、4、2、6、7、10、11、12、13、14、15。
此外,我们还在许多高级课程中将个别章节作为背景阅读材料使用,如表1所示。
表1 高级课程主题和作为背景阅读材料的章节
| 高级课程主题 |
作为背景阅读材料的章节 |
|---|---|
| 计算机体系结构 |
5、11 |
| 编译器 |
6、7、8、9、10、11、12 |
| 数据库系统 |
11、14、15 |
| 网络 |
4、13、14 |
| 操作系统 |
11、13、14 |
| 并行与分布式系统 |
11、13、14、15 |
我们的许多课程都将第2章和第3章作为C编程和调试的参考资料。
本书的免费在线版本(英文)可以通过在互联网上搜索Dive into Systems而获得。
深入探查计算机系统的精彩世界!理解什么是计算机系统,以及计算机系统如何运行程序,可以帮助你设计出高效运行的代码,并将底层系统的功能发挥到极致。在本书中,我们将带你踏上了解计算机系统的旅程。你将学习到以下内容:用高级编程语言(这里我们使用的是C语言)编写的程序如何在计算机上运行,程序指令如何转换为二进制形式及电路如何执行二进制编码,操作系统如何管理运行在系统中的程序,以及如何编写可以利用多核处理器计算机的程序。在整个过程中,你还将学习如何评估与程序代码相关的系统开销以及如何设计出高效运行的程序。
计算机系统是可供用户使用的计算机硬件与软件的结合体。具体而言,计算机系统包含以下组件(见图1)。
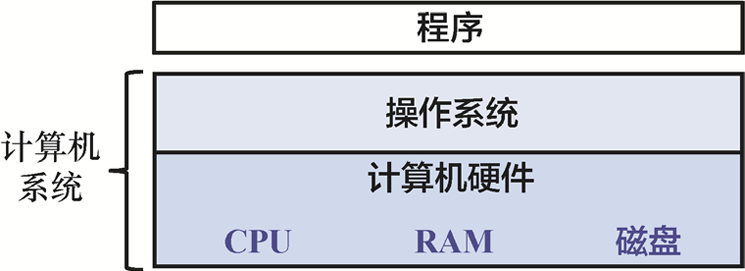
图1 计算机系统的分层组成
• 输入/输出(Input/Output,I/O)端口使计算机能够从其环境中获取信息,并以某种有意义的方式将其显示给用户。
• 中央处理器(Central Processing Unit,CPU)运行指令,并计算数据和内存地址。
• 随机存储器(Random Access Memory,RAM)存储运行程序的数据和指令。RAM中的数据和指令通常会因计算机系统断电而丢失。
• 硬盘之类的辅助存储设备,即使在计算机未供电的状态下也可存储程序和数据。
• 操作系统(Operating System,OS)位于计算机的硬件和用户运行的软件之间。操作系统实现了抽象编程和接口,使用户能够轻松运行系统中的程序并与之交互,还可管理底层硬件资源并控制程序的运行方式和运行时间。操作系统实现了抽象、策略和机制,确保多个程序能够在受保护的状态下,以高效的方式在系统中同时运行。
以上内容的前4项定义了计算机系统的主要硬件部分,最后一项(操作系统)则代表计算机系统的主要软件部分。操作系统之上可能有额外的软件层,旨在为系统用户提供其他接口(例如库)。然而,操作系统是我们在本书中关注的核心系统软件。
我们尤其关注通用计算机系统,这类计算机系统的功能并不局限于任何应用程序。通用计算机系统可重新编程,这意味着其支持在不更改计算机硬件或系统软件的情况下运行不同的程序。
因此,可能许多以某种形式“计算”的设备无法归类于计算机系统范畴。例如,计算器通常具有处理器、有限内存及I/O能力,然而一般没有操作系统(TI-89这样的高级图形计算器显然是个例外),没有辅助存储器,也无法通用。
值得一提的是微控制器,它是一种集成电路,具有许多与计算机相似的功能,通常被嵌入其他设备(如玩具、医疗设备、汽车和电器)以控制特定的自动功能。尽管微控制器是通用的,可重新编程,并包含处理器、内部存储器、辅助存储器且具备I/O能力,但缺乏操作系统。微控制器只在连通电源的情况下,启动和运行单个特定程序,因此不符合我们对计算机系统的定义。
现在,我们已经能够确定什么是计算机系统,什么不是计算机系统。下面我们讨论计算机系统的外观样式。图2展示了两类计算机硬件系统(不包括外围设备):台式机(左图)和笔记本计算机(右图),图中左下角的25美分硬币可以帮助读者了解每个设备的大小。

图2 通用计算机系统:台式机(左)及笔记本计算机(右)
请注意,两者都包含相似的硬件组件,尽管某些组件可能尺寸更小或外形更紧凑。我们将台式机的DVD槽放在一边,以展示出下面的硬盘驱动器——正常状态下这两种设备是堆叠在一起的。专用电源能为台式机提供所需电力。
相比之下,笔记本计算机设计得更轻薄、更紧凑(请注意,图2右图中的25美分硬币看起来更大一些)。这款笔记本计算机内置电池并且组件更小。无论是台式机还是笔记本计算机,CPU上都有一个大大的风扇,这有助于让CPU保持合理的工作温度。如果组件过热,它们可能会永久性损坏。这两种设备的RAM单元都有双列直插式内存组件(Dual In-line Memory Module,DIMM)。请注意,笔记本计算机的内存模块比台式机的内存模块小得多。
在功耗和重量方面,台式机功耗通常为100~400 W,重量在2~10 kg。笔记本计算机功耗通常为50~100 W,重量也要轻很多,并需要外部充电器为电池充电。
计算机硬件正向着更小、更紧凑的设计趋势发展。图3展示的是一台树莓派单板计算机。单板计算机(Single-Board Computer,SBC)是一种将整个计算机集成在单个电路板上的设备。

图3 树莓派单板计算机
树莓派单板计算机包含一个集成了RAM和CPU的系统级芯片(System-on-a-Chip,SoC)处理器,该芯片处理器包含图2所示笔记本计算机和台式机所具有的大部分硬件组件。与笔记本计算机和台式机不同,树莓派单板计算机大致与信用卡的大小相同,重约40 g(约一片面包的重量),功耗约5 W。树莓派单板计算机所采用的SoC技术在智能手机中也十分常见。实际上,智能手机是计算机系统的另一种表现形式。
所有上述计算机系统(包括树莓派单板计算机和智能手机)都具有多核处理器。换句话说,它们的CPU能够同时执行多个程序,称为并行执行。第14章将介绍基本的多核编程。
所有这些不同类型的计算机硬件系统都可以运行一个或多个通用操作系统,如macOS、Windows或UNIX。通用操作系统负责管理底层计算机硬件,并为用户在计算机上运行程序提供接口。这些运行着不同通用操作系统的不同类型的计算机硬件共同构成了一个计算机系统。
读完本书,你将学到如下内容。
计算机如何运行程序。你将能够详细描述用高级程序设计语言表达的程序如何在计算机硬件的低级电路上执行。具体地说,你将学到如下知识:
• 程序数据如何编码为二进制形式,以及计算机硬件如何对二进制编码执行运算;
• 编译器如何将C程序转换为汇编指令和二进制机器码(汇编指令是二进制机器码的可读形式);
• CPU如何对二进制程序数据执行二进制指令,包含从基本逻辑门到存储值、执行计算和控制程序运行的复杂电路的相关内容;
• 操作系统如何实现用户在系统中运行程序的接口,以及如何在管理系统资源的同时控制系统中运行的程序。
如何评估与程序性能相关的系统开销。程序运行缓慢有很多原因,可能是选择了错误的算法,抑或只是程序错误地使用了系统资源。你将了解到内存层次结构(见11.1节)及其对程序性能的影响,以及与程序性能相关的操作系统开销。你还将学到一些有价值的代码优化技巧。最后,你将能够设计可以有效利用系统资源的程序,并知道如何评估与程序执行相关的系统开销。
如何通过并行编程来充分利用并行计算机的强大功能。在当今的多核世界中,利用并行计算非常重要。你将学习如何利用CPU上的多个内核使程序运行得更快。你将了解到多核硬件的基础知识、操作系统的线程抽象以及多线程并行程序执行的相关问题。你将体验并行程序设计,并体验使用POSIX线程库(Pthreads)来编写多线程并行程序。你还将了解其他类型的并行系统和并行编程模型。
在此过程中,你还将学到很多关于计算机系统的其他重要细节,包括它们是如何设计和工作的。你将学习系统设计中的重要主题以及评估系统和程序性能的技术。你还将掌握一些重要技能,包括C语言和汇编语言编程与调试。
关于编程语言、书中符号的注意事项,以及阅读本书的一些建议。
我们在整本书的示例中使用了C语言。C语言与Java和Python一样,都属于高级编程语言,但与其他高级编程语言相比,C语言对底层计算机系统的抽象程度较低。因此,如果程序员想要更好地控制程序在计算机系统中的执行方式,那么C语言是首选语言。
本书中的代码及示例使用GNU C编译器(GNU C Compiler,GCC)进行编译并在Linux系统中运行。虽然Linux系统不是最常见的主流操作系统,但其在超级计算系统中占主导地位,可以说是计算机科学家最常用的操作系统之一。
Linux系统是一种免费且开源的操作系统,这使其在各种场景中得到广泛应用。对于所有计算机专业的学生来说,掌握Linux相关知识无疑是一笔财富。同样,GCC可以说是目前最常用的C语言编译器。因此,我们在示例中使用了Linux和GCC。但是,其他UNIX系统和编译器也具有类似的接口和功能。
在本书中,我们鼓励你按照列出的示例进行输入。Linux命令出现在如下命令提示符后:
$
$表示命令提示符。如果你看到如下文本:
$ uname -a
则表示要在命令行中输入uname -a。确保你没有输入$符号!
命令的输出通常直接显示在命令行列表中的命令之后。例如,尝试输入uname -a。此命令的输出结果因系统而异。此处显示了64位系统的输出示例:
$ uname -a Linux Fawkes 4.4.0-171-generic #200-Ubuntu SMP Tue Dec 3 11:04:55 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
uname命令输出关于特定系统的信息。-a标识按以下顺序输出与系统相关的所有信息:
• 系统内核名称(在这个例子中为Linux);
• 主机名称(例如,Fawkes);
• 内核发行号(例如,4.4.0-171-generic);
内核版本(例如,#200-Ubuntu SMP Tue Dec 3 11:04:55 UTC 2019);
• 机器硬件(例如,x86-64);
• 处理器类型(例如,x86-64);
• 硬件平台(例如,x86-64);
• 操作系统名称(例如,GNU/Linux)。
在命令前加上man,可以了解更多有关uname命令或任何其他Linux命令的信息,如下所示:
$ man uname
此命令会调出与uname命令相关联的手册页面。要退出此页面,请按q键。
对Linux系统的详细介绍超出了本书的讨论范围,但一些在线资源可供读者参考。推荐“LinuxCommand”网站,你可以阅读其第一部分“Learning the Shell”。
除了命令行和代码片段,我们还使用其他几种类型的“标注”来展现本书中的内容。
第一种是补充卡片。补充卡片的意思是为文本提供补充说明,通常是历史事件,如下例所示。
| Linux、GNU和免费开源软件(Free Open Source Software,FOSS)运动的起源 |
| 1969年,AT&T贝尔实验室开发了UNIX系统供内部使用。虽然UNIX系统最初是使用汇编语言编写的,但在1973年使用C语言进行了重写。由于反垄断法案禁止AT&T贝尔实验室进入计算机行业,AT&T贝尔实验室将UNIX系统免费授权给大学,这极大地促进了其广泛应用。然而,到了1984年,AT&T从贝尔实验室分离出来,摆脱了早期的限制,开始将UNIX系统作为商品销售,这让学术界的一些人感到非常愤怒和沮丧。 作为直接回应,Richard Stallman(当时是MIT的一名学生)于1984年发起了GNU项目,旨在创建一个完全由免费软件组成的类UNIX系统。GNU项目孵化出很多成功的免费软件产品,包括GCC、GNU Emacs(一款流行的文本编辑器)以及GNU公共许可(GNU Public License,GPL;也是“copyleft”原则的起源)。 1992年,当时还是赫尔辛基大学学生的Linus Torvalds发布了一个在GPL下编写的类UNIX系统——Linux。Linux(发音为“Li-nux”或 “Lee-nux”,因为Linus Torvald的名字发音为“Lee-nus”)系统是使用GNU工具开发的。现在,GNU工具通常与Linux系统一起打包发行。Linux系统的吉祥物是企鹅Tux。Torvalds在动物园游玩时被一只企鹅咬伤,在对企鹅产生喜爱后,他选择企鹅作为Linux系统的吉祥物,他称这种行为是感染了“企鹅炎症”。 |
我们在文本中使用的第二种标注用于突出显示重要信息,例如某类符号的使用或关于如何理解某些信息的建议。示例说明如下。
| 注意 |
如何阅读本书 作为学生,阅读课本很重要。注意我们所说的“阅读”不是仅仅将课本读一遍,被动地从书本中获取内容。我们鼓励学生采用更积极的方法。如果看到代码示例,尝试输入它!即便输入错误或出现问题也没关系,这是最好的学习方式。在编程中,错误并非失败,而是经验的积累。 |
最后一种需要读者特别关注的标注是警告。我们使用警告来强调常见的“陷阱”或是引起我们的学生惊慌的常见原因。尽管并非所有警告对所有学生都具有相同的价值,但我们建议你查看警告,以尽可能避免常见的陷阱。警告示例如下。
| 警告 |
书中包含双关语 本书的作者(尤其是第一作者)喜欢使用与计算相关的双关语和谐音(不一定做得很好)。对作者幽默感的不良反应可能包括(但不限于)翻白眼、烦恼地叹息和拍打额头。 |
如果你已准备好开始,请继续阅读第1章,我们将深入C语言的奇妙世界。如果你已经了解C语言的一些编程知识,那么你可以从第4章的二进制表示开始,或者阅读第2章继续学习更高级的C编程技术。
希望你和我们一起享受这段旅程!
本书提供如下资源:
• 部分程序源代码文件;
• 本书思维导图;
• 异步社区7天VIP会员。
要获得以上资源,您可以扫描下方二维码,根据指引领取。

作译者和编辑尽最大努力来确保书中内容的准确性,但难免会存在疏漏。欢迎您将发现的问题反馈给我们,帮助我们提升图书的质量。
当您发现错误时,请登录异步社区(www.epubit.com),按书名搜索,进入本书页面,单击“发表勘误”,输入勘误信息,单击“提交勘误”按钮即可(见下图)。本书的作译者和编辑会对您提交的勘误信息进行审核,确认并接受后,您将获赠异步社区的100积分。积分可用于在异步社区兑换优惠券、样书或奖品。
我们的联系邮箱是contact@epubit.com.cn。
如果您对本书有任何疑问或建议,请您发邮件给我们,并请在邮件标题中注明本书书名,以便我们更高效地做出反馈。
如果您有兴趣出版图书、录制教学视频,或者参与图书翻译、技术审校等工作,可以发邮件给我们。
如果您所在的学校、培训机构或企业想批量购买本书或异步社区出版的其他图书,也可以发邮件给我们。
如果您在网上发现有针对异步社区出品图书的各种形式的盗版行为,包括对图书全部或部分内容的非授权传播,请您将怀疑有侵权行为的链接通过邮件发给我们。您的这一举动是对作译者权益的保护,也是我们持续为您提供有价值的内容的动力之源。
“异步社区”是由人民邮电出版社创办的IT专业图书社区,于2015年8月上线运营,致力于优质内容的出版和分享,为读者提供高品质的学习内容,为作译者提供专业的出版服务,实现作译者与读者在线交流互动,以及传统出版与数字出版的融合发展。
“异步图书”是异步社区策划出版的精品IT图书的品牌,依托于人民邮电出版社在计算机图书领域30余年的发展与积淀。异步图书面向IT行业以及各行业使用IT的用户。
本章为具有其他语言编程经验的学生提供C编程概述,且专门为Python程序员编写,并使用一些Python示例作为比较。但是,对于拥有其他语言编程基础的人来说,本章可作为C编程简介来使用。
C是一种高级编程语言,与你知道的其他编程语言(如Python、Java、Ruby或C++)一样。它是一种命令式和过程式编程语言,这意味着C程序表示计算机执行的一系列语句(步骤),由一组函数(过程)构成。每个C程序必须至少有一个函数,即main函数,它包含程序开始时执行的语句集。
与你熟悉的其他编程语言相比,C从机器语言中抽象出的程度很可能更低。这意味着C不支持面向对象编程(而Python、Java和C++支持面向对象编程),不具有丰富的高级编程抽象集(如Python中的字符串、列表和字典)。因此,如果想在C程序中使用字典数据结构,你需要自己去实现,而非只是导入字典数据结构作为编程语言(如Python)的一部分。
由于缺乏高级抽象,C看起来可能并不是一种让人愿意使用的编程语言。然而,由于C对底层机器的抽象程度较低,程序员更容易发现和理解程序代码与计算机执行代码之间的关系。使用C,程序员可以更好地掌控程序在硬件上的执行方式。此外,相较于使用其他编程语言提供的高级抽象所编写出的等效代码,用C编写的代码执行起来更加高效。尤其重要的一点是,C可以更好地控制程序使用内存的方式,这会对程序性能产生重大影响。因此,在需要底层控制和高效运行的场景中,C仍然是计算机系统编程所实际使用的语言。
我们在本书中使用C,是因为C在程序控制方面具有表现力,并且可以相对直接地转换为计算机执行的汇编代码和机器代码。本章在关于C编程的介绍中,只对其特性进行概述,第2章将对其进行更为详细的描述。
让我们从一个“Hello World”程序开始,它包含一个从math库中调用函数的例子。我们将对这个程序的Python版本与C版本进行比较。C版本可能放在名为hello.c的文件中(.c是C源代码文件的约定后缀名),而Python版本可能放在名为hello.py的文件中。
Python版本:
'''
Python版本的“Hello World”程序
'''
#导入Python的math库
from math import*
# main函数定义:
def main():
#语句独占一行
print("Hello World")
print("sqrt(4) is %f" % (sqrt(4)))
#调用main函数
main()C版本:
/*
C版本的“Hello World”程序
*/
/* 导入C的math库和I/O库 */
#include <math.h>
#include <stdio.h>
/* main函数定义: */
int main() {
// 语句以分号(;)结束
printf("Hello World\n");
printf("sqrt(4) is %f\n", sqrt(4));
return 0; // main函数返回int值0
}| 注意 |
C版本和Python版本的“Hello World”程序均支持下载,分别见配套资源的hello.c和hello.py文件。 |
请注意,尽管使用了不同的语言语法,但该程序的两个版本具有相似的代码结构和语法结构。尤其是以下方面。
• 在Python中,多行注释以' ' '开头和结尾,单行注释以#开头。
• 在C中,多行注释以/*开头,以*/结尾,单行注释以//开头。
• 在Python中,使用import包含(导入)库。
• 在C中,使用#include包含(导入)库。所有#include语句都列在程序的顶部,在函数体之外。
• 在Python中,使用缩进表示一个块。
• 在C中,块(如函数、循环和条件体)以{开头,以}结尾。
• 在Python中,def main():定义主函数。
• 在C中,int main(){ }定义主函数。main函数返回一个int类型的值,int是C中用于指定有符号整数(有符号整数是−3、0、1 234之类的值)的数据类型名称。main函数返回int值0以表示程序运行完成且没有错误。
• 在Python中,每条语句都单独占用一行。
• 在C中,每条语句都以分号(;)结尾,语句必须在某个函数体中(本例是在main函数体中)。
• 在Python中,print函数输出一个格式化的字符串。在格式化字符串中,占位符的值在%符号之后,位于以逗号分隔的值列表中(例如,输出sqrt(4)的值,以取代格式化字符串中的%f占位符)。
• 在C中,printf函数输出一个格式化的字符串。在格式化字符串中,占位符的值是由逗号分隔的附加实参(例如,输出sqrt(4)的值,以取代格式化字符串中的%f占位符)。
该程序的C版本和Python版本有如下重要区别需要注意。
在C中,缩进没有意义,但是根据语句包含块的嵌套级别来缩进语句是一种很好的编程风格。
C的printf函数不会像Python的print函数那样在末尾自动输出换行符。因此,如果要输出换行符,C程序员需要在格式化字符串中显式指定换行符(\n)。
• C程序必须有一个名为main的函数,其返回类型必须是int。这意味着main函数返回一个有符号整数类型的值。Python程序不需要将其主函数命名为main,但通常会按照惯例这样命名。
• C程序的main函数用一个显式的return语句来返回一个int值(依照惯例,如果main函数执行成功且没有错误,则main函数应该返回0)。
• Python程序需要包含对其main函数的显式调用,以便在程序执行时运行。而在C中,其main函数在C程序执行时自动被调用。
Python是一种解释型编程语言,这意味着需要用另一个程序(即Python解释器)运行Python程序:Python解释器就像一个运行Python程序的虚拟机。运行Python程序时,程序源代码(hello.py)作为输入提供给Python解释器运行。例如($是Linux shell提示符):
$ python hello.py
Python解释器是一个程序,可以直接在底层系统上运行[称为二进制可执行(binary executable)程序],其将运行的Python程序作为输入(如图1-1所示)。
要运行C程序,首先必须将其转换为计算机系统可以直接执行的形式。C编译器(C compiler)是一种将C源代码转换为计算机硬件可以直接执行的二进制可执行文件的程序。二进制可执行文件由一系列的0和1组成,这些0和1被定义为计算机可以运行的格式。
例如,要在UNIX系统中运行C程序hello.c,C源代码必须先由C编译器(如GCC)编译,该编译器生成二进制可执行文件(默认命名为a.out)。程序的二进制可执行版本可以直接在系统中运行(如图1-2所示):
$ gcc hello.c $ ./a.out
注意,某些C编译器可能需要用户通过-lm显式告知其关联math库:
$ gcc hello.c -lm
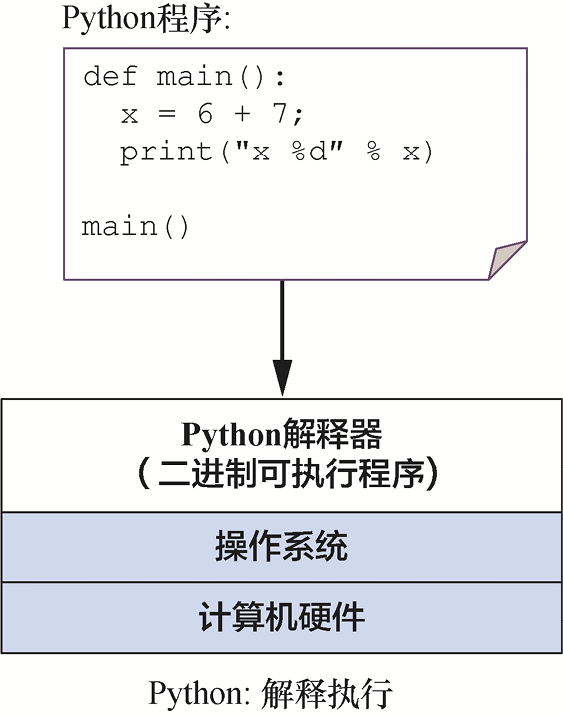
图1-1 Python程序由Python解释器直接执行,Python解释器是运行在底层系统(操作系统和计算机硬件)上的二进制可执行程序
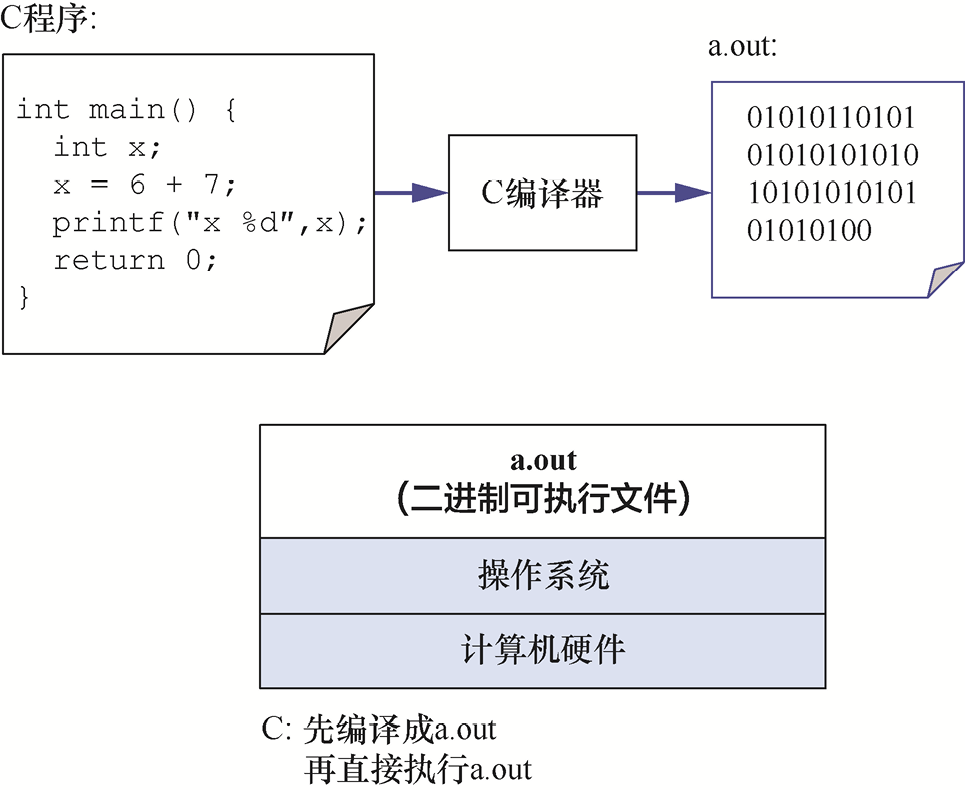
图1-2 C编译器将C源代码编译成二进制可执行文件a.out。底层系统(操作系统和计算机硬件)直接执行二进制可执行文件a.out以运行程序
通常,以下流程描述了在UNIX系统中编辑、编译和运行C程序的必要步骤。
首先,使用文本编辑器(例如vim)编写并保存C源代码至文件(如hello.c)中:
$ vim hello.c
接下来,将C源代码编译为可执行形式,随后运行。使用gcc编译的最基本语法如下:
$ gcc <input_source_file>
如果编译没有产生错误,编译器会创建一个名为a.out的二进制可执行文件。编译器还允许使用-o标志来指定其生成的二进制可执行文件的名称:
$ gcc -o <output_executable_file> <input_source_file>
例如,以下命令指示gcc将hello.c编译成一个名为hello的二进制可执行文件:
$ gcc -o hello hello.c
我们可以使用./hello调用hello可执行程序:
$ ./hello
对C源代码文件(hello.c文件)做任何更改后都必须使用gcc重新编译,以生成新版本的hello可执行程序。如果编译器在编译时检测到任何错误,就不会创建或重新创建hello可执行程序(但要注意,之前编译成功的旧版文件可能仍然存在)。
在使用gcc编译时,通常需要包含一些命令行选项。这些选项会启用更多编译器警告,并构建带有额外调试信息的二进制可执行文件:
$ gcc -Wall -g -o hello hello.c
因为gcc命令行可能很长,所以make实用程序经常用于简化C程序的编译以及清理gcc所创建的文件。使用make和编写Makefile是积累C编程经验时需要精进的重要技能。
我们将在第2章末尾详细介绍如何使用C库代码进行C程序的编译和链接。
与Python一样,C利用变量为保存数据的存储位置命名。程序变量的作用域和类型对于理解程序运行时的语义十分重要。变量的作用域(scope)定义了变量何时有意义(即在程序中何时何地可以使用)及其生命周期(即在程序的整个运行期间持续有效,或仅在函数激活期间有效)。变量的类型(type)定义了变量可以表示的值的范围,以及在对其数据执行操作时如何解释这些值。
在C中,所有变量必须在使用前声明。声明变量时可以使用以下语法:
type_name variable_name;
一个变量只能有一个类型。基本的C类型包括char、int、float和double。按照惯例,C变量应该在其作用域的开头声明(在{ }块的顶部),也就是在该作用域中的任何C语句之前。
以下是一个C代码片段示例,展示了一些不同类型变量的声明和使用。在这个示例之后,我们将详细讨论C类型和运算符。
vars.c
{
/* 1.在块作用域的顶部定义变量 */
int x; // 声明x为int型变量,并为其分配空间
int i, j, k; // 可以同时定义多个类型相同的变量,就像这样
char letter;
// char类型存储单字节整数值,常用于存储单个ASCII值
// C中的字符与字符串是不同的类型
float winpct; // 声明winpct为float型变量
double pi; // double类型比float类型更加精确
/* 2.在声明所有变量后,便可以在C语句中使用它们 */
x = 7; // x存储7(在使用变量的值之前,需要先初始化变量)
k = x + 2; // 在表达式中使用x的值
letter = 'A'; // 单引号用于单字节整数值
letter = letter + 1; // letter存储'B'(ASCII值比'A'的大1)
pi = 3.1415926;
winpct = 11 / 2.0; // winpct为5.5,winpct为float类型
j = 11 / 2; // j为5,整数除法在小数点后截断
x = k % 2; // %是C的取模运算符,所以x是9对2取模的结果,为1
}请注意大量的分号。回想一下,C使用分号而不是换行符来结束语句,因而每个C语句之后都有一个分号。你可能会忘记使用分号,即便这可能是C程序中唯一的语法错误,gcc也几乎从不通知你缺少分号。事实上,当你忘记使用分号时,编译器会在缺少分号的那一行之后的行中指出语法错误,原因是gcc将其解释成了前一行语句的一部分。随着你继续使用C编程,你将学会如何关联gcc中的错误描述与特定的C语法错误。
C支持一少部分内置数据类型,并且提供了一些方法让C程序员可以构造由基本类型组成的类型(如数组和结构体)。通过这些基本的构建块,C程序员可以构建复杂的数据结构。
C定义了一组用于存储数值的基本类型。以下是不同C类型的数值字面量的一些示例:
8 // int值8 3.4 // double值3.4 'h' // char值'h'(其值为104,即'h'的ASCII值)
C的char类型存储一个数字。然而,程序员经常用它来存储ASCII值。字符字面量在C中指定为单引号之间的单个字符。
C不支持字符串类型,但程序员可以使用char类型构建字符串,并且C支持构造char型数组,我们将在之后讨论。然而,C也确实提供了一种在程序中表达字符串字面量的方式:字符串字面量是双引号之间的任何字符序列。C程序员经常将字符串字面量作为格式化字符串参数传递给printf函数:
printf("this is a C string\n");Python支持字符串,但不提供char类型。在C中,字符串和字符是两种截然不同的类型,它们的计算方式也不同。下面通过将包含一个字符的C字符串字面量与C字符字面量进行对比来说明这种差异。
'h' // 这是一个字符字面量(值为104,即'h'的ASCII值) "h" // 这是一个字符串字面量(值不是104,不是一个字符)
我们将在2.6节详细讨论C字符串和char变量。在这里,我们主要关注C数值类型。
C支持使用不同的类型来存储数值。这些类型在它们所表示的数值格式上有所不同。例如,float和double类型可以表示实数值,int表示有符号整数值,unsigned int表示无符号整数值。实数值是带小数点的正值或负值,例如−1.23或0.0056。有符号整数存储正、负或零的整数值,例如−333、0或3 456。无符号整数存储严格的非负整数值,例如0或1234。
C的数值类型在可以表示的值的范围和精度方面也有所不同。值的范围或精度取决于与其类型关联的字节数。与具有较少字节的类型相比,具有更多字节的类型可以表示更大范围的值(对于整数类型)或更高精度的值(对于实数类型)。
表1-1显示了存储字节的个数、内存中存储的数值类型,以及如何声明各种常见的C数值型变量(请注意,这些是典型空间大小,确切的字节数取决于硬件体系结构)。
表1-1 C数值类型
| 类型名 |
常见大小(字节) |
存储的数值类型 |
如何声明 |
|---|---|---|---|
| char |
1 |
整数 |
char x; |
| short |
2 |
有符号整数 |
short x; |
| int |
4 |
有符号整数 |
int x; |
| long |
4或8 |
有符号整数 |
long x; |
| long long |
8 |
有符号整数 |
long long x; |
| float |
4 |
有符号实数 |
float x; |
| double |
8 |
有符号实数 |
double x; |
C还提供整数数值类型(char、short、int、long和long long)的无符号版本。要将变量声明为无符号,可在类型名称前添加关键字unsigned:
int x; // x是一个有符号int变量 unsigned int y; // y是一个无符号int变量
C标准没有指定char类型是否有符号。因此,char类型既可能实现为有符号整数值,也可能实现为无符号整数值。如果使用char变量的无符号版本,则明确声明unsigned char是一种良好的编程习惯。
每种C类型的确切字节数在不同的计算机体系结构下可能有所不同。表1-1中的大小是每种C类型的最小(和常见)值。可以使用C的sizeof运算符输出特定机器上的准确大小,该运算符将C类型的名称作为参数,并计算用于存储该类型所需的字节数。例如:
printf("number of bytes in an int: %lu\n", sizeof(int));
printf("number of bytes in a short: %lu\n", sizeof(short));sizeof运算符的计算结果为无符号长整型值,因此在调用printf函数时,使用占位符%lu输出其值。在大多数计算机体系结构下,这些语句的输出如下:
number of bytes in an int: 4 number of bytes in a short: 2
算术运算符结合操作数的数值类型进行运算。运算的结果类型取决于操作数的类型。例如,如果将两个整数值与算术运算符组合,则结果也是整数值。
当算术运算符组合两种不同类型的操作数时,C会自动执行类型转换。例如,如果int操作数与float操作数组合,则在应用算术运算符之前会先将整数转换为与其等效的浮点数,并且运算结果为float类型。
下列算术运算符可以在大多数数值类型的操作数中使用。
• 加(+)和减(–)。
• 乘(*)、除(/)、取模(%)。取模运算符(%)只能应用于整数类型(int、unsigned int、short等)的操作数。如果两个操作数都是int类型,则除法运算符(/)执行整数除法(结果为int类型,在除法运算中截断小数点后的所有内容),如8/3的计算结果为2;如果一个操作数是float(或double)类型,或二者皆为float(或double)类型,则除法运算符执行实数除法,计算结果为float(或double)类型,如8/3.0的计算结果约为2.666667。
• 赋值(=):
variable = value of expression; // 例如,x = 3 + 4;
• 更新后赋值(+=、–=、*=、/=、%=):
variable op= expression; // 例如,x += 3;,它是x = x + 3;的简写
• 自增(++)和自减(– –):
variable++; // 例如,x++;将x赋值为x+1
| 警告 |
前自增与后自增 将运算符++置于变量前或变量后都是合法的,但是结果稍有不同。 • ++x:先自增x的值,再使用。 • x++:先使用x的值,再自增。 在许多情况下,使用哪种形式并不重要,前提是没有使用自增或自减变量的值。例如,下面的两个语句是等效的(尽管第一个语句所示的语法更常用): x++; ++x; 但在有些情况下,上下文会影响结果(当语句中使用自增或自减变量的值时)。例如: x = 6; y = ++x + 2; // y被赋值为9:首先自增x,然后计算x+2 x = 6; y = x++ + 2; // y被赋值为8:首先计算x+2,然后自增x 像前面的例子那样,使用带有自增运算符的算术表达式的代码通常很难阅读,而且很容易出错。因此一般情况下,最好避免编写这样的代码;建议依照想要的运算顺序,分别编写单独的语句。例如,如果想先增加x,再将x+1赋值给y,建议编写两个单独的语句。 不要这样编写: y = ++x + 1; 而要编写为两个单独的语句: x++; y = x + 1; |
C的printf函数将值输出到终端,而scanf函数读取用户输入的值。printf和scanf函数属于C的标准I/O库,需要通过使用#include <stdio.h>将其显式包含在使用这些函数的任何.c文件的顶部。在本节中,我们将介绍在C程序中使用printf和scanf函数的基础知识。2.8节将更详细地讨论C的输入和输出函数。
C的printf函数与Python的格式化输出函数非常相似——由调用者指定要输出的格式化字符串。格式化字符串通常包含格式说明符,例如输出制表符(\t)或换行符(\n)的特定字符,或输出中值的占位符。占位符由%和%之后的类型说明符组成(例如,%d表示整数值的占位符)。对于格式化字符串中的每个占位符,printf函数需要一个附加参数。在这里,你可以看到带有格式化输出的Python和C示例程序。
Python版本:
# Python格式化输出示例
def main():
print("Name: %s, Info:" % "Vijay")
print("\tAge: %d \t Ht: %g" %(20,5.9))
print("\tYear: %d \t Dorm: %s" %(3, "Alice Paul"))
# 调用main函数
main()C版本:
/* C 格式化输出示例 */
#include <stdio.h>
int main() {
printf("Name: %s, Info:\n", "Vijay");
printf("\tAge: %d \t Ht: %g\n",20,5.9);
printf("\tYear: %d \t Dorm: %s\n",3,"Alice Paul");
return 0;
}运行时,该程序的两个版本都会产生相同的输出格式:
Name: Vijay, Info:
Age: 20 Ht: 5.9
Year: 3 Dorm: Alice PaulC的printf函数与Python的print函数的主要区别在于,Python版本会在输出字符串的末尾隐式输出换行符,而C版本不会。因此,此例中的C格式化字符串末尾有换行符(\n),以显式输出换行符。在C的printf函数和Python的print函数中,列出格式化字符串中占位符的参数值的语法也略有不同。
C使用与Python相同的格式占位符来指定不同类型的值。前面的示例演示了以下格式占位符:
%g:float(或double)值的占位符 %d:十进制数值(int、short或char值)的占位符 %s:字符串值的占位符
C还支持使用%c 占位符来输出字符值。当程序员想要输出与特定数值编码相关的ASCII字符时,可以使用此占位符。下面是一个C代码片段,它输出一个字符值(%d)及其字符编码(%c):
// 以十进制形式(%d)输出一个字符值及其字符编码(%c)
char ch;
ch = 'A';
printf("ch value is %d which is the ASCII value of %c\n", ch, ch);
ch = 99;
printf("ch value is %d which is the ASCII value of %c\n", ch, ch);运行程序时,输出如下:
ch value is 65 which is the ASCII value of A ch value is 99 which is the ASCII value of c
C的scanf函数提供了一种读取用户(通过键盘)输入的值,并将其存储在程序变量中的方法。scanf函数对用户输入数据格式的准确性可能有点挑剔,这意味着它难以鲁棒(robust)地处理用户输入的格式错误。在2.8节中,我们将讨论如何能更鲁棒地读取用户输入值。现在,请记住,如果你的程序由于用户输入的格式错误而进入无限循环,你可以随时按Ctrl+C组合键来终止。
在Python和C中,读取输入的处理方式不同:Python使用input函数将值作为字符串读入,然后将字符串值转换为int值,而C使用scanf函数读取int值并将其存储在int型程序变量(例如,&num1)中。以下示例展示了在Python和C中读取用户输入值的程序。
Python版本:
# Python输入示例
def main():
num1 = input("Enter a number:")
num1 = int(num1)
num2 = input("Enter another:")
num2 = int(num2)
print("%d + %d = %d" % (num1, num2, (num1+num2)))
# 调用main函数
main()C版本:
/* C输入示例 */
#include <stdio.h>
int main() {
int num1, num2;
printf("Enter a number: ");
scanf("%d", &num1);
printf("Enter another: ");
scanf("%d", &num2);
printf("%d + %d = %d\n", num1, num2, (num1+num2));
return 0;
}运行程序时,两个程序均读入两个值(示例中为30和67):
Enter a number: 30 Enter another: 67 30 + 67 = 97
与printf函数一样,scanf函数采用格式化字符串指定读入值的数量和类型(例如,"%d"指定一个int值)。scanf函数在读取值时会跳过其前后的空格,因此它的格式化字符串只需要包含一系列格式占位符,通常在它的格式化字符串中的占位符之间没有空格或其他格式化字符。格式化字符串中的占位符实参指定了程序变量输入的位置,读入的值将存储到该位置。使用&运算符作为变量名前缀可以获取变量在程序内存中的位置,也就是变量的内存地址。2.2节将详细讨论&运算符。目前,我们仅在scanf函数中使用它。
下面是另一个scanf函数示例(见配套资源的scanf_ex.c文件),其中格式化字符串有对应两个值的占位符,第一个值是int类型,第二个值是float类型:
int x;
float pi;
// 读入后跟一个浮点数的int值("%d%g")
// 将int值存储在x 的内存位置(&x)
// 将浮点值存储在pi的内存位置(&pi)
scanf("%d%g", &x, &pi);当通过scanf函数向程序输入数据时,单个输入值必须由至少一个空格字符分隔。然而,由于scanf函数跳过了额外的前后空白字符(如空格、制表符和换行符),用户可以在每个输入值之前或之后输入任意数量的空格。例如,如果用户在前面的示例中调用scanf函数时输入以下内容,scanf函数将读取8并将其存储在x变量中,然后读取3.14并将其存储在pi变量中:
8 3.14
以下代码示例表明,C和Python中if-else语句的语法和语义非常相似。主要的语法区别在于Python使用缩进来表示语句的“主体”,而C使用花括号(但仍然应该在C代码中使用良好的缩进)。
Python版本:
# Python版本的if-else示例
def main():
num1 = input("Enter the 1st number:")
num1 = int(num1)
num2 = input("Enter the 2nd number:")
num2 = int(num2)
if num1 > num2:
print("%d is biggest" % num1)
num2 = num1
else:
print("%d is biggest" % num2)
num1 = num2
# 调用main函数
main()C版本:
/* C 版本的if-else示例 */
#include <stdio.h>
int main() {
int num1, num2;
printf("Enter the 1st number: ");
scanf("%d", &num1);
printf("Enter the 2nd number: ");
scanf("%d", &num2);
if (num1 > num2) {
printf("%d is biggest\n", num1);
num2 = num1;
} else {
printf("%d is biggest\n", num2);
num1 = num2;
}
return 0;
}在Python和C中,if-else语句的语法几乎相同,仅有细微差别。在两者中,else部分都是可选的。Python和C还通过连接使用if和else if语句以支持多路分支。以下代码描述了完整的C中的if-else语法:
// 单路分支
if ( <boolean expression> ) {
<true body>
}
// 双路分支
if ( <boolean expression> ) {
<true body>
}
else {
<false body>
}
// 多路分支(连续使用if-else if-...-else)
// (在第一个if之后,有一个或多个'else if')
if ( <boolean expression 1> ) {
<true body>
}
else if ( <boolean expression 2> ) {
// 第一个表达式为假,第二个表达式为真
<true 2 body>
}
else if ( <boolean expression 3> ) {
// 第一和第二个表达式为假,第三个表达式为真
<true 3 body>
}
// ... 更多else if ...
else if ( <boolean expression N> ) {
// 开始的(N-1)个表达式为假,第N个表达式为真
<true N body>
}
else { // 最后一个else部分是可选的
// 如果之前的表达式全部为假
<false body>
}C不提供具有真值或假值的布尔类型。作为替代,C在条件语句中使用整数值表示真或假。在条件表达式中使用时,整数表达式为
• 零(0)的计算结果为假(false);
• 非零值(任何正值或负值)的计算结果为真(true)。
C有一组用于布尔表达式的关系运算符和逻辑运算符。关系运算符采用类型相同的操作数并计算为零(假)或非零值(真)。关系运算符如下:
• 相等(==)和不等(不相等,!=);
• 比较运算符——小于(<)、小于或等于(<=)、大于(>)、大于或等于(>=)。
以下C代码片段显示了关系运算符的一些示例:
// 假设x和y为int型,并且已经在该代码位置之前被赋值
if (y < 0) {
printf("y is negative\n");
} else if (y != 0) {
printf("y is positive\n");
} else {
printf("y is zero\n");
}
// 设置x和y的值为二者中的较大值
if (x >= y) {
y = x;
} else {
x = y;
}C的逻辑运算符(logical operator)使用整数“布尔”操作数,并计算为0(假)或非零值(真)。逻辑运算符如下:
• 逻辑非(!);
• 逻辑与(&&)——在第一个false表达式处停止计算(短路);
• 逻辑或(||)——在第一个true表达式处停止计算(短路)。
一旦知道结果,C的短路(short-circuit)逻辑运算符就停止计算逻辑表达式。例如,如果逻辑与(&&)表达式的第一个操作数的计算结果为假,则&&表达式的结果必然为假,因此不需要也不会计算第二个操作数的值。
以下是C中使用逻辑运算符的条件语句的示例(最好在复杂的布尔表达式周围使用括号,以使其更易于阅读):
if ( (x > 10) && (y >= x) ) {
printf("y and x are both larger than 10\n");
x = 13;
} else if ( ((-x) == 10) || (y > x) ) {
printf("y might be bigger than x\n");
x = y * x;
} else {
printf("I have no idea what the relationship between x and y is\n");
}与Python一样,C也支持for循环和while循环。此外,C还支持do-while循环。
C和Python中的while循环的语法几乎相同,行为也相同。在这里,你可以看到C和Python中带有while循环的示例程序。
Python版本:
# Python的while循环示例
def main():
num = input("Enter a value: ")
num = int(num)
# 确定num不为负
if num < 0:
num = -num
val = 1
while val < num:
print("%d" % (val))
val = val * 2
# 调用main函数
main()C版本:
/* C的while循环示例 */
#include <stdio.h>
int main() {
int num, val;
printf("Enter a value: ");
scanf("%d", &num);
// 确定num不为负
if (num < 0) {
num = -num;
}
val = 1;
while (val < num) {
printf("%d\n", val);
val = val * 2;
}
return 0;
}while循环语法在C中与在Python中非常相似,并且都以相同的方式计算:
while ( <boolean expression> ) {
<true body>
}while循环首先检查布尔表达式,如果为真,则执行函数体。在前面的示例程序中,val变量的值在while循环中重复地被输出,直到它的值大于num变量的值为止。如果用户输入10,C和Python程序都将输出以下内容:
1 2 4 8
C还支持类似while循环的do-while循环,但后者首先执行循环体,然后检查条件,只要条件为真,就重复执行循环体。也就是说,do-while循环始终执行循环体至少一次:
do {
<body>
} while ( <boolean expression> );作为补充的while循环示例,请参见本书配套资源的whileLoop1.c6和whileLoop2.c7文件。
C中的for循环与Python中的for循环不同。在Python中,for循环是对序列的迭代;而在C中,for循环是更通用的循环结构。以下是使用for循环输出0和用户提供的输入值之间所有值的示例程序。
Python版本:
# Python的for循环示例
def main():
num = input("Enter a value: ")
num = int(num)
#确保num不为负
if num < 0:
num = -num
for i in range(num):
print("%d" % i)
# 调用main函数
main()C版本:
/* C的for循环示例 */
#include <stdio.h>
int main() {
int num, i;
printf("Enter a value: ");
scanf("%d", &num);
// 确保 num 不为负
if (num < 0) {
num = -num;
}
for (i = 0; i < num; i++) {
printf("%d\n", i);
}
return 0;
}在此例中,可以看到C的for循环语法与Python的for循环语法有很大不同,计算规则也不同。
C的for循环语法如下。
for ( <initialization>; <boolean expression>; <step> ) {
<body>
}for循环计算规则如下。
(1)在第一次进入for循环时计算一次<initialization>(记作eval init)。
(2)计算<boolean expression>(记作eval bool expr)。如果为0(假),则退出for循环(换句话说,程序终止循环体语句的重复执行)。
(3)计算循环体(loop body)中的语句<body>(记作execute loop body)。
(4)计算<step>表达式(记作eval step)。
(5)重复步骤(2)。
下面是使用for循环输出值0、1和2的简单示例:
int i;
for (i = 0; i < 3; i++){
printf("%d\n", i);
}对上面的循环执行for循环计算规则,将产生以下操作序列:
(1)eval init: i 设为 0 (i=0) (2)eval bool expr: i < 3 为真 (3)execute loop body: 输出 i (0) (4)eval step: i 设为 1 (i++) (2)eval bool expr: i < 3 为真 (3)execute loop body: 输出 i (1) (4)eval step: i 设为 2 (i++) (2)eval bool expr: i < 3 为真 (3)execute loop body: 输出 i (2) (4)eval step: i 设为 3 (i++) (2)eval bool expr: i < 3 为假,退出for循环
以下程序显示了一个更复杂的for循环示例(见配套资源的forLoop2.c文件)。请注意,因为C支持包含<initialization>和<step>多个语句的for循环,这可以使代码更加简洁。这个例子演示了一种更复杂的for循环语法,为了让代码更容易阅读和理解,可以将j+=10步骤语句移到循环体的末尾,并且使其只有一个步骤语句i+=1。
/* 使用多个变量的更复杂的for循环示例。
*(在eval init和eval step部分包含多个语句,
* 这样的for循环并不常见,但C支持它,
* 并且有时很有用……但不要仅仅因为你学会了就疯狂使用)
*/
#include <stdio.h>
int main() {
int i, j;
for (i=0, j=0; i < 10; i+=1, j+=10){
printf("i+j = %d\n", i+j);
}
return 0;
}
// 无论for循环的每一部分多简单或多复杂, for循环的计算规则都是一样的
// (1)在第一次计算for循环时,计算一次初始化语句:i=0和j=0
// (2)计算布尔条件: i < 10
// 如果为假(当i是10时),则跳出循环
// (3)执行循环体内的语句: printf语句
// (4)计算step语句: i+=1, j+=10
// (5)重复,在步骤(2)处开始
在C中,for循环和while循环在功能上是等效的,这意味着任何while循环都可以表示为for循环,反之亦然。在Python中情况并非如此,其中for循环是对一系列值的迭代。因此,其无法像Python中更加通用的while循环一样实现某些循环行为。不确定循环是Python中只能用while循环编写实现的一个例子。
考虑C中的以下while循环:
int guess = 0;
while (guess != num) {
printf("%d is not the right number\n", guess);
printf("Enter another guess: ");
scanf("%d", &guess);
}这个循环可以转换成C中的等效for循环:
int guess;
for (guess = 0; guess != num; ) {
printf("%d is not the right number\n", guess);
printf("Enter another guess: ");
scanf("%d", &guess);
}然而,在Python中,这种类型的循环行为只能通过while循环来实现。
for循环和while循环在C中的表达能力相当。for循环是一种很自然的循环结构,用于确定循环(比如一定范围内值的迭代);而while循环虽然也是一种很自然的循环结构,但用于不确定循环(比如重复直至用户输入偶数)。因此,C为程序员提供了这两种循环。
函数将代码分解为可管理的片段,并减少重复的代码。函数可能将零个或多个参数(parameter)作为输入,并返回特定类型的单个值。函数声明(declaration)或原型(prototype)指定函数的名称、返回类型以及参数列表(所有参数的数量和类型)。函数定义包括调用函数时要执行的代码。C中的所有函数都必须在调用之前声明。这可以通过声明函数原型或在调用函数前完全定义函数来完成:
// 函数定义格式
// ---------------------
<return type> <function name> (<parameter list>)
{
<function body>
}
// 参数列表格式
// ---------------------
<type> <param1 name>, <type> <param2 name>, ..., <type> <last param name>这是一个函数定义的示例。请注意,注释描述了函数的作用、每个参数的详细信息(用途和应该传递的内容),以及函数返回的内容:
/* 该程序计算用户输入的两个值中的较大值 */
#include <stdio.h>
/* max:计算出两个整数值中的较大值
* x:一个整数值
* y:另一个整数值
* return:x和y中的较大值
*/
int max(int x, int y) {
int bigger;
bigger = x;
if (y > x) {
bigger = y;
}
printf(" in max, before return x: %d y: %d\n", x, y);
return bigger;
}不返回值的函数应指定void返回类型。以下是一个void函数的示例:
/* 输出从start到stop的数的平方
* start:范围的起始值
* stop:范围的结束值
*/
void print_table(int start, int stop) {
int i;
for (i = start; i <= stop; i++){
printf("%d\t", i*i);
}
printf("\n");
}与任何支持函数或过程的编程语言一样,函数调用可以激活一个函数,并为特定调用传递特定的参数值。函数通过其名称被调用并传递参数,每个实参对应函数中的一个形参。在C中,调用函数的方法如下所示:
// 函数调用格式 // --------------------- function_name(<argument list>); // 参数列表格式 // --------------------- <argument 1 expression>, <argument 2 expression>, ..., <last argument expression>
C函数的参数按值传递,每个函数形参都分配有调用者在函数调用中传递的相应实参的值。按值传递语义意味着对函数中参数值的任何更改(即在函数中为参数分配新值)对调用者都是不可见的。
以下是一些调用之前提到的max和print_table函数的示例:
int val1, val2, result;
val1 = 6;
val2 = 10;
/* 调用max函数,传递两个int值,因为max函数返回一个int值,所以
* 将这个返回值赋值给一个局部变量(result)
*/
result = max(val1, val2); /* 调用max函数,参数为6和10 */
printf("%d\n", result); /* 输出10 */
result = max(11, 3); /* 调用max函数,参数为11和3 */
printf("%d\n", result); /* 输出11 */
result = max(val1 * 2, val2); /* 调用max函数,参数为12和10 */
printf("%d\n", result); /* 输出12 */
/* print_table函数不返回值,但它需要两个参数 */
print_table(1, 20); /* 输出包含数字1到20的表格 */
print_table(val1, val2); /* 输出包含数字6到10的表格 */以下是另一个完整程序的示例,演示了对max函数的实现的调用,这个实现略有不同,它有一个附加语句用来更改参数的值(x = y):
/* max:计算出两个整数值中的较大值
* x:一个整数值
* y:另一个整数值
* return:x和y中的较大值
*/
int max(int x, int y) {
int bigger;
bigger = x;
if (y > x) {
bigger = y;
// 注意:修改形参x的值不会更改与其对应的实参的值
x = y;
}
printf(" in max, before return x: %d y: %d\n", x, y);
return bigger;
}
/* 主函数:调用max函数 */
int main() {
int a, b, res;
printf("Enter two integer values: ");
scanf("%d%d", &a, &b);
res = max(a, b);
printf("The larger value of %d and %d is %d\n", a, b, res);
return 0;
}以下输出显示了该程序在两次运行中可能出现的情况。注意两次运行中参数x的值(从max函数内部输出)的差异。具体来说,请注意在第二次运行中,更改形参x的值并不会影响在函数调用返回后以实参传入max函数的变量的值:
$ ./a.out Enter two integer values: 11 7 in max, before return x: 11 y: 7 The larger value of 11 and 7 is 11 $ ./a.out Enter two integer values: 13 100 in max, before return x: 100 y: 100 The larger value of 13 and 100 is 100
由于实参按值传递给函数,更改一个形参值的max函数的前一版本的行为,与不更改形参值的max函数的原始版本完全相同。
执行栈(execution stack)记录了程序中激活函数的状态。每个函数调用都会创建一个新的栈帧[stack frame;有时称为激活帧(activation frame)或激活记录(activation record)],其中包含参数和局部变量值。栈顶的帧是激活帧,代表当前正在执行的激活函数,只有它的局部变量和参数在作用域内。当调用一个函数时,为其创建一个新的栈帧(压入栈顶),并在新栈帧中为局部变量和参数分配空间。当一个函数返回时,则将其栈帧从栈中移除(从栈顶弹出),并将调用者的栈帧留在栈顶。
对于前面的示例程序,在max函数执行return语句之前的执行点,执行栈将如图1-3所示。回想一下,通过main函数传递给max函数的参数值是按值传递的,这意味着max函数的形参x和y被赋予相应的实参值,也就是main函数调用的a和b。尽管max函数改变了x的值,但这并不影响main函数中a的值。
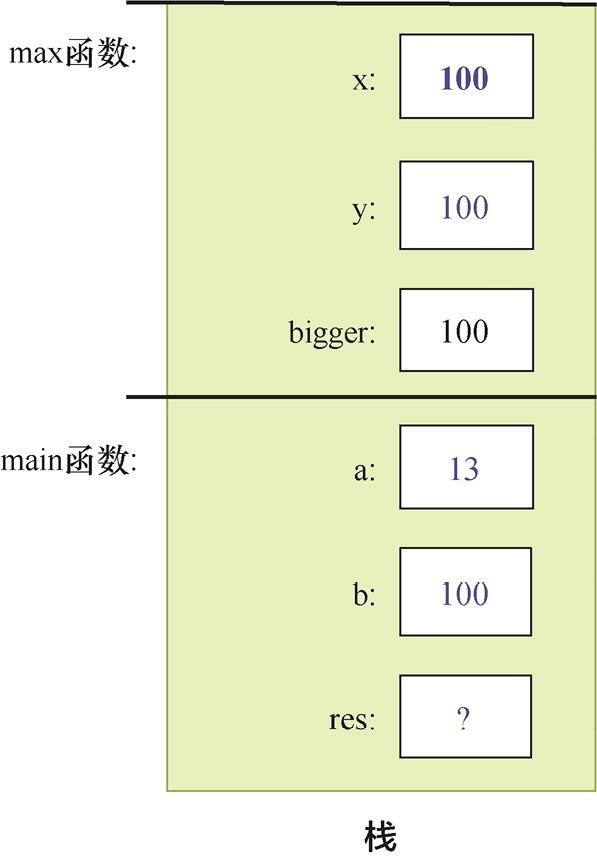
图1-3 从max函数返回之前的执行栈
以下完整程序包括两个函数,并显示了从main函数调用这两个函数的示例。在这个程序中,我们在main函数上方声明了函数max和print_table的原型,这样尽管main函数先被定义,但仍可以访问这两个函数。main函数包含整个程序的高级步骤,首先定义它与程序的自顶向下设计相呼应。这个示例包括一些注释,这些注释描述了程序中对函数和函数调用很重要的部分。你可以下载并运行完整的程序(见配套资源的function.c文件)。
/* 这个文件展示了定义和调用C函数的示例, * 还阐述了如何使用scanf函数 */ #include <stdio.h> /* 这是一个函数原型的示例。函数原型仅定义了函数的类型信息 * (函数的名称、返回类型以及参数列表) * 如果文件中的一个函数未完整定义,那么在main函数中调用该函数时,就要使用函数原型 */ int max(int n1, int n2); /* 另一个函数原型的示例。 void是函数的返回类型,表示不返回值 */ void print_table(int start, int stop); /* 所有C程序都必须包含一个main函数。这个函数定义了程序开始执行时的行为, * 常用于组织程序的全局行为 */ int main() { int x, y, larger; printf("This program will operate over two int values.\n"); printf("Enter the first value: "); scanf("%d", &x); printf("Enter the second value: "); scanf("%d", &y); larger = max(x, y); printf("The larger of %d and %d is %d\n", x, y, larger); print_table(x, larger); return 0; } /* 这是函数定义的示例。它不仅指定函数的名称和返回类型,还定义完整的函数体代码 *(模仿完整的函数注释) */ /* 计算出两个整数值中的较大值 * n1:第一个值 * n2:第二个值 * returns: n1和n2中的较大值 */ int max(int n1, int n2) { int result; result=n1; if (n2 > n1) { result = n2; } return result; } /* 输出从start到stop的数的平方 * start:范围的起始值 * stop:范围的结束值 */ void print_table(int start, int stop) { int i; for (i = start; i <= stop; i++) { printf("%d\t", i*i); } printf("\n"); }
数组(array)是一种C结构,用于创建类型相同的数据元素的有序集合,并将该集合与单个程序变量相关联。有序意味着每个元素在值的集合中有着特定位置(位置0、位置1,以此类推),而不是说这些值必须是排好序的。数组是C语言的主要机制之一,用于对多个数据值进行分组,并通过单个名称进行引用。数组有多种形式,但基本形式是一维数组,用于在C中实现类似列表的数据结构和字符串。
C数组可以存储多个类型相同的数据值。在本章中,我们将讨论静态声明的(statically declared)数组,这意味着数组的总容量(数组中可以存储的元素的最大数量)是固定的,并且在声明数组变量时就已定义。在第2章中,我们将讨论其他类型的数组,如“动态分配的数组”和“二维数组”。
以下代码显示了一个程序的Python版本和C版本,该程序初始化并输出整数值的集合。Python使用内置的列表(list)类型来存储一系列值,而C使用int类型的数组来存储值的集合。
一般来说,Python为程序员提供了一个高级列表接口,其隐藏了许多底层实现细节。而C向程序员展现了一个底层的数组实现,让程序员来实现更高级的功能。换句话说,数组支持底层数据存储,而不具备高级列表功能,如获取长度、添加元素、插入元素等。
Python版本:
# 使用列表的Python程序示例
def main():
# 创建一个空列表
my_lst = []
# 向列表中添加10个整数
for i in range(10):
my_lst.append(i)
# 设置位置3处的值为100
my_lst[3] = 100
# 输出列表元素的数量
print("list %d items:" % len(my_lst))
# 输出列表中的每个元素
for i in range(10):
print("%d" % my_lst[i])
# 调用main函数
main()C版本:
/* 使用数组的C程序示例 */
#include <stdio.h>
int main() {
int i, size = 0;
// 声明包含10个整型元素的数组
int my_arr[10];
// 设置每个数组元素的值
for (i = 0; i < 10; i++) {
my_arr[i] = i;
size++;
}
// 设置位置3处的值为100
my_arr[3] = 100;
// 输出数组元素的数量
printf("array of %d items:\n", size);
// 输出数组中的每个元素
for (i = 0; i < 10; i++) {
printf("%d\n", my_arr[i]);
}
return 0;
}以上程序的C版本和Python版本有一些相似之处,其中最明显的是可以通过索引访问单个元素,索引值从0开始。也就是说,这两种语言都将集合中的第一个元素称作位置为0的元素。
该程序的C版本和Python版本的主要区别在于列表或数组的容量,以及如何确定它们的大小(元素数量)。
对于Python列表:
my_lst[3] = 100 # Python语法,设置位置3处的元素值为100 my_lst[0] = 5 # Python语法,设置第1个元素的值为5
对于C数组:
my_arr[3] = 100; // C语法,设置位置3处的元素值为100 my_arr[0] = 5; // C语法,设置第1个元素的值为5
在Python中,程序员不需要预先指定列表的容量,而是根据程序的需要自动增加列表的容量。例如,Python的append函数会自动增加Python列表的大小,并将传递的值添加到列表的末尾。
相比之下,在C中声明一个数组变量时,程序员必须指定它的类型(存储在数组中的每个值的类型)和总容量(存储位置的最大数量)。例如:
int arr[10]; // 声明包含10个int型元素的数组 char str[20]; // 声明包含20个char型元素的数组
前面的声明先后创建了两个变量,一个名为arr(总容量为10的整型数组),另一个名为str(总容量为20的字符型数组)。
为了计算列表的大小(指列表中值的总数),Python提供了一个len函数,该函数返回传递给它的任何列表的大小。在C中,程序员必须明确地跟踪数组中元素的数量(例如,上面C版本的代码中的size变量)。
对比该程序的Python版本和C版本可以发现另一个不太明显的区别:Python列表和C数组在内存中的存储方式不同。C明确规定了数组在程序内存中的布局方式,而Python对程序员隐藏了列表的实现方式。在C中,单个数组元素分配在程序内存中的连续位置。例如,第3个数组位置在内存中紧挨着第2个数组位置和第4个数组位置(在第2个数组位置之后、第4个数组位置之前)。
Python提供了多种方法来访问列表中的元素。然而,正如之前提到的,C仅支持通过索引访问数组元素。有效索引值的范围是从0到数组的容量减1。以下是一些示例:
int i, num;
int arr[10]; // 声明一个容量为10的整型数组
num = 6; // 追踪数组中使用的元素个数
// 初始化数组arr中的前5个元素(索引为0~4)
for (i=0; i < 5; i++) {
arr[i] = i * 2;
}
arr[5] = 100; // 为索引5处的元素赋值100这个例子声明了一个容量为10的数组(它有10个元素),但我们只使用了其中的前6个元素(当前值的集合大小是6,而不是10)。 使用静态声明的数组时,通常会出现一些数组容量未使用的情况。因此,我们需要用另一个程序变量来跟踪数组的实际大小(元素数量)(本例中为num)。
当程序尝试访问无效索引时,Python和C对错误处理的方法有所不同。如果使用无效的索引值访问列表中的元素(例如,索引超出列表中的元素数量),Python将抛出IndexError异常。而在C中,则需要由程序员来确保代码在索引数组时只使用有效的索引值。因此,对于下面这样的代码,若访问的数组元素超出分配的数组边界,程序的运行时行为将是不明确的:
int array[10]; // 大小为10的数组包含合法索引0~9 array[10] = 100; // 在这个数组中,10是一个非法索引
C编译器不会拒绝编译访问数组边界之外的数组位置的代码,C编译器本身及程序运行时也不会进行边界检查。因此,运行此代码可能会导致意想不到的程序行为(并且每次运行代码时的程序行为可能不同)。这可能导致你的程序崩溃,或者可能改变另一个变量的值,但也可能对你的程序行为没有影响。换句话说,这种情况会导致程序错误,可能会(也可能不会)表现为意外的程序行为。因此,作为C程序员,你要确保在访问数组时引用有效的位置!
在C中将数组传递给函数的语义与在Python中将列表传递给函数的语义类似:函数可以更改传递的数组或列表中的元素。以下是一个示例函数,它采用两个形参——一个int数组形参(arr)和一个int形参(size):
void print_array(int arr[], int size) {
int i;
for (i = 0; i < size; i++) {
printf("%d\n", arr[i]);
}
}参数名称后面的[ ]告诉编译器,参数arr的类型是整型数组,而不是如形参size那样的int类型。在第2章中,我们将展示指定数组形参的另一种语法。数组形参arr的容量并未指定:arr[]表示可以使用任意容量的数组实参调用此函数。因为无法仅从数组变量中获取数组的大小或容量,所以传递数组的函数会用第二个参数来指定数组的大小(如之前示例中的size形参)。
要调用具有数组形参的函数,可将数组名作为实参传递。以下是一个C代码片段,其中包含调用print_array函数的示例:
int some[5], more[10], i;
for (i = 0; i < 5; i++) { // 初始化每个数组的前5个元素
some[i] = i * i;
more[i] = some[i];
}
for (i = 5; i < 10; i++) { // 初始化more数组的后5个元素
more[i]=more[i-1]+more[i-2];
}
print_array(some, 5); // 输出some数组的所有5个元素
print_array(more, 10); // 输出more数组的所有10个元素
print_array(more, 8); // 仅输出more数组的前8个元素在C中,数组变量的名称等同于数组的基址(base address,即数组中第0个元素的内存位置)。 由于C按值传递函数调用语义,当将数组传递给函数时,数组的每个元素都不是单独传递给函数的。换句话说,函数没有接收到每个数组元素的副本。相反,数组形参得到的是数组基址的值。这种行为意味着当函数修改作为形参传递的数组元素时,这些更改将在函数返回时持续存在。例如以下C程序片段:
void test(int a[], int size) {
if (size > 3) {
a[3] = 8;
}
size = 2; // 修改形参不会改变实参
}
int main() {
int arr[5], n = 5, i;
for (i = 0; i < n; i++) {
arr[i] = i;
}
printf("%d %d", arr[3], n); // 输出:3 5
test(arr, n);
printf("%d %d", arr[3], n); // 输出:8 5
return 0;
}main函数中对test函数的调用被传递给了实参arr,其值是arr数组在内存中的基址。test函数中的形参a获取此基址值的副本。换句话说,形参a指向的数组存储位置与实参arr相同。因此,当test函数更改存储在a数组中的值时(a[3] = 8),就会影响到实参数组中的相应位置(arr[3]现在是8)。原因在于,a的值是arr的基址,而arr的值是arr的基址,所以a和arr指的是同一个数组(内存中相同的存储位置)!图1-4展示了test函数返回前的执行栈中的内容。
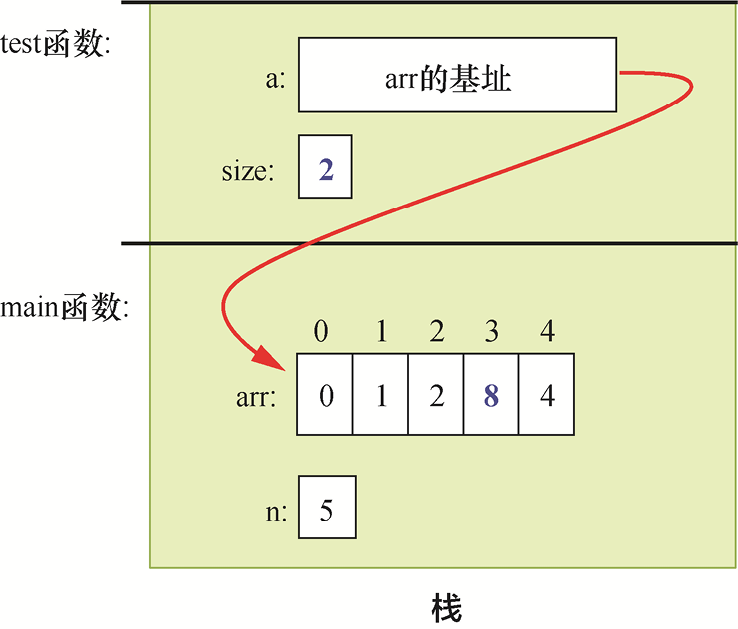
图1-4 带有数组形参的函数的执行栈
形参a传递数组实参arr的基址值,这意味着它们都引用内存中的同一组数组存储位置。我们用从a到arr的箭头来表示这一点,并加粗显示被test函数修改的值。改变形参size的值不会改变与其对应的实参n的值,但是改变a所指的其中一个元素的值(例如,a[3] = 8)却会影响arr数组中相应位置的值。
Python实现了字符串类型,并提供使用字符串的丰富接口,但C中没有相应的字符串类型,而是将字符串实现为字符数组。并非每个字符数组都被用作C字符串,但每个C字符串都是字符数组。
回想一下,C中的数组可能会被定义得比程序最终使用的大。例如,我们在1.5.2节中看到,可以声明一个大小为10的数组,但只使用前6个位置。这种行为对字符串有重大影响:我们不能假设字符串的长度等于存储它的数组的长度。因此,C中的字符串必须以特殊字符结尾,即以空字符('\0')结尾。
以空字符结尾的字符串称为空终止字符串。尽管C中的所有字符串都应该以空字符结尾,但对于新手C程序员来说,未能正确考虑空字符是常犯的错误之一。在使用字符串时,重要的是要记住,字符数组在声明时,必须具有足够的容量来存储字符串中的每个字符和空字符('\0')。例如,要存储字符串"hi",你需要一个至少包含3个字符的数组(一个用于存储'h',另一个用于存储'i',还有一个用于存储'\0')。
因为经常使用字符串,所以C提供了一个字符串库,其中包含用于操作字符串的函数。使用这些字符串操作函数的程序需要包含string.h头文件。
使用printf函数输出字符串的值时,请在格式化字符串中使用%s占位符。printf函数将输出数组实参中的所有字符,直至遇到'\0'字符。同样,字符串操作函数通常通过搜索'\0'字符来定位字符串的结束位置,或者在其修改的任何字符串的末尾添加一个'\0'字符。
以下是一个使用字符串和字符串操作函数的示例:
#include <stdio.h>
#include <string.h> // 包含C字符串库
int main() {
char str1[10];
char str2[10];
int len;
str1[0] = 'h';
str1[1] = 'i';
str1[2] = '\0';
len = strlen(str1);
printf("%s %d\n", str1, len); // 输出: hi 2
strcpy(str2, str1); // 复制字符串str1的内容到字符串str2中
printf("%s\n", str2); // 输出:hi
strcpy(str2, "hello"); // 复制字符串"hello"到字符串str2中
len = strlen(str2);
printf("%s has %d chars\n", str2, len); // 输出:hello has 5 chars
}C字符串库中的strlen函数返回其字符串实参中的字符数。字符串的终止字符不计入字符串长度,因此对strlen(str1)的调用返回2(字符串"hi"的长度)。strcpy函数每次将一个字符从源字符串(第二个形参)复制到目标字符串(第一个形参),直至遇到源字符串中的空字符。
请注意,大多数C字符串操作函数要求在被调用时传入一个字符数组,该字符数组有足够的容量让函数完成其工作。例如,我们不希望在调用strcpy函数时,目标字符串没有足够的空间来包含源字符串,因为这会导致程序中出现未定义的行为!
C字符串操作函数还要求传递字符串的格式正确,并带有终止字符'\0'。作为C程序员,你需要确保传递有效的字符串给字符串操作函数。因此,在前面调用strcpy函数的示例中,如果源字符串(str1)未初始化为具有终止字符'\0'的字符串,strcpy函数就会超出str1字符串的末尾复制字符,从而导致未定义的行为,这可能导致程序崩溃。
| 警告 |
strcpy可能是不安全的函数 前面的示例安全地使用了strcpy函数。但是,一般来说,strcpy函数会带来安全风险,因为其假定目标字符串足够大,可以存储整个源字符串,但情况可能并非总是如此(例如,当源字符串来自用户输入时)。 之所以现在介绍strcpy函数,是因为这样可以简化对字符串的介绍,2.6节将介绍更安全的替代方案。 |
在第2章中,我们将更详细地讨论C字符串和字符串库。
数组和结构体是C所支持的创建数据元素集合的两种方式。数组用于创建类型相同的数据元素的有序集合,而结构体(struct)用于创建类型不同的数据元素的集合。C程序员可以用许多不同的方式组合数组和结构体的构建块,以创建更复杂的数据类型和数据结构。本节介绍结构体,在第2章中,我们将更详细地描述结构体的特征(见2.7节),并展示如何将结构体与数组组合起来(见2.7.4节)。
C不是面向对象编程语言,因此不支持类。但是,与类的数据部分类似,C支持定义结构化类型。结构体是一种用于表示异构数据集合的类型,它是一种机制,可以将一组不同的类型视为一个单一且连贯的单元。C结构体在单个数据值的基础上提供一个抽象级别,将异构数据视为单一类型。例如,学生有姓名、年龄、平均绩点(Grade Point Average,GPA)和毕业年份。程序员可以定义一种新的struct类型,将这4个数据元素组合成一个struct student变量,该变量包含姓名(char[]类型,用于保存字符串)、年龄(int类型)、GPA(float类型)和毕业年份(int类型)。这种结构体类型的单个变量可以存储某个学生的全部4项数据,例如("Freya",19,3.7,2021)。
在C程序中定义和使用结构体类型分为3个步骤。
(1)对定义了字段值及其类型的结构体进行定义。
(2)声明一个结构体类型的变量。
(3)使用点(.)表示法访问这个变量中各个字段的值。
结构体类型的定义应该出现在任何函数之外,通常靠近程序的.c文件的顶部。定义结构体类型的语法如下(struct是一个保留关键字):
struct <struct_name> {
<field 1 type> <field 1 name>;
<field 2 type> <field 2 name>;
<field 3 type> <field 3 name>;
...
};以下是一个定义新类型struct studentT的例子,用于存储学生数据:
struct studentT {
char name[64];
int age;
float gpa;
int grad_yr;
};这个结构体定义为C的类型系统添加了一个新类型,该类型的名称是struct studentT。这个结构体定义了4个字段,每个字段定义都包括字段的类型和名称。请注意,在此例中,name字段的类型是字符数组,用作字符串(见1.5.4节)。
一旦定义了新类型,就可以声明新类型的变量。请注意,与迄今为止我们遇到的仅包含一个单词的其他类型(如int、char和float)不同,我们的新结构体类型名称包含两个单词,也就是struct studentT。
struct studentT student1, student2; // student1和student2的类型是struct studentT
要访问结构体变量中的字段值,请使用点表示法:
<variable name>.<field name>
访问结构体及其字段时,请仔细考虑正在使用的变量的类型。新入门的C程序员经常会因为没有考虑结构体字段的类型而在程序中引入错误。表1-2显示了与各种struct studentT表达式相关的C类型。
表1-2 与各种struct studentT表达式相关的C类型
| struct studentT表达式 |
C类型 |
|---|---|
| student1 |
struct studentT |
| student1.age |
整型(int) |
| student1.name |
字符数组(char[]) |
| student1.name[3] |
字符(char),存储在name数组中的每个位置 |
以下是一些为struct studentT变量字段赋值的例子:
// name字段是字符数组 strcpy(student1.name, "Kwame Salter"); // age字段是整数值 student1.age = 18 + 2; // gpa字段是浮点值 student1.gpa = 3.5; // grad_yr字段是整数值 student1.grad_yr = 2020; student2.grad_yr = student1.grad_yr;
图1-5显示了在前面的例子中进行字段赋值后,student1变量在内存中的布局。只有结构体变量的字段(方框中的区域)存储在内存中。为清晰起见,我们在图1-5中标注了字段名称,但是对于C编译器来说,字段存储的只不过是位置或从结构体变量的内存位置开始的偏移量。例如,根据struct studentT类型的定义,编译器知道要访问名为gpa的字段,就必须跳过一个包含64个字符(name)和一个整数(age)的数组。请注意,在图1-5中,name字段只描述了64字符数组中的前6个字符。
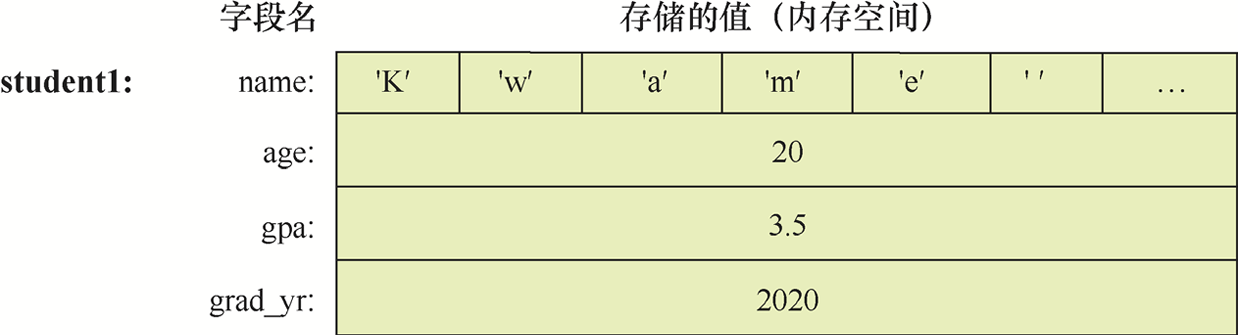
图1-5 student1变量为每个字段赋值后的内存
C结构体类型的变量为左值,这意味着它们可以出现在赋值语句的左侧。因此,可以通过一个简单的赋值语句,将一个结构体变量的值赋给另一个结构体变量。赋值语句右侧结构体的字段值被复制到赋值语句左侧结构体的字段中。换句话说,一个结构体的内容被复制到另一个结构体中。以下是一个以这种方式分配结构体字段值的例子。
student2 = student1; // student2获取student1的值
//(student1的字段值被复制到student2的对应字段中)
strcpy(student2.name, "Frances Allen"); // 修改一个字段值图1-6显示了两个学生变量在执行赋值语句和strcpy函数调用后的值。请注意,这里将name字段描述为它们所包含的字符串值,而不是64个字符的完整数组。

图1-6 执行结构体赋值和strcpy函数调用后,student1和student2结构体的布局
C提供了一个sizeof运算符,该运算符接收一个类型并返回该类型所使用的字节数。sizeof运算符可用于包括结构体类型在内的任何C类型,以查看该类型的变量需要占用多少内存空间。例如,我们可以输出struct studentT类型的大小:
// 注意: '%lu'格式占位符表示unsigned long值
printf("number of bytes in student struct: %lu\n", sizeof(struct studentT));运行时,这一行应该输出至少76字节的值,因为name数组中有64个字符(每个字符占用1字节),4字节用于int age字段,4字节用于float gpa字段,4字节用于int grad_yr字段。在某些机器上,确切输出的字节数可能大于76。
以下是一个完整的示例程序(见配套资源的studentTstruct.c文件),它定义并演示了如何使用struct studentT类型:
#include <stdio.h>
#include <string.h>
// 定义新类型: struct studentT
// 注意结构体需要定义在函数体之外
struct studentT {
char name[64];
int age;
float gpa;
int grad_yr;
};
int main() {
struct studentT student1, student2;
strcpy(student1.name, "Kwame Salter");// name字段的类型为字符数组
student1.age = 18 + 2; // age字段的类型为int
student1.gpa = 3.5; // gpa字段的类型为float
student1.grad_yr = 2020; // grad_yr字段的类型为int
/* 注意: printf函数没有输出struct studentT(我们定义的类型)的格式占位符。
* 相反,我们需要单独将每个字段传递给printf函数。
*/
printf("name: %s age: %d gpa: %g, year: %d\n",
student1.name, student1.age, student1.gpa, student1.grad_yr);
/* 将student1所有字段的值复制到student2 */
student2 = student1;
/* 对student2做一些修改 */
strcpy(student2.name, "Frances Allen");
student2.grad_yr = student1.grad_yr + 1;
/* 输出student2的字段 */
printf("name: %s age: %d gpa: %g, year: %d\n",
student2.name, student2.age, student2.gpa, student2.grad_yr);
/* 输出struct studentT类型的大小 */
printf("number of bytes in student struct: %lu\n", sizeof(struct studentT));
return 0;
}运行时,程序输出如下:
name: Kwame Salter age: 20 gpa: 3.5, year: 2020 name: Frances Allen age: 20 gpa: 3.5, year: 2021 number of bytes in student struct: 76
| 左值 |
| 左值是一个表示内存存储位置的表达式,可以出现在赋值语句的左侧。在介绍C指针类型以及如何创建更加复杂的结构时(比如将C数组、结构体和指针相结合),重要的是仔细考虑类型,并记住哪些C语言表达式是有效的左值(可以在赋值语句的左侧使用)。 根据我们目前对C语言的了解,基本类型的单个变量、数组元素和结构体变量都是左值。静态声明的数组的名称不是左值(无法改变内存中静态声明的数组的基地址)。以下示例代码片段根据不同类型的左值状态,说明了有效和无效的C赋值语句。 struct studentT {
char name[32];
int age;
float gpa;
int grad_yr;
};
int main() {
struct studentT student1, student2;
int x;
char arr[10], ch;
x = 10; // 有效: x 是左值
ch = 'm'; // 有效: ch是左值
student1.age = 18; // 有效: age字段是左值
student2 = student1; // 有效: student2是左值
arr[3] = ch; // 有效: arr[3]是左值
x + 1 = 8; // 无效: x+1不是左值
arr = "hello"; // 无效: arr不是左值
// 不可以改变静态声明的数组的基地址
// (使用strcpy函数复制字符串"hello"至数组arr)
student1.name = student2.name; // 无效: name字段不是左值
// (静态声明的数组的基地址不可以修改) |
在C中,所有类型的实参都是按值传递给函数的。因此,如果一个函数含有一个结构体类型的形参,那么当使用结构体实参调用这个函数时,实参的值会被传递给形参,也就是说,形参会得到相应实参值的副本。结构体变量的值就是对应内存中的内容,这就是为什么我们可以在这样一条赋值语句中,给一个结构体的字段和另一个结构体的字段赋相同的值。
student2 = student1;
因为结构体变量的值代表对应内存中的全部内容,所以在将结构体作为实参传递给函数时,会给形参提供所有实参结构体中字段值的副本。如果函数改变了结构体形参的字段值,这种改变对实参结构体的相应字段值没有影响。也就是说,对形参字段的改变只修改形参的内存位置的字段值,而不影响实参的内存位置的字段值。
以下是一个完整的示例程序(见配套资源的structfunc.c文件),演示了如何使用带有结构体形参的checkID函数:
#include <stdio.h>
#include <string.h>
/* 结构体类型定义: */
struct studentT {
char name[64];
int age;
float gpa;
int grad_yr;
};
/* 函数原型(声明checkID函数的原型,以便main函数调用它,
* 其完整定义列在structfunc.c文件中的main函数之后)
*/
int checkID(struct studentT s1, int min_age);
int main() {
int can_vote;
struct studentT student;
strcpy(student.name, "Ruth");
student.age = 17;
student.gpa = 3.5;
student.grad_yr = 2021;
can_vote = checkID(student, 18);
if (can_vote) {
printf("%s is %d years old and can vote.\n",
student.name, student.age);
} else {
printf("%s is only %d years old and cannot vote.\n", student.name, student.age);
}
return 0;
}
/* 检查学生是否达到最小年龄
* s:学生
* min_age:最小年龄
* returns:如果学生达到最小年龄,则返回1,否则返回0
*/
int checkID(struct studentT s, int min_age) {
int ret = 1; // 初始化返回值为1 (true)
if (s.age < min_age) {
ret = 0; // 更新返回值为0 (false)
// 尝试修改学生的年龄
s.age = min_age + 1;
}
printf("%s is %d years old\n", s.name, s.age);
return ret;
}当main函数调用checkID函数时,student结构体的值(所有字段的内存内容的副本)被传递给形参s。当checkID函数改变其形参的age字段的值时,这一操作并不影响其实参的age字段。通过运行程序可以看到这种行为,输出结果如下:
Ruth is 19 years old Ruth is only 17 years old and cannot vote.
以上输出显示checkID函数通过输出age字段的状态,反映了该函数修改了其形参的age字段。但是,在函数调用返回后,main函数会输出student结构体的age字段,其值与调用checkID函数之前的值相同。图1-7显示了checkID函数返回之前调用栈的内容。
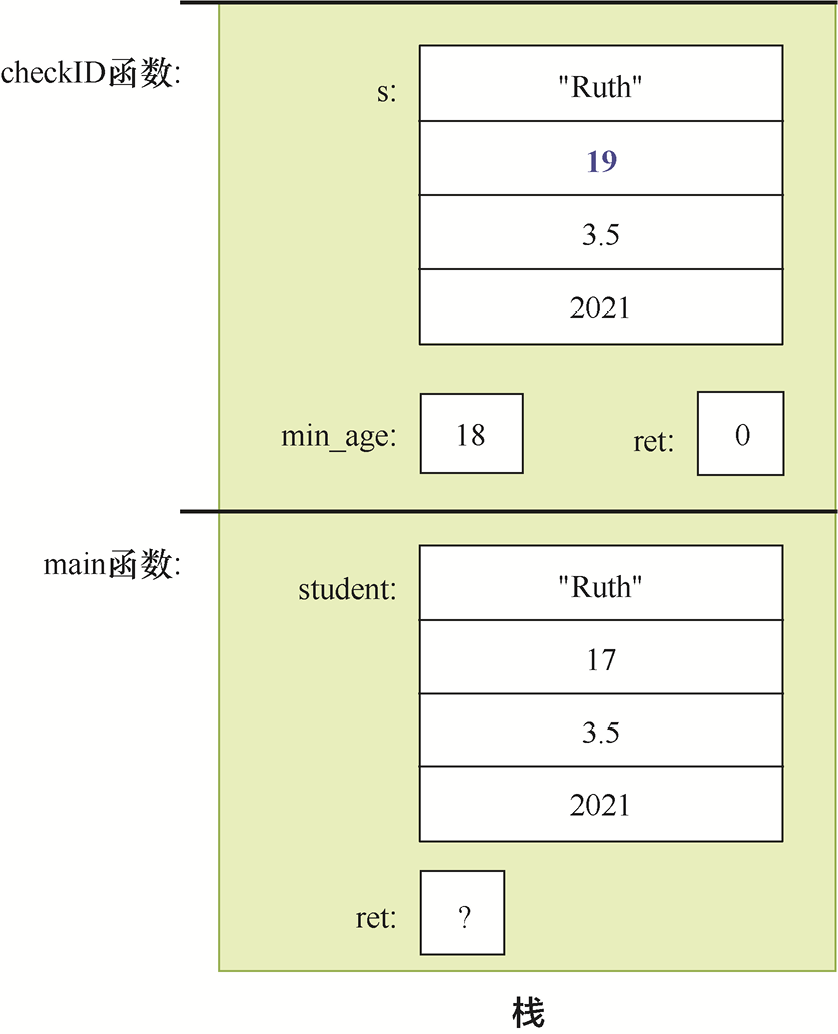
图1-7 checkID函数返回之前调用栈的内容
当一个结构体包含静态声明的数组字段(如struct studentT中的name字段)时,理解结构体形参的按值传递语义尤为重要。当把这样的结构体传递给函数时,结构体实参的全部内存内容,包括数组字段中的每个数组元素,都会被复制到其形参结构体中。如果函数更改了形参结构体的数组内容,那么这些更改在函数返回后将不再存在。鉴于我们对数组传递给函数的方式(见1.5.3节)有了一定的了解,这种行为可能看起来很奇怪,但它与前面描述的结构体复制行为是一致的。
Python是一种广为人知的编程语言,在本章中,我们通过对C与Python中的相似语言结构进行比较,来介绍C语言的许多特性。C与许多其他高级命令式语言和面向对象编程语言有着类似的语言特性,包括变量、循环、条件表达式、函数和I/O。我们讨论了C和Python之间的一些关键差异,包括C要求所有变量在使用之前都声明为特定类型,并且C数组和字符串是比Python列表和字符串更低级的抽象。较低级的抽象允许C程序员更好地控制程序访问内存的方式,从而更好地控制程序的效率。
在第2章中,我们将详细介绍C语言,并更深入地回顾本章介绍的C语言特性,我们还将介绍一些新的C语言特性,其中最值得注意的是C指针变量和对动态内存分配的支持。





