版权信息 书名:MindSpore高阶技术及应用实践
ISBN:978-7-115-65407-6
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 陈 雷
责任编辑 邓昱洲
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
内容提要 本书系统介绍了深度学习的高阶技术,并基于MindSpore进行实践。本书共9章,涵盖数据处理、网络构建、分布式并行、性能及算法优化、模型部署、模型安全与隐私、模型可靠性、AI求解科学计算方程、AI加速科学方法。为便于读者学习,本书还给出了基于MindSpore实现的深度学习高阶技术的示例代码。
本书在深度学习理论的基础上,结合MindSpore的开源技术,拓展了MindSpore的使用范围,可以作为人工智能、智能科学与技术、计算机科学与技术、电子信息工程、自动化等专业的本科生及研究生的教材,也可以作为从事深度学习相关工作的软件开发工程师与科研人员的参考用书。
丛书序 在当今信息时代,深度学习和大语言模型等人工智能技术正在对整个社会产生深远的影响,经济、科技到生活的方方面面都得以革新和提升。这种革新不仅是技术上的进步,更是对人类社会发展的重大推动。
其中,深度学习和大语言模型的兴起为社会带来了前所未有的智能化革命。
通过深度学习技术,计算机能够模仿人类的认知过程,从而完成图像识别、语音识别、自然语言处理等复杂任务。这使得各行各业都能够利用人工智能技术实现效率提升和创新突破。人工智能技术为社会的可持续发展提供了巨大的助力。
大语言模型的兴起正在改变人工智能领域的面貌和应用场景。随着大语言模型的不断成熟和发展,人工智能系统的处理能力和智能水平显著提升。这为自然语言处理、推荐系统、医疗健康等领域的应用带来了更广阔的前景和更深层次的变革,推动了人工智能技术的深度融合和广泛应用。
在经济领域,深度学习和大语言模型将推动产业结构优化和经济增长模式的转变,通过智能化的生产、管理和服务,提高资源利用效率和经济效益,助力经济发展进入新的增长阶段。在科技领域,深度学习和大语言模型将推动科学研究和技术创新的突破,通过挖掘大数据的潜力、提高智能算法的能力,推动科技领域的前沿研究和应用创新,为人类社会带来更多的科技成果和福祉。
正是在这样的背景下,“MindSpore计算与应用丛书”深入探讨了MindSpore在深度学习、大语言模型和科学计算领域的原理、方法及应用,为读者提供更加系统、全面的学习和实践指导,通过对数据处理、网络构建、分布式并行、性能优化等关键技术的详细介绍,帮助读者深入理解深度学习和大语言模型的核心思想和实现方法,从而将其更好地应用于实际项目和科学研究中。本丛书还整理了丰富的实例代码和案例分析,为读者提供丰富的实践经验和应用指导,帮助读者在人工智能领域取得更大的成就和发展。“MindSpore计算与应用丛书”的出版旨在推动人工智能技术在各个领域的创新和应用,促进社会的智能化进程和科技发展,为构建智慧社会做出更大的贡献。
陈雷
2024年9月
前 言 近年来,人工智能(Artificial Intelligence,AI)在各个领域都取得了辉煌的成就,不管是在人们的日常生活,如购物、规划旅程、搭配饮食和理财,还是在生物学、医学、物理、化学等科学领域,AI都起到了巨大的作用。人们不禁好奇,这背后到底是什么样的技术,让AI如此成功。
这正是本书试图解答的问题。
本书系统介绍深度学习的理论,同时深入详述MindSpore的高阶技术,拓展MindSpore的领域应用。本书结合原理讲解和实践案例,帮助读者在掌握深层理论的基础上,学会如何高效便捷地使用MindSpore进行开发。本书内容涵盖数据处理、网络构建、分布式并行、性能及算法优化、模型部署、模型安全与隐私、模型可靠性、AI求解科学计算方程、AI加速科学方法。
希望读者通过阅读本书,全面掌握MindSpore高阶技术,能够运用AI深度学习框架开发高效、稳定、可信的应用,为国产AI生态的蓬勃发展贡献力量。
第1章 数据处理 深度学习离不开大数据的支持,网络模型的训练效果会受数据的影响。数据的优劣决定了模型推理精度的上限,训练模型只能帮助模型无限逼近这个上限。“问渠那得清如许?为有源头活水来。”高质量的数据输入,有利于深度神经网络的构建。所以,数据处理是深度神经网络模型训练中极为关键的一步。
数据处理面临诸多难点与挑战,体现在要满足数据处理的灵活性、端云侧的统一性和数据处理的高效性等方面。在数据处理的灵活性方面,深度学习任务种类繁多,涉及的数据类型各异,即使同为图像数据集,MNIST数据集的组织方式也与CIFAR-10数据集不同。如何使用统一的方式加载不同的数据,存在很大困难。此外,为了实现更好的网络模型训练效果,使用的数据增强方法越来越多,例如采用不同的数据增强逻辑,会使模型精度产生明显的差异,因此需要合理地安排模型的执行逻辑。在端云侧的统一性方面,端侧场景受中央处理器(Central Processing Unit,CPU)性能和内存资源限制,不再适用部分资源消耗大的数据处理操作,如何在不同的场景下提供一致的数据处理结果成为挑战。在数据处理的高效性方面,当前数据处理主要使用CPU,而网络模型训练则使用图形处理单元(Graphics Processing Unit,GPU)或AI芯片进行运算。随着GPU和AI芯片算力的不断提高,可能出现数据处理速度跟不上计算速度的情况,导致GPU和AI芯片因等待数据而空闲,造成资源浪费。针对数据处理的难点与挑战,本章将介绍不同的数据处理方法。
本节介绍一种将数据集(Dataset)归一化存储为MindRecord的方法。数据加载是数据处理的第一步,需要将磁盘中的数据映射到内存中进行后续处理。不同的深度学习任务所需的数据类型不同,如计算机视觉(Computer Vision,CV)任务所需的数据多为图像,自然语言处理(Natural Language Processing,NLP)任务所需的数据多为文本,而语音识别任务所需的数据多为音频。对于图像类数据来说,存在JPEG、PNG和BMP等不同的数据格式。此外,用于辅助训练的标注信息也是多种多样的。如何在数据加载时屏蔽不同类型数据的读写差异,是需要重点解决的问题。可使用一种统一的形式将磁盘中的数据转换为AI框架能够识别的数据。
业界提出了一些数据格式。例如TensorFlow提出了TFRecord数据格式,它基于Protocol Buffers协议将数据存储为二进制文件,提高了数据加载的效率;MXNet提出了RecordIO数据格式,它将数据划分为多个独立的二进制块,实现了加速数据加载的效果。但TFRecord和RecordIO文件中都缺少数据的解释信息,不方便进行数据统计,并且数据不具备索引,无法提供检索功能。
MindRecord是MindSpore提出的一种数据格式。它提供了数据自画像与检索能力,该数据格式文件包含数据的统计信息和索引,实现了数据调优信息的可视化,能够对标注信息进行快速检索和分析; 提高了数据加载性能,通过数据聚合实现了流式读取,通过数据压缩减少了数据存储空间,实现了性能提升;支持全场景部署,可以通过统一的MindDataset接口加载存储的数据格式文件以用于后续训练;支持在本地、云等不同场景中部署。数据的转换与读取流程如图1.1所示。
图1.1 数据的转换与读取流程
MindRecord数据格式的特征如下:不同类型的数据统一存储与访问,编解码更加高效,数据加载性能高;数据聚合存储,可节省空间,方便移动与管理;可以灵活控制分片文件大小,实现分布式训练;提供常用数据集转换脚本,方便将数据集中的数据一键转换为MindRecord数据格式。
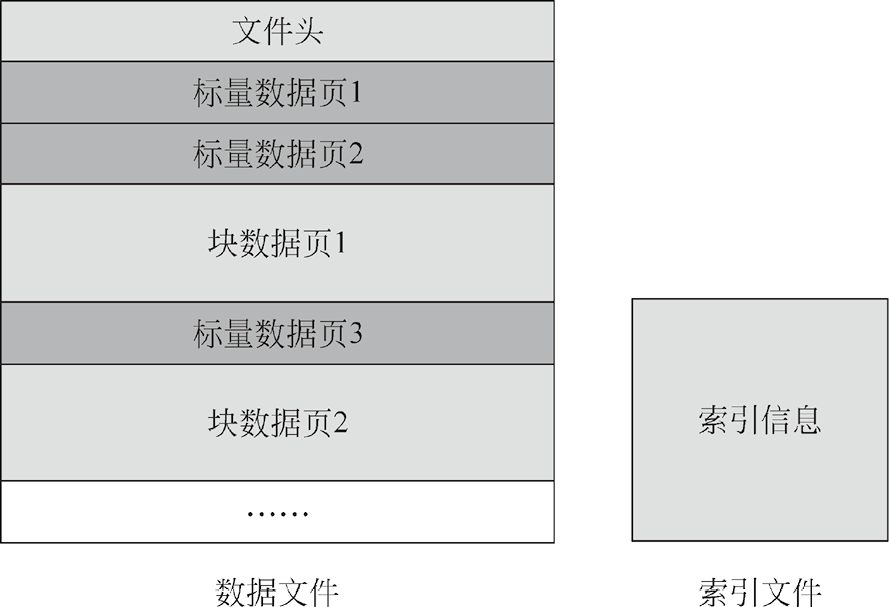
1.1.1 MindRecord原理 MindRecord数据格式文件由数据文件和索引文件构成,如图1.2所示。
图1.2 MindRecord数据格式文件结构
数据文件用于存储用户归一化后的数据信息,包含文件头、标量数据页和块数据页等部分。用户可以根据需要将大数据集分片存储为多个MindRecord数据格式文件,建议单个文件的大小不超过20GB。其中,文件头存储了文件头大小、标量数据页大小、块数据页大小、schema数据结构信息、索引字段、统计信息、文件分区信息、标量数据与块数据对应关系等内容,是MindRecord数据格式文件的元信息; 标量数据页主要用于存储标量数据,包含整型、浮点型和字符串型等类型的数据,如图像标签、文件名等;块数据页主要用于存储数据,可以是二进制流、NumPy数组等,如图像原始文件信息、文本转换成的字典等。
索引文件存储了基于标量数据生成的索引信息,用于检索和统计数据信息。
用户可以通过schema定义MindRecord中的数据结构信息。schema支持的基本数据类型包含int32、int64、float32、float64、string、bytes这6种。schema为包含字段名、字段数据类型和字段维度的Python字典。代码1.1定义了file_name、label和data字段,其中file_name字段的数据类型为string,label字段的数据类型为int32,data字段的数据类型为bytes。
代码1.1 通过schema定义数据结构信息
schema = {"file_name": {"type": "string"},"label": {"type": "int32"},"data": {"type":
"bytes"}} 实际写入的数据被定义成一个Python列表,列表中的元素为Python字典,一个元素对应一条样本数据,元素的字段名与schema的相同,而元素对应的值为需要存储的数据本身,如代码1.2所示。整型与浮点型数据支持使用NumPy的ndarray表示方式,用于存储向量化数据,向量维度信息通过schema中的字段维度值定义,如{"type": "int32","shape": [-1]}用于表示一个数据类型为int32的一维变长向量;而{"type": "float64","shape": [32, 16]}用于表示一个数据类型为float64的二维向量,维度为[32, 16]。
代码1.2 定义的数据
data = [{"file_name": "0.jpg","label": 0,"data": img_0.tobytes()},
{"file_name": "1.jpg","label": 3,"data": img_1.tobytes()},
...] 各种基本数据类型及其参考用途如下。
int32/int64:用于定义整型数据,如图像的标签序号、长、宽、高等。
float32/float64:用于定义浮点型数据,如图像的遮挡率、识别的难易程度值等。
string:用于定义字符串型数据,如样本的文件名、文件路径、样本描述、文本数据等。
bytes:用于定义二进制类型数据,如图像、音频、视频的二进制原始信息等。
整型、浮点型和字符串型数据为标量数据,存储于MindRecord的标量数据页;而向量化数据和二进制类型数据为块数据,存储于MindRecord的块数据页。
定义好schema和数据之后,就可调用MindSpore提供的文件读写接口,用户可按照指定的格式将数据归一化为MindRecord数据格式文件进行存储,以便后续使用。
1.1.2 MindRecord使用示例 对于常用的数据集,如CIFAR-10、CIFAR-100、MNIST、ImageNet等,以及常用的数据格式,如CSV、TFRecord等,MindSpore提供了相应的Python接口,可以将它们转换为MindRecord数据格式,详情可参见MindSpore官网的应用程序接口(Application Program Interface,API)文档。下面主要介绍如何自定义转换CV类和NLP类的数据集。
1. 转换CV类数据集 本示例主要介绍如何将CV类数据集自定义转换为MindRecord数据格式文件。
首先导入代码所需的相关模块,如代码1.3所示。
代码1.3 导入相关模块
import os
from io import BytesIO
from PIL import Image
from mindspore.mindrecord import FileWriter 然后定义MindRecord数据格式文件名,删除工作路径中的重名文件,并创建文件写入句柄,如代码1.4所示,其中shard_num为MindRecord数据格式文件分片数量。
代码1.4 创建文件写入句柄
mindrecord_file_name = "test.mindrecord"
if os.path.exists(mindrecord_file_name):
os.remove(mindrecord_file_name)
os.remove(mindrecord_file_name + ".db")
writer = FileWriter(file_name=mindrecord_file_name,shard_num=1) 接着定义schema数据结构信息,包含file_name、label和data这3个字段,数据类型分别为string、int32和bytes,定义索引字段为file_name和label,如代码1.5所示。
代码1.5 定义schema数据结构信息和索引字段
cv_schema = {"file_name": {"type": "string"},"label": {"type": "int32"},"data":
{"type": "bytes"}}
writer.add_schema(cv_schema,"it is a cv dataset")
writer.add_index(["file_name","label"]) 为了便于演示,此处使用Image.new方法生成100张图像并写入MindRecord数据格式文件,如代码1.6所示,实际使用中,用户可自行将上述图像替换为需要存储的数据。
代码1.6 生成100张图像并写入MindRecord数据格式文件
data = []
for i in range(100):
img_io = BytesIO()
Image.new("RGB",(i * 10 + 1,i * 10 + 1),(255,255,255)).save(img_io,"JPEG")
sample = {}
sample["file_name"] = str(i) + ".jpg"
sample["label"] = i % 10
sample["data"] = img_io.getvalue()
data.append(sample)
if i % 10 == 0:
writer.write_raw_data(data)
data = []
if data:
writer.write_raw_data(data)
writer.commit() 运行代码后,工作路径下将生成test.mindrecord和test.mindrecord.db文件,test.mindrecord中存储了定义的计算机视觉数据信息。
2. 转换NLP类数据集 本示例主要介绍如何自定义转换NLP类数据集为MindRecord数据格式文件。为了便于演示,此处略去将文本转换为字典序数据的预处理。
首先导入代码所需的相关模块,如代码1.7所示。
代码1.7 导入相关模块
import os
import numpy as np
import mindspore.dataset as ds
from mindspore.mindrecord import FileWriter 然后定义MindRecord数据格式文件名,删除工作路径中的重名文件,并创建文件写入句柄,如代码1.8所示,其中shard_num为MindRecord数据格式文件分片数量。
代码1.8 创建文件写入句柄
mindrecord_file_name = "test.mindrecord"
if os.path.exists(mindrecord_file_name):
os.remove(mindrecord_file_name)
os.remove(mindrecord_file_name + ".db")
writer = FileWriter(file_name=mindrecord_file_name, shard_num=1) 接着定义schema数据结构信息,包含source_sos_ids、source_sos_mask、source_eos_ids、source_eos_mask、target_sos_ids、target_sos_mask、target_eos_ids、target_eos_mask字段,它们的数据类型都为int64,数据维度为- 1,表示是变长向量,如代码1.9所示。
代码1.9 定义schema数据结构信息
nlp_schema = {"source_sos_ids": {"type": "int64", "shape": [-1]},
"source_sos_mask": {"type": "int64", "shape": [-1]},
"source_eos_ids": {"type": "int64", "shape": [-1]},
"source_eos_mask": {"type": "int64", "shape": [-1]},
"target_sos_ids": {"type": "int64", "shape": [-1]},
"target_sos_mask": {"type": "int64", "shape": [-1]},
"target_eos_ids": {"type": "int64", "shape": [-1]},
"target_eos_mask": {"type": "int64", "shape": [-1]}}
writer.add_schema(nlp_schema, "it is a preprocessed nlp dataset") 为了便于演示,此处使用NumPy数组根据索引生成数据并写入MindRecord数据格式文件,如代码1.10所示,实际使用中,用户可自行将上述生成数据替换为文本经预处理后得到的字典序数据。
代码1.10 生成数据并写入MindRecord数据格式文件
data = []
for i in range(100):
sample = {"source_sos_ids": np.array([i, i + 1, i + 2, i + 3, i + 4], dtype=np.int64),
"source_sos_mask": np.array([i * 1, i * 2, i * 3, i * 4, i * 5, i *
6, i * 7], dtype=np.int64),
"source_eos_ids": np.array([i + 5, i + 6, i + 7, i + 8, i + 9, i + 10],
dtype=np.int64),
"source_eos_mask": np.array([19, 20, 21, 22, 23, 24, 25, 26, 27],
dtype=np.int64),
"target_sos_ids": np.array([28, 29, 30, 31, 32], dtype=np.int64),
"target_sos_mask": np.array([33, 34, 35, 36, 37, 38], dtype=np.int64),
"target_eos_ids": np.array([39, 40, 41, 42, 43, 44, 45, 46, 47],
dtype=np.int64),
"target_eos_mask": np.array([48, 49, 50, 51], dtype=np.int64)}
data.append(sample)
if i % 10 == 0:
writer.write_raw_data(data)
data = []
if data:
writer.write_raw_data(data)
writer.commit() 运行代码后,工作路径下会生成test.mindrecord和test.mindrecord.db文件,test.mindrecord中存储了定义的NLP数据信息。
本节介绍在MindSpore中应用自动数据增强(AutoAugment)方法。数据增强是一种基于有限的数据产生更多的等价数据,达到增加训练集的样本数量、提升网络模型泛化能力的技术手段,能够在一定程度上解决样本数量不足和样本类别分布不均的问题。数据增强通常可分为有监督的数据增强和无监督的数据增强。有监督的数据增强是指按照预设的变换规则,在已有数据的基础上进行的增强操作; 而无监督的数据增强则是指可以自主学习数据的增强方式。
目前无监督的数据增强方法主要包括两类:一类通过学习已有数据的分布特征,随机生成同分布数据的增强方法,如生成对抗网络(Generative Adversarial Network,GAN);另一类通过搜索算法寻找数据增强操作的最佳选项和执行顺序,这样训练出的网络模型能获得更高的预测准确率,如自动数据增强。
1.2.1 自动数据增强原理 自动数据增强的目标是为用户提供更灵活的数据增强策略,以得到更好的网络模型训练效果,提升模型的推理精度。MindSpore支持用户在数据处理流水线(Pipeline)中应用自动数据增强,包括基于概率的自动数据增强和基于回调参数的自动数据增强。下面将介绍这两种自动数据增强方法。
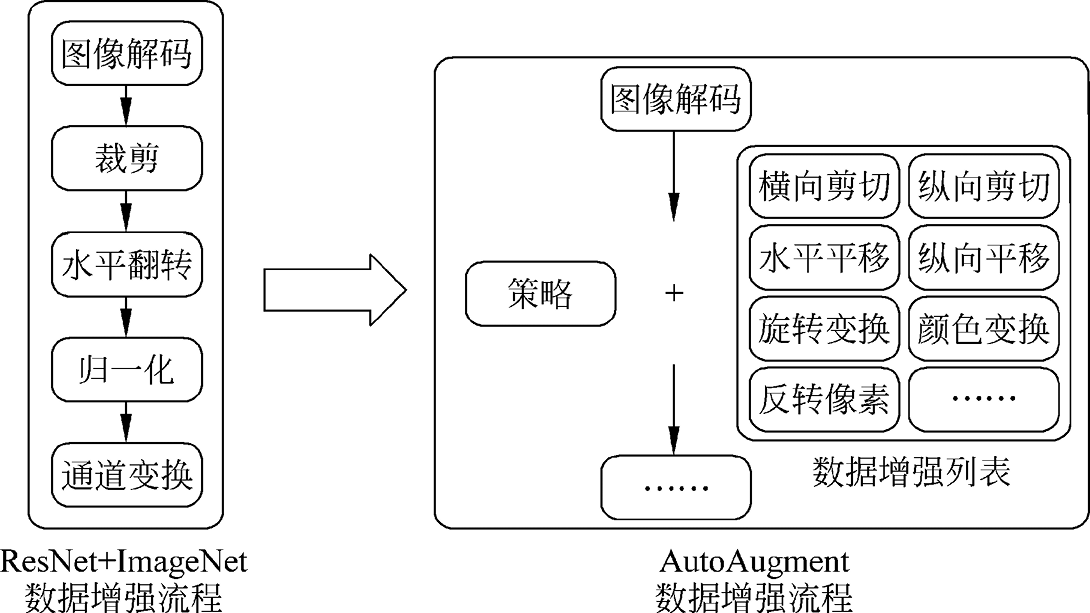
1. 基于概率的自动数据增强 针对ImageNet数据集,在2012年提出的AlexNet仍采用有监督的数据增强。而利用AutoAugment方法最终搜索出来的数据增强策略包含25个子策略组合,每个子策略组合包含两种变换,实际训练中针对每张图像随机挑选1个子策略组合,然后以一定的概率来决定是否执行子策略组合中的每种变换。图1.3所示为基于概率的自动数据增强策略。
图1.3 基于概率的自动数据增强策略
为了支持AutoAugment方法,MindSpore提供了RandomChoice、RandomApply和RandomSelectSubpolicy等接口,帮助用户基于概率进行数据增强操作。下面将分别对这些接口进行介绍。
RandomChoice即随机选择。它允许用户接收一个数据增强操作列表transforms_list,并从中随机选择一个数据增强操作执行。
如代码1.11所示,通过调用RandomChoice接口随机执行CenterCrop和RandomCrop中的一个操作。
代码1.11 调用RandomChoice接口进行数据增强操作
import mindspore.dataset.vision as vision
from mindspore.dataset.transforms import RandomChoice
transforms_list = [vision.CenterCrop(512), vision.RandomCrop(512)]
rand_choice = RandomChoice(transforms_list) RandomApply即随机概率执行。它允许用户定义一个数据增强操作列表和相应概率,在数据处理过程中,针对每张图像,允许用户接收一个数据增强操作列表,并以一定的概率顺序执行列表中的数据增强操作,默认概率为0.5。
如代码1.12所示,通过调用RandomApply接口,以0.5的概率顺序执行RandomCrop和RandomColorAdjust操作。
代码1.12 调用RandomApply接口进行数据增强操作
import mindspore.dataset.vision as vision
from mindspore.dataset.transforms import RandomApply
transforms_list = [vision.RandomCrop(512), vision.RandomColorAdjust()]
rand_apply = RandomApply(transforms_list) RandomSelectSubpolicy即随机子策略组合选择。它允许用户接收一个预置策略列表policy_list,其中包含一系列子策略组合,每一个子策略组合由若干个顺序执行的数据增强操作及其概率组成。
在数据处理的过程中,该增强操作会按照相同概率随机选择一个子策略组合,再依照子策略组合的概率顺序执行各个操作,对输入数据进行变换。
在代码1.13示例中,预置了两个子策略组合:子策略组合1(Policy 1)包含RandomRotation、RandomVerticalFlip两个操作,概率分别为0.5和1.0;子策略组合2(Policy 2)包含RandomRotation和RandomColorAdjust两个操作,概率分别为1.0和0.2。
代码1.13 调用RandomSelectSubpolicy接口进行数据增强操作
import mindspore.dataset.vision as vision
from mindspore.dataset.vision import RandomSelectSubpolicy
policy_list = [
# policy 1: (数据变换, 概率)
[(vision.RandomRotation((45, 45)), 0.5),
(vision.RandomVerticalFlip(), 1.0)],
# policy 2: (数据变换, 概率)
[(vision.RandomRotation((90, 90)), 1.0),
(vision.RandomColorAdjust(), 0.2)]
]
policy = RandomSelectSubpolicy(policy_list) MindSpore提供了多种常用的数据增强操作算子,AutoAugment方法中的数据增强操作算子与MindSpore中的数据增强操作算子的对应关系如表1.1所示。
表1.1 数据增强操作算子的对应关系
AutoAugment方法的数据增强操作算子
MindSpore的数据增强操作算子
算子说明
shearX
RandomAffine
横向剪切
shearY
RandomAffine
纵向剪切
translateX
RandomAffine
水平平移
translateY
RandomAffine
纵向平移
rotate
RandomRotation
旋转变换
color
RandomColor
颜色变换
posterize
RandomPosterize
变换色彩通道位数
solarize
RandomSolarize
反转指定范围内像素
contrast
RandomColorAdjust
调整对比度
sharpness
RandomSharpness
调整锐度
brightness
RandomColorAdjust
调整亮度
autocontrast
AutoContrast
自动调整对比度
equalize
Equalize
直方图均衡化
invert
Invert
反转变换
由此,用户可以在MindSpore中实现AutoAugment方法中的自动数据增强策略,达到提升网络模型泛化能力的效果,最终提高网络模型的推理精度。
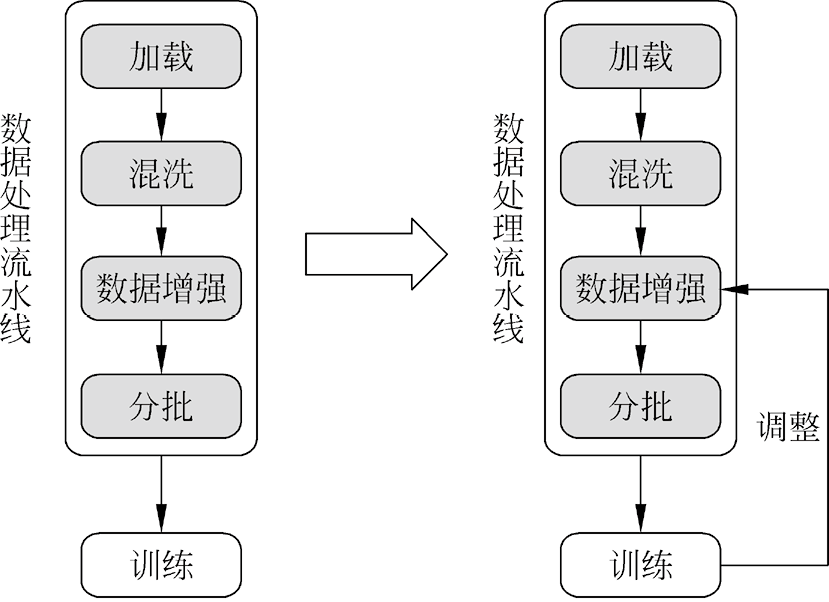
2. 基于回调参数的自动数据增强 基于回调参数的自动数据增强能够在训练过程中根据实时的超参数,如损失值、轮次数或迭代数,动态调整数据增强的方式,从而促进网络模型损失值的收敛,实现推理精度的提升,如图1.4所示。
图1.4 基于回调参数的自动数据增强
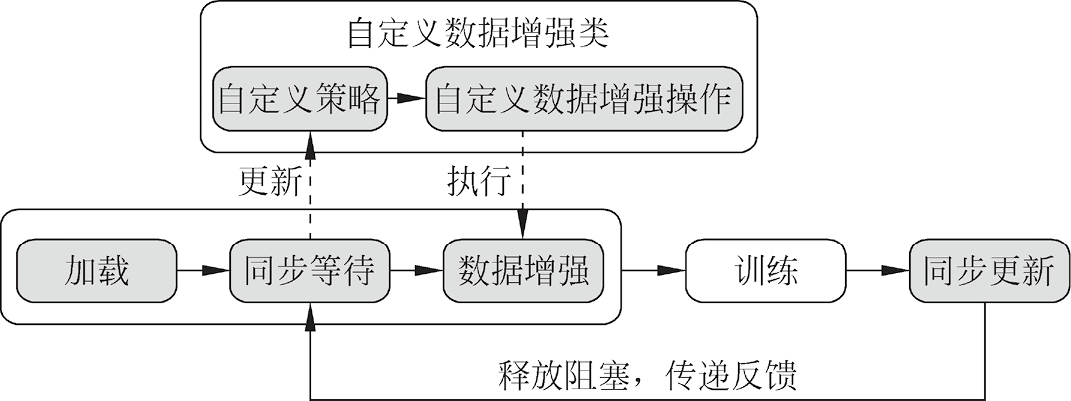
MindSpore通过同步等待与同步更新机制实现基于回调参数的自动数据增强,用户可以使用数据集加载类中的sync_wait函数与sync_update函数基于回调参数执行自定义的数据增强操作。同步等待与同步更新机制如图1.5所示。
图1.5 同步等待与同步更新机制
sync_wait是同步等待函数,用于在数据处理流水线中定义阻塞节点,可由同步更新函数触发,执行同步等待函数参数中定义的回调函数;sync_update是同步更新函数,用于将回调参数传递回同步等待函数,并释放阻塞,以执行阻塞之后的数据增强操作。两者配合使用,即可根据实时的损失值(loss)、轮次数(epoch)或步数(step)动态调整数据增强的方式。
MindSpore的sync_wait函数支持按训练数据的批次(batch)或轮次粒度,在训练过程中动态调整数据增强操作,用户可以设定阻塞条件来触发特定的数据增强操作。
sync_wait函数将阻塞整个数据处理流水线,直到sync_update函数触发用户预定义的回调函数,两者需要配合使用,函数说明如下。
sync_wait(condition_name, num_batch=1, callback=None):为数据集添加一个阻塞条件condition_name,当调用sync_update函数时执行指定的回调函数。
sync_update(condition_name, num_batch=None, data=None):用于释放对应condition_name的阻塞,并对data字段触发执行指定的回调函数。
1.2.2 自动数据增强使用示例 1. 基于概率的自动数据增强 本示例主要介绍如何实现基于概率的自动数据增强。
首先导入代码所需的相关模块,如代码1.14所示。
代码1.14 导入相关模块
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as c_vision 然后使用ImageFolderDataset接口加载图像数据集,执行图像解码与随机缩放裁剪和随机水平翻转操作,加载图像数据并执行有监督的数据增强如代码1.15所示。
代码1.15 加载图像数据集并执行有监督的数据增强
image_folder_dataset_dir = "/path/to/image_folder_dataset_directory"
image_folder_dataset = ds.ImageFolderDataset(image_folder_dataset_dir,
num_parallel_workers=4,
shuffle=True)
supervised_transform = [c_vision.RandomCropDecodeResize((256, 256)),
c_vision.RandomHorizontalFlip(0.5)]
image_folder_dataset = image_folder_dataset.map(operations=supervised_transform,
input_columns=["image"]) 接着使用RandomSelectSubpolicy接口进行随机子策略组合选择执行自动数据增强,如代码1.16所示。
代码1.16 执行自动数据增强
unsupervised_transform = c_vision.RandomSelectSubpolicy(
[[(c_vision.RandomRotation(90), 0.5),
(c_vision.RandomVerticalFlip(), 0.8)],
[(c_vision.RandomColorAdjust(), 0.2),
(c_vision.RandomRotation(45), 1)]])
image_folder_dataset = image_folder_dataset.map(
operations=unsupervised_transform,
input_columns=["image"]) 2. 基于回调参数的自动数据增强 本示例主要介绍如何实现基于回调参数的自动数据增强。
导入代码所需的相关模块如代码1.17所示。
代码1.17 导入相关模块
import numpy as np
import mindspore.dataset as ds 为了便于展示,首先使用NumpySlicesDataset接口加载预定义的列表数据,然后定义Augment类,其中的preprocess函数为自定义的数据增强方法,而update函数为用于更新数据增强参数的回调函数,如代码1.18所示。
代码1.18 加载列表数据与定义Augment类
num_list = list(range(3))
numpy_slices_dataset = ds.NumpySlicesDataset(num_list, shuffle=False)
class Augment:
def __init__(self):
self.epoch_num = 0
self.step_num = 0
def preprocess(self, data_input):
return np.array(data_input + self.step_num ** self.epoch_num - 1, )
def update(self, param):
self.epoch_num = param['epoch_num']
self.step_num = param['step_num'] 定义同步等待函数与数据增强操作,如代码1.19所示。
代码1.19 定义同步等待函数与数据增强操作
augment = Augment()
numpy_slices_dataset = numpy_slices_dataset.sync_wait(condition_name="policy",
callback=augment.update)
numpy_slices_dataset = numpy_slices_dataset.map(operations=[augment.preprocess]) 在每个步骤中通过同步更新函数传递反馈参数,并释放相应的阻塞,执行预定义的数据增强操作,如代码1.20所示。
代码1.20 定义同步更新函数与执行数据增强操作
epoch_num = 5
step = 0
itr = numpy_slices_dataset.create_dict_iterator(epoch_num)
for epoch in range(epoch_num):
for data in itr:
print("epcoh: {}, step:{}, data :{}".format(epoch, step, data))
step += 1
numpy_slices_dataset.sync_update(condition_name="policy",
data={"epoch_num": epoch, "step_num": step}) 对应的输出结果如代码1.21所示。
代码1.21 代码输出结果
epcoh: 0, step:0, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 0)}
epcoh: 0, step:1, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 1)}
epcoh: 0, step:2, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 2)}
epcoh: 1, step:3, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 0)}
epcoh: 1, step:4, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 4)}
epcoh: 1, step:5, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 6)}
epcoh: 2, step:6, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 5)}
epcoh: 2, step:7, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 49)}
epcoh: 2, step:8, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 65)}
epcoh: 3, step:9, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 80)}
epcoh: 3, step:10, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 1000)}
epcoh: 3, step:11, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 1332)}
epcoh: 4, step:12, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 1727)}
epcoh: 4, step:13, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 28561)}
epcoh: 4, step:14, data :{'column_0': Tensor(shape=[], dtype=Int32, value= 38417)} 本节介绍MindSpore的轻量化数据处理模式。在资源条件允许的情况下,为了追求更高的性能,一般使用数据处理流水线模式进行数据处理,即预先定义好数据处理流水线和模型计算图,然后由后端并发异步执行数据处理,源源不断地为模型计算图提供输入数据。与此同时,模型计算图也在并发执行计算,输出训练结果,数据处理流水线模式如图1.6所示。
图1.6 数据处理流水线模式
在网络模型训练和大规模数据推理场景下,由于计算量较大,拥有预定义的数据处理流水线可以更细粒度地规划资源的使用,更好地发挥硬件的性能,从而提高数据处理单位时间的吞吐量。而在端侧推理场景下,计算量往往较小,受计算资源和功耗的限制,构建数据处理流水线的开销不能被忽略。由此,MindSpore提供了一种轻量化数据处理模式,即Eager模式。在该模式下,能够使用命令式的编程方法,单步执行数据处理操作,并立即获得处理结果。使用Eager模式,用户可以免于构建数据处理流水线,减少了小规模计算量场景下的开销。Eager模式适用于端侧单样本推理或模型功能检查及调试等场景。MindSpore目前支持在Eager模式下执行各种数据变换,具体如下。
vision模块:子模块数据变换,基于OpenCV、Pillow实现的数据变换。
text模块:子模块数据变换,基于jieba、ICU4C实现的数据变换。
transforms模块:子模块数据变换,基于C++、Python、NumPy实现的通用数据变换。
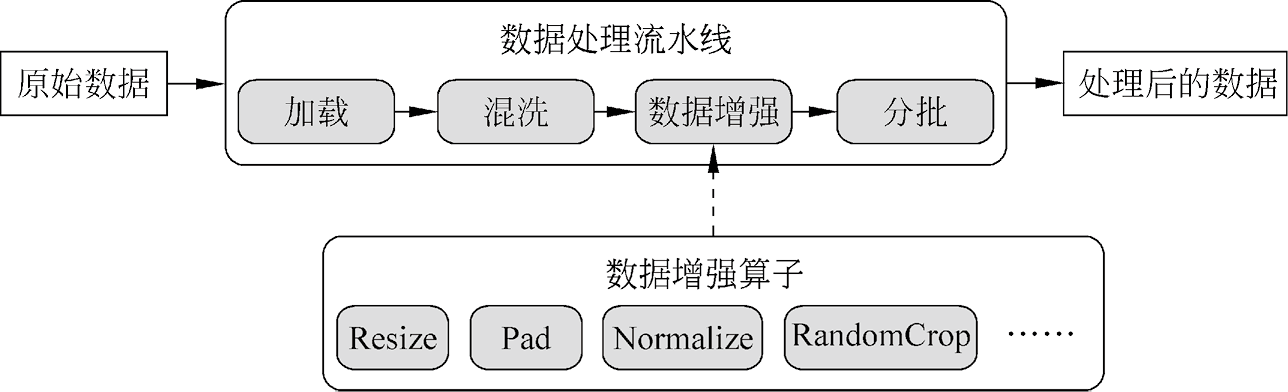
1.3.1 Eager模式原理 得益于MindSpore数据处理底层架构的低耦合性,数据增强操作算子可以被很好地抽象成独立的模块,单独地执行其计算逻辑。数据处理流水线与数据增强操作算子的关系如图1.7所示。
图1.7 数据处理流水线与数据增强操作算子的关系
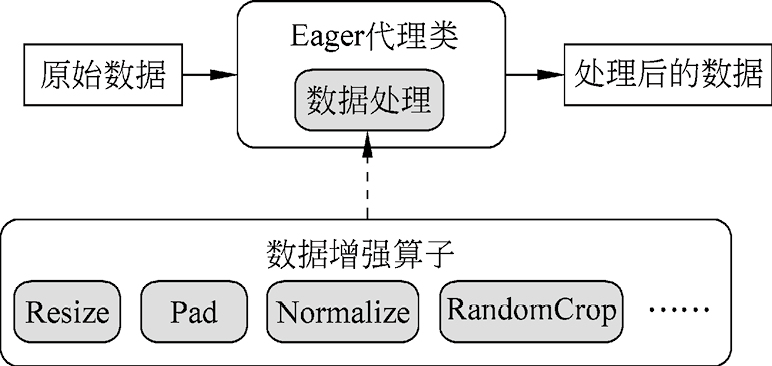
在数据处理流水线模式中,数据增强操作算子可以通过map函数映射到数据处理流水线,利用map函数的并发性提升数据增强操作的性能。而数据增强操作算子本身只是定义了一种从输入张量到输出张量的变换,可以脱离数据处理流水线单独执行。于是,通过定义一个Eager代理类来调用数据增强操作算子的计算逻辑,即可实现数据处理的单步执行,如图1.8所示。相比于定义和构建数据处理流水线模式,Eager模式的开销更小,使用更便捷。
图1.8 Eager模式
1.3.2 Eager模式使用示例 本节将简要介绍各数据变换模块Eager模式的使用方法。使用Eager模式,只需要将数据变换本身当成可执行函数。将图片数据下载到指定位置,如代码1.22所示(本书代码中的网址仅为示例)。
代码1.22 数据下载
from download import download
url="https://mindspore-website.obs.cn-north-4.×××.com/notebook/datasets/banana.jpg"
download(url, './banana.jpg', replace=True)
Downloading data from https://mindspore-website.obs.cn-north-4.×××.com/
notebook/datasets/banana.jpg (17 kB)
file_sizes: 100%|███████████████████████████| 17.1k/17.1k [00:
00<00:00, 677kB/s]
Successfully downloaded file to ./banana.jpg 1. vision模块 代码1.23展示使用mindspore.dataset.vision模块对给定图像进行数据变换。你只需要关注使用何种数据变换,而不需要关注数据流水线的代码。vision模块中数据变换的Eager模式支持将numpy.array或PIL.Image类型的数据作为入参。
代码1.23 vision模块示例
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import mindspore.dataset.vision as vision
img_ori = Image.open("banana.jpg").convert("RGB")
print("Image.type: {}, Image.shape: {}".format(type(img_ori), img_ori.size))
# 应用Resize以快速输入
op1 = vision.Resize(size=(320))
img = op1(img_ori)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# 应用CenterCrop以快速输入
op2 = vision.CenterCrop((280, 280))
img = op2(img)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# 应用Pad以快速输入
op3 = vision.Pad(40)
img = op3(img)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# 显示结果
plt.subplot(1, 2, 1)
plt.imshow(img_ori)
plt.title("original image")
plt.subplot(1, 2, 2)
plt.imshow(img)
plt.title("transformed image")
plt.show()
Image.type: <class 'PIL.Image.Image'>, Image.shape: (356, 200)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (569, 320)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (280, 280)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (360, 360) 2. text模块 代码1.24展示使用text模块对给定文本进行数据变换。text模块中数据变换的Eager模式支持将numpy.array类型的数据作为入参。
代码1.24 text模块示例
import mindspore.dataset.text.transforms as text
import mindspore as ms
# 应用UnicodeCharTokenizer以快速输入
txt = "Welcome to Beijing !"
txt = text.UnicodeCharTokenizer()(txt)
print("Tokenize result: {}".format(txt))
# 应用ToNumber以快速输入
txt = ["123456"]
to_number = text.ToNumber(ms.int32)
txt = to_number(txt)
print("ToNumber result: {}, type: {}".format(txt, txt[0].dtype)) 3. transforms模块 代码1.25展示使用transforms模块对给定数据进行数据变换。通用数据变换的Eager模式支持将numpy.array类型的数据作为入参。
代码1.25 transforms模块示例
import numpy as np
import mindspore.dataset.transforms as trans
# 应用Fill以快速输入
data = np.array([1, 2, 3, 4, 5])
fill = trans.Fill(0)
data = fill(data)
print("Fill result: ", data)
# 应用OneHot以快速输入
label = np.array(2)
onehot = trans.OneHot(num_classes=5)
label = onehot(label)
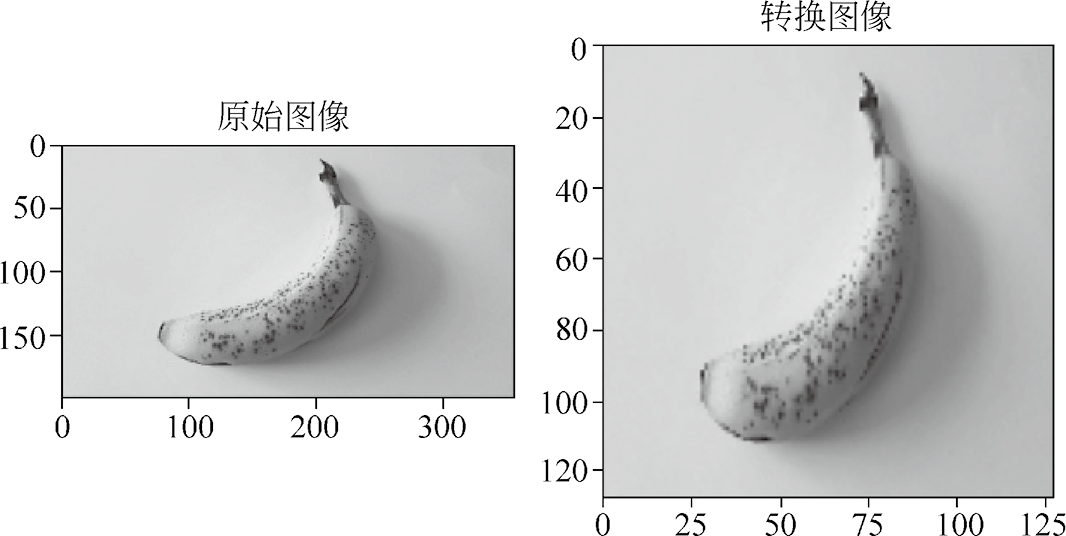
print("OneHot result: ", label) 使用PIL库加载一张图像并将其转换为RGB色彩模式,然后创建一个resize算子对象,最后将算子作用于图像。数据处理结果如图1.9所示。
图1.9 数据处理结果
本节介绍在MindSpore中缓存中间数据以加速网络模型训练的方法。数据是深度学习的基础,网络训练需要大量数据,在数据量有限的场景下,通常需要使用数据增强方法来增加样本数量,以提高数据的多样性,达到提升训练精度的目的,这无疑会耗费大量的时间和资源。同时,不难发现,无论是在数据加载还是在数据增强的阶段,都存在大量重复的操作。例如在不同的训练周期中从磁盘读取同一批数据文件,对它们进行数据增强处理。如果能够将可以重复利用的数据提前缓存起来,在后续的训练中直接使用,将大大减少数据处理的时间,提升网络训练的速度。为此,MindSpore引入缓存技术。
1.4.1 单节点缓存原理 简单来说,缓存提供了一台临时存储数据的后台服务器,用户可以把处理完成的数据存储在该服务器中,并在下次需要时,直接访问服务器来获取数据,避免不必要的重复数据处理,提高数据复用率。
单节点缓存是指服务器和客户端都在同一台物理机上,该服务器可以服务多个缓存实例。用户首先需要启用服务器,然后在训练脚本中创建客户端,并将数据客户端添加到数据处理流水线中需要执行数据缓存的位置。
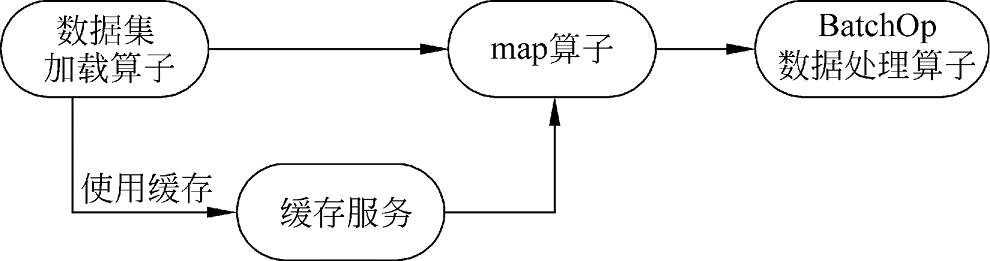
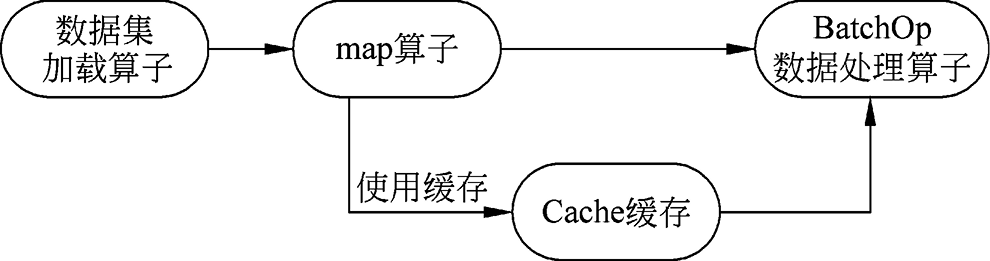
1. 单节点缓存支持的两个位置 在数据处理流水线未使用单节点缓存的情况下,通过数据集加载算子将原始数据读取到内存中,经过一系列的数据处理和增强操作(map算子和BatchOp数据处理算子),最终输入网络,如图1.10所示。
图1.10 未使用单节点缓存的数据处理流程
单节点缓存支持在两个位置进行缓存。
缓存加载后的原始数据如图1.11所示。
图1.11 缓存加载后的原始数据
用户可以在数据集加载算子时使用缓存。这将把加载完成的数据缓存到服务器中,后续若需要用到该数据则可直接从服务器中读取,避免从磁盘中重复加载。
缓存经过数据增强操作后的数据如图1.12所示。
图1.12 缓存经过数据增强操作后的数据
用户也可以在map算子中使用缓存。这将允许直接缓存经过数据增强操作(如图像裁剪、缩放等)后的数据,避免重复进行数据增强操作,减少了不必要的计算量。
以上两种类型的缓存本质上都是为了提高数据复用率,减少数据处理的时间,提高网络训练性能。
2. 单节点缓存的特点 单节点缓存具有如下特点:可提高性能,减少数据加载和处理的时间开销;可提供溢出选项,当本地内存不足时,用户可以通过修改配置将数据溢出到磁盘;缓存节点位置灵活,支持缓存原数据及经过多种数据处理或增强后的数据。
3. 单节点缓存的适用场景 单节点缓存的适用场景如下。
① CPU计算资源有限的场景。使用单节点缓存能有效减少磁盘输入/输出(Input/Output,I/O),节省CPU开销。
② 多任务共享数据集的场景。启用单节点缓存后,使用相同数据的脚本可通过访问服务器来读取数据,提高数据集加载速度。
③ 单任务重复获取同一数据的场景。例如,当数据处理流水线中使用了repeat算子时,如果使用单节点缓存,对于每一条数据而言,在使用repeat算子之前的所有数据加载和预处理操作只需要执行一次。
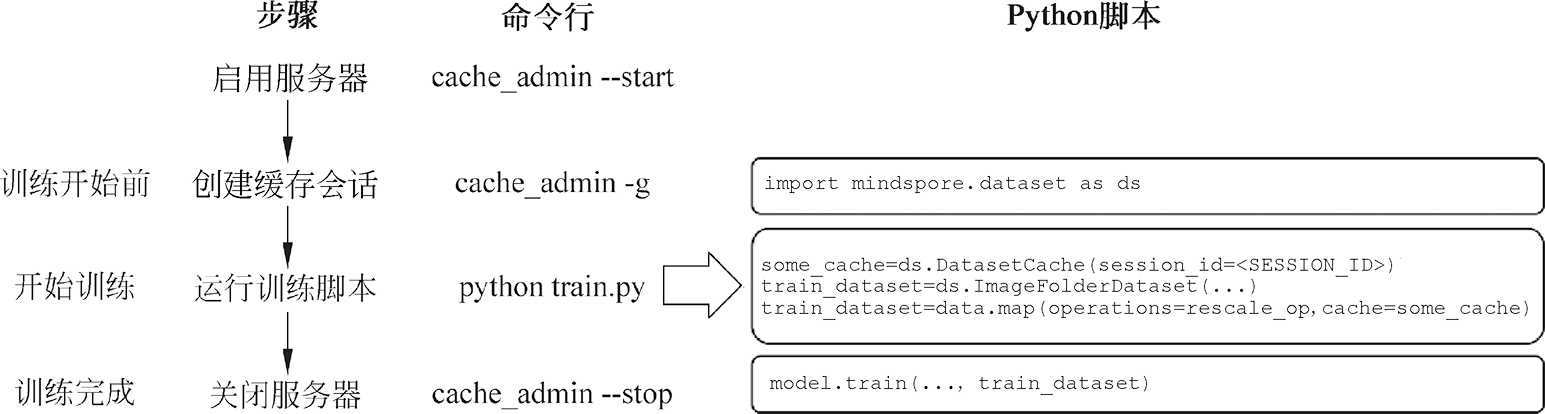
1.4.2 单节点缓存使用示例 使用单节点缓存需要两个模块:客户端和服务器。
1. 客户端 客户端提供一个名为DatasetCache的缓存API,用户可以在训练脚本中调用该API来创建缓存实例,然后将缓存实例添加到需要进行数据缓存的位置。
2. 服务器 服务器是独立于用户训练脚本的守护进程,主要用于管理缓存数据,支持存储、查找、读取,以及发生缓存未命中时对待缓存数据的写入等操作。用户可以通过自定义一系列操作和管理命令,在命令行中操作服务器的启用和关闭等。
下面将以缓存经过数据增强操作后的数据为例,演示如何使用单节点缓存。单节点缓存执行流程如图 1.13所示。
开始网络模型训练前,用户需要启用服务器并创建缓存会话。若创建成功,服务器会给当前缓存会话随机分配一个唯一标识符(ID),并通过命令行返回ID。用户需要将这个缓存会话ID保存下来。
图1.13 单节点缓存执行流程
在用户训练脚本中,创建DatasetCache实例some_cache(缓存实例),将创建的缓存会话ID作为session_id参数值传入。根据需要,将该缓存实例插入数据处理流水线的相应位置。
若把some_cache插入map算子,则在训练过程中,经过rescale_op操作后的数据将被缓存于服务器。当网络需要再次使用相同数据时,则可直接读取服务器中的数据,而无须重复进行数据加载和预处理操作。
运行训练脚本后,用户可以通过cache_admin --list_sessions命令查看当前端口号为50052的服务器中各个会话的数据缓存情况,如图1.14所示。
图1.14 查看数据缓存情况
训练完成后,用户可以通过cache_admin --stop命令关闭服务器,删除所有缓存数据。
3. 使用示例 (1)配置环境
使用单节点缓存前,需要安装MindSpore,并配置相关环境变量。以虚拟环境为例,设置方法如代码1.26所示。
代码1.26 配置相关环境变量
export LD_LIBRARY_PATH= $ LD_LIBRARY_PATH:{path_to_conda}/envs/{your_env_name}/lib
/python3.7/site-packages/mindspore:{path_to_conda}/envs/{your_env_name}/lib/
python3.7/site-packages/mindspore/lib
export PATH= $ PATH:{path_to_conda}/envs/{your_env_name}/bin (2)启用服务器
启用服务器,如代码1.27所示。
代码1.27 启用服务器
$ cache_admin --start
Cache server startup completed successfully!
The cache server daemon has been created as process id 10394 and is listening on port 50052
Recommendation:
Since the server is detached into its own daemon process, monitor the server logs
(under /tmp/mindspore/cache/log) for any issues that may happen after startup 若提示找不到libpython3.7m.so.1.0文件,在虚拟环境下尝试查找其路径并配置环境变量,如代码1.28所示。若输出代码1.27所示的信息,则表示服务器启用成功。
代码1.28 配置环境变量
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:{path_to_conda}/envs/{your_env_name}/lib 代码1.27中的命令均可使用-h和-p参数指定服务器,用户也可通过配置环境变量MS_CACHE_HOST和MS_CACHE_PORT来指定。若未指定,则默认对IP地址为127.0.0.1且端口号为50052的服务器执行相关操作。
用户可通过ps -ef |grep cache_server命令检查服务器是否已启用并查询服务器参数,也可通过cache_admin --server_info命令查看服务器的详细参数。
若要启用数据溢出功能,则用户在启用服务器时必须使用-s参数对溢出路径进行设置,否则该功能默认关闭。
(3)创建缓存会话
若服务器中不存在缓存会话,则需要创建缓存会话,得到缓存会话ID,缓存会话ID由服务器随机分配。通过cache_admin --list_sessions命令可以查看当前服务器中所有缓存会话信息,如代码1.29所示。
代码1.29 查看缓存会话信息
Listing sessions for server on port 50052
Session Cache Id Mem cached Disk cached Avg cache size Numa hit
780643335 n/a n/a n/a n/a n/a 代码1.29所示输出信息说明如下。
Session:缓存会话ID。
Cache Id:当前缓存会话中的缓存实例ID,n/a表示当前尚未创建缓存实例。
Mem cached:缓存在内存中的数据量。
Disk cached:缓存在磁盘中的数据量。
Avg cache size:当前缓存的每条数据的平均大小。
Numa hit:非均匀存储器访问(Non-Uniform Memory Access,NUMA)命中数,该值越高将获得越好的时间性能。
(4)创建缓存实例
创建Python脚本my_training_script.py,在脚本中使用DatasetCache API定义一个名为test_cache的缓存实例,并把得到的缓存会话ID作为session_id参数传入该API,如代码1.30所示。
代码1.30 创建缓存实例
import os
import mindspore.dataset as ds
# 定义变量session_id,接收前一步创建的缓存会话ID
session_id = int(os.popen('cache_admin --list_sessions | tail -1 | awk -F " " \'
{{print $1;}}\'').read())
test_cache = ds.DatasetCache(session_id=session_id, size=0, spilling=False) (5)插入缓存实例
下面的示例使用了CIFAR-10数据集。运行示例前,需要先下载该数据集并按以下目录结构存放,下载示例及解压缩后的数据集文件的目录结构如代码1.31所示。
代码1.31 CIFAR-10数据集目录结构
from download import download
import os
import shutil
url = "https://mindspore-website.obs.cn-north-4.my×××cloud.com/notebook/datasets/
cifar-10-binary.tar.gz"
path = download(url, "./datasets", kind="tar.gz", replace=True)
test_path = "./datasets/cifar-10-batches-bin/test"
train_path = "./datasets/cifar-10-batches-bin/train"
os.makedirs(test_path, exist_ok=True)
os.makedirs(train_path, exist_ok=True)
if not os.path.exists(os.path.join(test_path, "test_batch.bin")):
shutil.move("./datasets/cifar-10-batches-bin/test_batch.bin", test_path)
[shutil.move("./datasets/cifar-10-batches-bin/"+i, train_path) for i in os.listdir
("./datasets/cifar-10-batches-bin/") if os.path.isfile("./datasets/cifar-10-batches-bin/"
+i) and not i.endswith(".html") and not os.path.exists(os.path.join(train_path, i))]
./datasets/cifar-10-batches-bin
├── readme.html
├── test
│ └── test_batch.bin
└── train
├── batches.meta.txt
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
└── data_batch_5.bin 继续编写Python脚本,在应用数据增强操作算子(map算子)时将所创建的test_cache作为其cache参数传入,如代码1.32所示。
代码1.32 插入缓存实例
import mindspore.dataset.vision.c_transforms as c_vision
dataset_dir = "cifar-10-batches-bin/"
data = ds.Cifar10Dataset(dataset_dir=dataset_dir, num_samples=5, shuffle=False, num_
parallel_workers=1)
# 对map算子应用缓存
rescale_op = c_vision.Rescale(1.0 / 255.0, -1.0)
data = data.map(input_columns=["image"], operations=rescale_op, cache=some_cache)
num_iter = 0
for item in data.create_dict_iterator(num_epochs=1): # 每一条数据是一个字典
# 在本例中,每一个字典均包含键"image"
print("{} image shape: {}".format(num_iter, item["image"].shape))
num_iter += 1 运行Python脚本my_training_script.py,得到的输出结果如代码1.33所示。
代码1.33 输出结果
0 image shape: (32, 32, 3)
1 image shape: (32, 32, 3)
2 image shape: (32, 32, 3)
3 image shape: (32, 32, 3)
4 image shape: (32, 32, 3) 通过cache_admin --list_sessions命令,可以看到当前缓存会话有5条数据,说明数据缓存成功,如代码1.34所示。
代码1.34 查看缓存会话信息
Listing sessions for server on port 50052
Session Cache Id Mem cached Disk cached Avg cache size Numa hit
780643335 112867845 5 n/a 12442 5 (6)销毁缓存会话
在训练结束后,可以将当前的缓存会话销毁并释放内存。代码1.35所示为将销毁服务器中端口号为50052的缓存会话ID为780643335的缓存会话。
代码1.35 销毁缓存会话
destroy_session = 'cache_admin --destroy_session' + str(session_id)
!destroy_session
Drop session successfully for server on port 50052 (7)关闭服务器
使用完毕后,可以关闭服务器,该操作将销毁当前服务器中所有的缓存会话并释放内存,如代码1.36所示。
代码1.36 关闭服务器
$ cache_admin --stop
Cache server on port 50052 has been stopped successfully. 1.4.3 缓存优化使用示例 1. 缓存共享 对于单机多卡的分布式训练场景,允许多个相同的训练脚本共享同一个缓存,在缓存中读写数据。启用服务器,如代码1.37所示。创建缓存会话,如代码1.38所示。
代码1.37 启用服务器
$cache_admin --start
Cache server startup completed successfully!
The cache server daemon has been created as process id 39337 and listening on port 50052
Recommendation:
Since the server is detached into its own daemon process, monitor the server logs
(under /tmp/mindspore/cache/log) for any issues that may happen after startup 代码1.38 创建缓存会话
#!/bin/bash
# 该shell脚本将启用并行流水线
# 获取数据集目录的路径
if [ $# != 1 ]
then
echo "Usage: sh cache.sh DATASET_PATH"
exit 1
fi
dataset_path="$1"
# 生成并行流水线可共享的会话ID
result=$(cache_admin -g 2>&1)
rc=$?
if [ $rc -ne 0 ]; then
echo "some error"
exit 1
fi
# 从结果字符串中抓取会话ID
session_id=$(echo $result | awk '{print $NF}') 缓存会话ID传入训练脚本,如代码1.39所示。
代码1.39 缓存会话ID传入训练脚本
# 令Python脚本获取session_id
num_devices=4
for p in $(seq 0 $((${num_devices}-1))); do
python my_training_script.py --num_devices "$num_devices" --device "$p" --session_
id $session_id --dataset_path $dataset_path
done 下面的示例中使用了CIFAR-10数据集。创建并编写Python脚本my_training_script.py,通过代码1.40接收传入的session_id,并在定义缓存实例时将其作为参数传入。运行训练脚本,如代码1.41所示。
代码1.40 创建并应用缓存实例
import argparse
import mindspore.dataset as ds
parser = argparse.ArgumentParser(description='Cache Example')
parser.add_argument('--num_devices', type=int, default=1, help='Device num.')
parser.add_argument('--device', type=int, default=0, help='Device id.')
parser.add_argument('--session_id', type=int, default=1, help='Session id.')
parser.add_argument('--dataset_path', type=str, default=None, help='Dataset path')
args_opt = parser.parse_args()
# 对数据集应用缓存
test_cache = ds.DatasetCache(session_id=args_opt.session_id, size=0, spilling=False)
dataset = ds.Cifar10Dataset(dataset_dir=args_opt.dataset_path, num_samples=4, shuffle=
False, num_parallel_workers=1,
num_shards=args_opt.num_devices, shard_id=args_opt.
device, cache=test_cache)
num_iter = 0
for _ in dataset.create_dict_iterator():
num_iter += 1
print("Got {} samples on device {}".format(num_iter, args_opt.device)) 代码1.41 运行训练脚本
$ sh cache.sh cifar-10-batches-bin/
Got 4 samples on device 0
Got 4 samples on device 1
Got 4 samples on device 2
Got 4 samples on device 3 通过cache_admin --list_sessions命令,可以看到当前缓存会话中只有一组数据,说明缓存共享成功,如代码1.42所示。
代码1.42 查看当前缓存会话
Listing sessions for server on port 50052
Session Cache Id Mem cached Disk cached Avg cache size Numa hit
3392558708 821590605 16 n/a 3227 16 在训练结束后,可以将当前的缓存会话销毁并释放内存,如代码1.43所示。
代码1.43 销毁缓存会话
$ cache_admin --destroy_session 3392558708
Drop session successfully for server on port 50052 使用完毕后,可以关闭服务器,如代码1.44所示。
代码1.44 关闭服务器
$ cache_admin --stop
Cache server on port 50052 has been stopped successfully. 2. 缓存加速 为了使较大的数据集在多台服务器之间共享,缓解对单台服务器磁盘空间的需求,用户通常可以选择使用网络文件系统(Network File System,NFS),如华为云的NFS存储服务器来存储数据集,这就是缓存加速技术。
然而,访问NFS数据集的开销通常较大,导致使用NFS数据集进行训练的时间较长。为了提高NFS数据集的训练性能,我们可以使用缓存,将数据集以张量的形式缓存在内存中。经过缓存后,后续轮次就可以直接从内存中读取数据,避免了访问远程NFS。
需要注意的是,在训练过程的数据处理流程中,数据集经加载后通常还需要进行一些随机的数据增强操作,如RandomCropDecodeResize,若将缓存添加到具有随机性的操作之后,会导致第一次的数据增强操作结果被缓存下来,后续从服务器中读取的结果均为第一次数据增强操作后的数据,这将导致数据失去随机性,影响训练网络的精度。
因此,我们可以选择直接在数据集读取操作之后添加缓存。本节将采用这种方法,以MobileNetV2网络为例进行介绍。创建管理缓存的Shell脚本cache_util.sh,如代码1.45所示。
代码1.45 创建管理缓存的Shell脚本cache_util.sh
bootup_cache_server()
{
echo "Booting up cache server..."
result=$(cache_admin --start 2>&1)
echo "${result}"
}
generate_cache_session()
{
result=$(cache_admin -g | awk 'END {print $NF}')
echo "${result}"
} 在启用NFS数据集训练的Shell脚本run_train_nfs_cache.sh中,为位于NFS存储服务器上的数据集训练场景启用服务器,生成缓存会话保存在Shell变量CACHE_SESSION_ID中,如代码1.46所示。
代码1.46 启用服务器并生成缓存会话
CURPATH="${dirname "$0"}"
source ${CURPATH}/cache_util.sh
bootup_cache_server
CACHE_SESSION_ID=$(generate_cache_session) 在开始训练时将CACHE_SESSION_ID以及其他参数传入,在Python的参数解析脚本args.py的train_parse_args函数中,通过代码1.47接收传入的cache_session_id,在Python的训练脚本train.py中调用train_parse_args函数解析传入的cache_session_id等参数,在定义数据集dataset时将cache_session_id作为参数传入。
代码1.47 传入并解析参数
import argparse
def train_parse_args():
...
train_parser.add_argument('--enable_cache',
type=ast.literal_eval,
default=False,
help='Caching the dataset in memory to speedup dataset processing, default
is False.')
train_parser.add_argument('--cache_session_id',
type=str,
default="",
help='The session id for cache service.')
train_args = train_parser.parse_args()
from src.args import train_parse_args
args_opt = train_parse_args()
dataset = create_dataset(
dataset_path=args_opt.dataset_path,
do_train=True,
config=config,
enable_cache=args_opt.enable_cache,
cache_session_id=args_opt.cache_session_id) 在定义数据处理流程的Python脚本dataset.py中,根据传入的enable_cache和cache_session_id参数,创建DatasetCache实例并将其插入ImageFolderDataset,如代码1.48所示。
代码1.48 创建实例
def create_dataset(dataset_path, do_train, config, repeat_num=1, enable_cache=False,
cache_session_id=None):
...
if enable_cache:
nfs_dataset_cache = ds.DatasetCache(session_id=int(cache_session_id), size=0)
else:
nfs_dataset_cache = None
if config.platform == "Ascend":
rank_size = int(os.getenv("RANK_SIZE", '1'))
rank_id = int(os.getenv("RANK_ID", '0'))
if rank_size == 1:
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=
8, shuffle=True, cache=nfs_dataset_cache)
else:
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=
8, shuffle=True, num_shards=rank_size, shard_id=rank_id, cache=nfs_
dataset_cache) 运行run_train_nfs_cache.sh,得到的输出结果如代码1.49所示。
代码1.49 输出结果
epoch: [ 0/ 200], step:[ 2134/ 2135], loss:[4.682/4.682], time:[3364893.166], lr:[0.780]
epoch time: 3384387.999, per step time: 1585.193, avg loss: 4.682
epoch: [ 1/ 200], step:[ 2134/ 2135], loss:[3.750/3.750], time:[430495.242], lr:[0.724]
epoch time: 431005.885, per step time: 201.876, avg loss: 4.286
epoch: [ 2/ 200], step:[ 2134/ 2135], loss:[3.922/3.922], time:[420104.849], lr:[0.635]
epoch time: 420669.174, per step time: 197.035, avg loss: 3.534
epoch: [ 3/ 200], step:[ 2134/ 2135], loss:[3.581/3.581], time:[420825.587], lr:[0.524]
epoch time: 421494.842, per step time: 197.421, avg loss: 3.417
... 代码1.50展示了GPU服务器上使用缓存与不使用缓存的第一个轮次和平均每个轮次的完成时间对比情况。
代码1.50 GPU服务器上使用缓存与不使用缓存的第一个轮次和平均每个轮次的完成时间对比情况
| 4p, MobileNetV2, imagenet2012 | without cache | with cache |
| -------------------------------------- | ------------- | ---------- |
| first epoch time | 1649s | 3384s |
| average epoch time (exclude first epoch)| 458s | 421s | 可以看到使用缓存后,第一个轮次的完成时间增加较多,这主要是缓存数据写入服务器导致的。但是,在缓存数据写入之后的每个轮次都可以获得较大的性能提升。因此,训练的轮次数目越多,使用缓存的收益将越明显。
以运行200个轮次为例,使用缓存可以使端到端的训练总用时从92791s降至87163s,共节省5628s。
使用完毕后,可以关闭服务器,如代码1.51所示。
代码1.51 关闭服务器
$ cache_admin --stop
Cache server on port 50052 has been stopped successfully. 3. 缓存性能调优 使用缓存能够在一些场景下,尤其是在数据预处理流水线包含decode等高复杂度的数据增强操作的场景下,获得显著的性能提升。在这些场景下,使用缓存后,用户不需要在每个轮次重复执行数据增强操作,可节省较多时间。
也可以在简单网络的训练和推理过程中使用缓存。相比于复杂网络,简单网络的训练耗时占比更小,因此在该场景下使用缓存,会获得更显著的时间性能提升。
然而,在以下场景中使用缓存可能不会获得明显的时间性能提升。
① 系统内存不足、缓存未命中等因素将导致缓存在时间性能上提升不明显。因此,在使用缓存前,应检查系统可用内存是否充足,并选择适当的缓存大小。
② 缓存溢出过多会导致时间性能变差。因此,在使用可随机访问的数据集(如通过ImageFolderDataset访问的数据集)进行数据加载的场景中,尽量不要允许缓存溢出至磁盘。
③ 在BERT等自然语言处理类网络中使用缓存,通常不会获得时间性能提升。因为在自然语言处理场景下通常不会使用decode等高复杂度的数据增强操作。
④ 使用non-mappable数据集(如TFRecordDataset)的数据处理流水线在第一个轮次的时间开销较大。根据当前的缓存机制,non-mappable数据集需要在第一个轮次训练开始前将所有数据写入服务器,因此第一个轮次的完成时间较长,从而影响整个训练的时间性能。
4. 缓存限制 当前,GeneratorDataset、PaddedDataset和NumpySlicesDataset等数据集类不支持缓存。其中,GeneratorDataset、PaddedDataset和NumpySlicesDataset的实现依赖GeneratorOp,在不支持缓存的数据集类中使用缓存,其报错信息中会显示“There is currently no support for GeneratorOp under cache”。
经过batch、concat、filter、repeat、skip、split、take或zip处理后的数据不支持缓存。
本节介绍如何加快数据处理的速度。在线数据处理场景中,数据首先经过加载和增强,然后输入网络模型进行训练。数据处理过程往往运行在CPU上,而网络模型训练过程往往运行在GPU或AI芯片上。随着AI技术的发展,GPU和AI芯片的算力都有了显著的提高。根据“黄氏定律”,GPU和AI芯片的算力还将以每年一倍的速率持续增长。数据的处理如果不够高效,会造成GPU和AI芯片因等待训练数据而空闲,成为网络模型训练性能的瓶颈。而优化数据处理,就是在有限的CPU算力下,最大化数据处理性能。
常见的数据处理流程如图1.15所示,其中各个步骤介绍如下。
load:加载,指从各种异构存储设备中将训练数据加载到内存中,通常涉及数据访问和解析等处理。
shuffle:随机洗牌,指打乱数据集中样本的排列顺序,使不同周期接收数据的顺序各不相同,防止模型过拟合。
map:映射,指将用户定义的数据处理和增强方法插入数据处理流水线。
batch:分批,指将完整数据集划分为多个批次,模型每次只接收一个批次,这样可以提高模型收敛的效率。
图1.15 常见的数据处理流程
用户可以使用MindSpore提供的API,快速实现数据加载、处理及增强等功能。在上述每个步骤中,如果能够合理地使用这些API,将极大地提升数据处理速度。此外,MindSpore运行环境下的存储、架构和计算资源也会在一定程度上影响数据处理性能。下面将介绍数据处理的优化方法。
1. 优化数据加载 MindSpore支持加载计算机视觉或自然语言处理等领域的常用数据集、特定格式数据集及自定义数据集。不同数据集加载接口的底层实现方式不同,性能也存在着差异,如表1.2所示。
表1.2 不同数据集加载接口的底层实现方式和性能对比情况
数据集
底层实现方式
性能
常用数据集
C++
高
特定格式数据集
C++
高
自定义数据集
Python
中
对于已经提供加载接口的常用数据集,优先使用MindSpore提供的数据集加载接口进行加载,可获得较好的加载性能; 对于没有提供加载接口的数据集,如果其数据的文件格式在MindSpore中存在对应的加载接口,则可使用该数据集加载接口进行加载,可获得较好的加载性能;其余情况下,建议先将数据集中的数据转换为MindRecord数据格式,再使用MindSpore的MindDataset接口进行加载。此外,用户也可以使用MindSpore提供的GeneratorDataset接口自定义数据集的加载方法。在资源条件允许的前提下,用户可以通过数据集加载接口中的num_parallel_workers参数设置数据加载时使用的线程数,通过多线程并行进一步提升数据加载性能。
以CIFAR-10数据集为例,优先使用MindSpore提供的Cifar10Dataset接口进行加载,如代码1.52所示。
代码1.52 使用Cifar10Dataset接口加载CIFAR-10数据集
from download import download
import os
import shutil
url = "https://mindspore-website.obs.cn-north-4.my×××cloud.com/notebook/datasets/
cifar-10-binary.tar.gz"
path = download(url, "./datasets", kind="tar.gz″, replace=True) # 下载CIFAR-10数据集
test_path = "./datasets/cifar-10-batches-bin/test"
train_path = "./datasets/cifar-10-batches-bin/train"
os.makedirs(test_path, exist_ok=True)
os.makedirs(train_path, exist_ok=True)
if not os.path.exists(os.path.join(test_path, "test_batch.bin")):
shutil.move("./datasets/cifar-10-batches-bin/test_batch.bin", test_path)
[shutil.move("./datasets/cifar-10-batches-bin/"+i, train_path) for i in os.listdir
("./datasets/cifar-10-batches-bin/") if os.path.isfile("./datasets/cifar-10-batches-bin/"
+i) and not i.endswith(".html") and not os.path.exists(os.path.join(train_path, i))]
./datasets/cifar-10-batches-bin
├── readme.html
├── test
│ └── test_batch.bin
└── train
├── batches.meta.txt
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
└── data_batch_5.bin 也可先将CIFAR-10数据集中的数据转换为MindRecord数据格式,然后使用MindDataset接口进行加载。还可使用GeneratorDataset接口加载自定义数据集,创建迭代器读取数据记录。代码1.53和代码1.54分别展示了上述加载方法,并且采取多进程优化方案,启用了4个进程并发完成任务,最后针对数据创建了字典迭代器,通过迭代器读取了一条数据记录。
代码1.53 将CIFAR-10数据集中的数据转换为MindRecord数据格式并加载
import mindspore.dataset as ds
cifar10_path = "./datasets/cifar-10-batches-bin/train"
# 为读取数据创建Cifar10Dataset
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4)
# 创建一个字典迭代器,并通过该迭代器读取数据记录
print(next(cifar10_dataset.create_dict_iterator()))
{'image': Tensor(shape=[32, 32, 3], dtype=UInt8, value=
[[[181, 185, 194],
[184, 187, 196],
[189, 192, 201],
...
[178, 181, 191],
[171, 174, 183],
[166, 170, 179]],
[[182, 185, 194],
[184, 187, 196],
[189, 192, 201],
...
[180, 183, 192],
[173, 176, 185],
[167, 170, 179]],
[[185, 188, 197],
[187, 190, 199],
[193, 196, 205],
...
[182, 185, 194],
[176, 179, 188],
[170, 173, 182]],
...
[[176, 174, 185],
[172, 171, 181],
[174, 172, 183],
...
[168, 171, 180],
[164, 167, 176],
[160, 163, 172]],
[[172, 170, 181],
[171, 169, 180],
[173, 171, 182],
...
[164, 167, 176],
[160, 163, 172],
[156, 159, 168]],
[[171, 169, 180],
[173, 171, 182],
[177, 175, 186],
...
[162, 165, 174],
[158, 161, 170],
[152, 155, 164]]]), 'label': Tensor(shape=[], dtype=UInt32, value= 6)} 代码1.54 使用GeneratorDataset接口加载自定义数据集
import numpy as np
def generator_func(num):
for i in range(num):
yield (np.array([i]))
# 为读取数据创建GeneratorDataset
dataset = ds.GeneratorDataset(source=generator_func(5), column_names=["data"], num_
parallel_workers=4)
# 创建一个字典迭代器,并通过该迭代器读取数据记录
print(next(dataset.create_dict_iterator())) 2. 优化shuffle性能 shuffle操作主要是对有序的数据集或者进行过repeat操作的数据集进行混洗。MindSpore专门为用户提供了shuffle函数,它是基于内存缓存方式实现的,其buffer_size参数越大,混洗程度越大,但内存占用、时间消耗也会更大。该接口支持用户在数据处理流水线全流程中随时对数据进行混洗。
但是因为shuffle操作是基于内存缓存方式实现的,使用该方式的性能不如在数据集加载接口中设置shuffle参数为True直接对数据进行混洗的性能。
优化shuffle性能的建议如下:直接设置数据集加载接口中的shuffle参数为True进行数据混洗;如果使用的是shuffle函数,当混洗效果无法满足需求时,可通过调大buffer_size参数的值来优化混洗效果;当机器内存占用率过高时,可通过调小buffer_size参数的值来降低内存占用率。
接下来分别介绍使用数据集加载接口Cifar10Dataset的shuffle参数和shuffle函数进行数据混洗。
代码1.55所示为使用数据集加载接口Cifar10Dataset加载CIFAR-10数据集,这里使用的是二进制格式的CIFAR-10数据集,并且设置shuffle参数为True来进行数据混洗,最后针对数据创建了字典迭代器,通过迭代器读取数据记录。
代码1.55 使用shuffle参数进行数据混洗
cifar10_path = "./datasets/cifar-10-batches-bin/train"
# 为读取数据创建Cifar10Dataset
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, shuffle=True)
# 创建一个字典迭代器,并通过该迭代器读取数据记录
print(next(cifar10_dataset.create_dict_iterator())) 代码1.56所示为使用shuffle函数进行数据混洗,参数buffer_size设置为3,数据通过调用GeneratorDataset接口自定义生成。
代码1.56 使用shuffle函数进行数据混洗
def generator_func():
for i in range(5):
yield (np.array([i, i+1, i+2, i+3, i+4]),)
ds1 = ds.GeneratorDataset(source=generator_func, column_names=["data"])
print("before shuffle:")
for data in ds1.create_dict_iterator():
print(data["data"])
ds2 = ds1.shuffle(buffer_size=3)
print("after shuffle:")
for data in ds2.create_dict_iterator():
print(data["data"]) 3. 优化数据增强 虽然MindSpore提供了多种常用的数据增强接口,但用户可以根据需要自定义数据增强方法。例如,在计算机视觉任务中,MindSpore提供了在C++层和在Python层实现的数据增强接口,分别包含在mindspore.dataset.vision.c_transforms(以下简称c_transforms)模块和mindspore.dataset.vision.py_transforms(以下简称py_transforms)模块中。不同数据增强方法的性能差异如表1.3所示。
表1.3 不同数据增强方法的性能差异
数据增强方法
底层实现
性能
c_transforms
C++(主要基于OpenCV)
高
py_transforms
Python(主要基于PIL)
中
自定义数据增强
Python
低
对于提供了C++底层实现的数据增强方法,优先使用c_transforms模块中的接口进行数据增强,可以获得更好的处理性能;对于没有提供C++底层实现,但提供了Python底层实现的数据增强方法,建议使用py_transforms模块中的接口进行数据增强;在剩余情况下,需要用户在Python层自行实现自己的数据增强方法,然后使用map函数将其插入数据处理流水线。
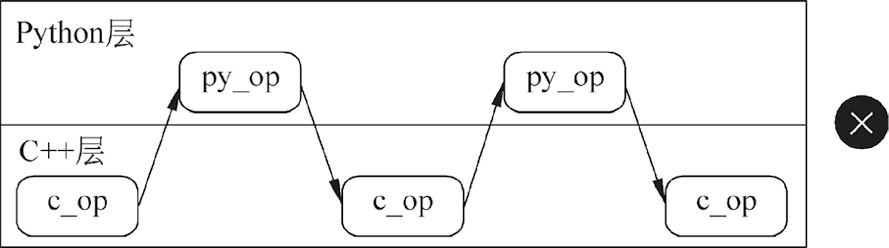
MindSpore支持用户同时使用c_transforms模块和py_transforms模块中的数据增强方法,但由于两者底层实现不同,过度地混用将增加资源开销,降低处理性能。建议用户单独使用c_transforms模块或py_transforms模块中的算子;或者先使用其中一种,再使用另一种。建议不要在两种不同底层实现模块的数据增强接口之间频繁切换,如图1.16所示。
图1.16 不要在两种不同底层实现模块的数据增强接口之间频繁切换
在MindSpore中,用户首先需要定义要使用的数据增强方法,然后使用map函数将其插入数据处理流水线。在资源条件允许的前提下,用户可以通过map函数的num_parallel_workers参数设置数据增强使用的线程数,通过多线程并行进一步提升数据增强的性能。
以CIFAR-10数据集为例,优先使用MindSpore提供的c_transforms模块中的接口进行数据增强。代码1.57展示了如何使用c_transforms模块中的RandomResizedCrop算子对CIFAR-10数据集中的图像进行随机缩放裁剪,结果如图1.17所示。
代码1.57 使用c_transforms模块对图像进行数据增强
import mindspore.dataset.vision as vision
import matplotlib.pyplot as plt
cifar10_path = "./datasets/cifar-10-batches-bin/train"
# 为读取数据创建Cifar10Dataset
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4)
transforms = vision.RandomResizedCrop((800, 800))
# 通过dataset.map()对数据集应用数据变换
cifar10_dataset = cifar10_dataset.map(operations=transforms, input_columns="image",
num_parallel_workers=4)
data = next(cifar10_dataset.create_dict_iterator())
plt.imshow(data["image"].asnumpy())
plt.show() 使用MindSpore提供的py_transforms模块进行数据增强的方法与上述类似,只需将c_transforms模块中的接口替换为py_transfroms模块中的接口即可。
在某些情形下,用户可以通过编写Python函数自定义数据增强方法。以CIFAR- 10数据集为例,代码1.58展示了通过编写Python函数自定义数据增强方法进行数据增强,数据增强采用多进程优化方案,启用了4个进程并发完成任务,结果如图1.18所示。
图1.17 使用c_transforms模块对图像进行数据增强的结果
图1.18 使用自定义数据增强方法对图像进行数据增强的结果
代码1.58 通过编写Python函数自定义数据增强方法进行数据增强
def generator_func():
for i in range(5):
yield (np.array([i, i+1, i+2, i+3, i+4]),)
ds3 = ds.GeneratorDataset(source=generator_func, column_names=["data"])
print("before map:")
for data in ds3.create_dict_iterator():
print(data["data"])
def preprocess(x):
return (x**2,)
ds4 = ds3.map(operations=preprocess, input_columns="data", python_multiprocessing=
True, num_parallel_workers=4)
print("after map:")
for data in ds4.create_dict_iterator():
print(data["data"])
before map:
[0 1 2 3 4]
[1 2 3 4 5]
[2 3 4 5 6]
[3 4 5 6 7]
[4 5 6 7 8]
after map:
[ 0 1 4 9 16]
[ 1 4 9 16 25]
[ 4 9 16 25 36]
[ 9 16 25 36 49]
[16 25 36 49 64] 4. 优化数据并行 (1)优化多线程数目
前文提到在数据加载和数据增强中,可以通过设置接口的num_parallel_workers参数来调整数据处理时的并发线程数目,这是利用CPU的多核、多线程特点来提升数据处理的性能。如果用户没有手动设置num_parallel_workers参数,各个数据处理操作将默认使用8个线程来进行并发处理。在使用MindSpore进行单机单卡或单机多卡训练时,num_parallel_workers参数的设置应遵循以下原则:各数据加载和处理操作所设置的num_parallel_workers参数值之和应不大于CPU所支持的最大线程数,否则将造成各个操作间的资源竞争;在设置num_parallel_workers参数之前,建议先使用MindSpore的Profiling工具(性能分析工具)分析训练中各个操作的性能,将更多的资源分配给性能较差的操作,即设置更大的num_parallel_workers参数值,使得各个操作之间的吞吐量达到平衡,避免不必要的等待。
在单机单卡训练场景中,增大num_parallel_workers参数值往往能直接提高处理性能;但在单机多卡训练场景中,由于CPU竞争激烈,一味增大num_parallel_workers参数值可能会使性能劣化,需要在实际训练中尝试使用折中数值。
(2)优化缓存队列容量
在MindSpore的数据处理流水线中,各个数据加载和数据增强操作并发异步执行数据处理运算。流水线中的相邻节点存在消费者与生产者的关系,即当前节点消费上游节点的数据,并生产数据给下游节点,节点之间通过流水线队列缓存数据,如图1.6所示。在默认条件下,流水线队列的容量为16,即最多允许缓存16条数据。当流水线队列存满时,意味着上游节点的性能比下游节点好,将阻塞上游节点的处理操作;当流水线队列为空时,意味着上游节点的性能比下游节点差,将阻塞下游节点的处理操作。用户可以通过mindspore.dataset.config模块中的set_prefetch_size接口同时设置所有流水线队列的容量,设置合理的容量参数将有利于提高数据处理的性能,可参考以下场景进行配置。
当数据处理操作的内存占用过高时,应同时减小num_parallel_workers和prefetch_size参数值,即减小流水线队列的总容量,进而减少内存使用;在使用自定义数据增强方法时,如果系统的CPU线程较少,建议将prefetch_size参数设置为8,并将map函数的python_multiprocessing参数设置为False。而设置更小的prefetch_size参数值可以提前阻塞性能较好的处理操作,从而释放CPU计算资源,减少资源竞争;当batch_size较大时,如果上游节点的num_parallel_workers与prefetch_size参数值较小,可能导致流水线队列中的数据不足以组成一个批次,进而阻塞batch操作的执行。一般而言,上游算子的num_parallel_workers与prefetch_size参数值之积应不小于batch_size,才能达到供需平衡。
5. 优化运行环境配置 由于MindSpore的数据处理主要在主机端进行,运行环境的配置也会对处理性能产生影响,主要体现在存储设备、NUMA架构和CPU计算资源等方面,下面将从这几个方面分别进行阐述。
(1)存储设备
数据的加载过程涉及频繁的磁盘操作,磁盘的读写性能直接影响了数据加载的速度。当数据集较大时,推荐使用固态盘进行数据存储,固态盘的读写速度比普通磁盘快,能够减小I/O操作对数据处理性能的影响。
一般而言,加载后的数据会被缓存到操作系统的页面缓存中,这在一定程度上降低了后续读取的开销,加快了后续轮次的数据加载速度。用户也可以通过MindSpore提供的单节点缓存技术,手动缓存加载或增强后的数据,避免进行重复的数据加载和数据增强。
(2) NUMA架构
NUMA是为了解决传统的对称式多处理机(Symmetric Multi P rocessor,SMP)架构中的可扩展性问题而实现的一种内存架构。在传统的SMP架构中,多个处理器共用一条内存总线,容易发生带宽不足、内存冲突等问题。而在NUMA架构中,处理器和内存被划分为多个组,每个组称为一个节点(Node),各个节点拥有独立的集成内存控制器(Integrated Memory Controller,IMC)总线,用于节点内的通信,不同节点间则通过快速路径互连(Quick Path Interconnect,QPI)总线进行通信。对于某一节点来说,处在同节点内的内存被称为本地内存,处在其他节点内的内存被称为外部内存,访问本地内存的延迟小于访问外部内存的延迟。在数据处理过程中,可以通过将进程与节点绑定,来减小访问内存的延迟。代码1.59展示了在启用Python脚本train.py时将进程与节点绑定的命令。
代码1.59 将进程与节点绑定的命令
numactl --cpubind=0 --membind=0 python train.py (3) CPU计算资源
尽管可以通过多线程并行技术加快数据处理的速度,但是实际运行时并不能保证CPU计算资源能被完全利用。如果能够人为地先完成CPU计算资源的配置,在一定程度上可以提高CPU计算资源的利用率。
在分布式训练中,同一设备上可能会启用多个训练进程。默认情况下,各个进程的资源分配与抢占将遵循操作系统本身的策略,当进程较多时,频繁的资源竞争可能会导致数据处理性能的下降。如果能够先设置各个进程可用的CPU计算资源,就能避免这种资源竞争带来的开销。代码1.60展示了一种粗粒度的资源分配命令,指定了进程能够使用的节点ID。而代码1.61展示了细粒度的命令,它指定了进程能够使用的节点中的CPU核,其中“0-15”表示ID为0~15的CPU核。
代码1.60 分配进程的节点ID
numactl --cpubind=0 python train.py 代码1.61 分配进程的CPU核
taskset -c 0-15 python train.py 出于降低功耗的考虑,操作系统会根据需要适时调整CPU的运行频率,但更低的功耗意味着计算性能的下降,会减慢数据的处理。要想充分发挥CPU的最大算力,需要手动设置CPU的运行频率。如果发现操作系统的CPU运行模式为平衡模式或者节能模式,可以将其修改为性能模式,以提升数据处理的性能,设置命令如代码1.62所示。
代码1.62 设置CPU运行模式为性能模式的命令
cpupower frequency-set -g performance



 1.1 转换数据集为MindRecord
1.1 转换数据集为MindRecord