版权信息 书名:计算机视觉导论:从传统方法到智能技术
ISBN:978-7-115-66317-7
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
版 权 著 谢 源 高 岩 全红艳
责任编辑 佘 洁
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线: (010)81055410
反盗版热线: (010)81055315
内 容 提 要 本书系统整合了计算机视觉领域的经典算法与现代智能视觉技术,全面介绍了该领域的核心理论与方法体系。本书内容丰富,涵盖了以下主要知识点:计算机视觉基本概念及技术基础、人类视觉感知与图像特征多层表达、图像特征与图像对齐、二值图像分析、区域分割、纹理特征分析、相机成像模型和标定技术、光流计算、三维重建、传统目标检测与识别算法、传统目标跟踪算法、智能目标识别与跟踪、三维点云特征及理解、视觉语言模型等。
本书适合作为计算机科学与技术、软件工程及电子类专业本科生、研究生的教材或教学参考书,也可供从事计算机视觉应用与研究的开发人员和科研人员使用。对于计算机视觉先行课程知识欠缺的读者,本书提供了循序渐进、易于理解的学习路径,帮助他们系统掌握计算机视觉算法原理和关键技术。
前 言 近年来,随着信息技术的快速发展,计算机视觉已在地理信息、安全监控、医学辅助诊断、媒体传播等多个领域得到广泛应用,尤其是深度学习和人工智能技术的迅猛进步,推动了计算机视觉在目标识别、运动目标跟踪和三维重建等方向取得一系列重要的理论研究及实际应用成果。学生及专业技术人员掌握计算机视觉的基本理论知识,提升实践能力,已成为该技术应用的重要基础。
本书在介绍计算机视觉基础理论的同时,探讨了该领域的技术演进和前沿应用。内容不仅涵盖计算机视觉传统算法理论,也引入了计算机视觉的深度学习方法,充分契合人工智能技术发展的需要。
在内容安排上,本书将计算机视觉传统算法理论与智能视觉技术相结合,在介绍每个计算机视觉算法理论知识要点时,从传统算法理论到深度学习技术依次展开。本书涵盖以下主要知识点:计算机视觉基本概念及技术基础、人类视觉感知与图像特征多层表达、图像特征与图像对齐、二值图像分析、区域分割、纹理特征分析、相机成像模型和标定技术、光流计算、三维重建、传统目标检测与识别算法、传统目标跟踪算法、智能目标识别与跟踪、三维点云特征及理解、视觉语言模型等。
考虑到计算机视觉算法理论的抽象性,本书采用了“知识实例化”编写方法,通过具体实例来阐述算法过程。此外,为了强化学生的创新意识和工程实践能力,本书着重加强实践技能的训练。为满足实践教学需求,本书还配有实践教材《计算机视觉实践教程:基于PyTorch》,两者在风格和内容上保持一致,均具有语言通俗易懂、实例丰富、逻辑清晰的特点。
除此之外,本书还具备以下特点。
● 传统算法与深度学习算法无缝融合。 本书依据计算机视觉算法的知识演化过程,系统整合了传统算法和深度学习前沿算法。在讲解过程中,两部分知识融为一体。例如,在讲解特征概念时,结合计算机视觉传统算法的多分辨率感知与深度学习的多层特征,帮助读者深刻理解两者的统一性,从而深入掌握核心知识。
● 面向零基础读者。 本书编写考虑到基础知识欠缺的读者,力求将视觉知识讲解得浅显明了,便于计算机、电子及其他领域的人员快速入门。
● 知识传授深入浅出。 本书将复杂的计算机视觉理论阐述得通俗易懂,便于专业技术人员和学生学习。在此基础上,由浅入深地介绍计算机视觉的实现方法和关键技术。
● 教学实例丰富。 为了增强学习的趣味性和理解深度,本书提供了大量实例,以展示算法理论的实现过程。
● 理论与实践同步。 理论教材与课程实践教材的知识安排顺序相匹配, 便于同步教学。同时,理论教学中的编程实例与实践教学的深度学习编程框架相对应,采用常见的深度学习框架编程,便于学生使用开源资源。
● 介绍多种编程方法。 根据实际工程需要,本书采用常用的编程软件对算法进行描述。在理论知识讲解中,实例采用Skimage、PIL或者OpenCV编程,并且将PyTorch作为智能算法教学的深度学习框架。实践教学中也同步提供典型实例的深度学习编程框架,满足各专业教学及实践应用的要求。
● 提供习题以巩固知识。 各章后附有精选习题,涵盖了学生能力培养的内容,如查阅资料及代码、列举前沿技术等,帮助学生巩固知识点。实践教材中包含实践内容和实践过程引导内容,以及问题思考,助力相关专业的实践教学。
● 紧跟技术前沿。 本书涵盖最新的技术发展,从原理、技术到最新动态,内容丰富,适合理论教学和技术开发人员参考学习。
本书融入了作者多年积累的计算机视觉算法教学实例和实验素材。在撰写本书的过程中,作者还参考了大量计算机视觉方面的图书、网站和其他资料,并借鉴了国内外知名期刊和国际顶级会议中的新技术,这里没有一一列举,在此一并表示感谢。
由于作者水平和经验有限,书中难免存在疏漏或不足之处,诚挚欢迎广大读者批评指正,并提出宝贵意见,我们会将读者的反馈作为进一步完善和提高教材质量的重要动力!
第1章 计算机视觉基础 本章详细阐述了计算机视觉的基本概念及其技术基础,具体内容包括计算机视觉的发展历史和应用领域、数字图像处理技术、人工智能相关技术,以及计算机视觉编程的基础知识。
1.1 概述本节首先介绍计算机视觉(Computer Vision,CV)的基本概念,然后深入探讨计算机视觉技术的发展历史和应用场景,此外还将讨论计算机视觉技术与其他学科之间的关系,并详细阐述计算机视觉算法流程。
1.1.1 计算机视觉概念 计算机视觉是一门模仿人类视觉感知过程的科学,它通过计算机算法对采集到的数据(如图像和视频)进行分析和理解,从而赋予计算机识别、分类、跟踪物体的能力,以及深入理解、分析客观世界的三维结构。计算机视觉的研究目标是使计算机算法能够模仿生物视觉的功能,实现对三维空间世界的理解和控制,以及模拟和表达。
计算机视觉算法与人类感知和理解客观世界的过程既有相似之处,也有不同。人类对三维世界的感知和理解过程如图1-1a所示。首先,三维空间中的信息通过人眼在视网膜上成像,视网膜的功能是将外界景物的光学信息投影至其表面。接着,这些光学信息被转换成电信号,通过视神经传递到大脑的枕叶视觉中枢。最后,经过大脑的神经解析,人类能够对三维世界的景物进行判断和理解。这个过程展示了人类如何将视觉信息转化为对环境的认知和理解。
图1-1 人类生物视觉感知与计算机视觉算法解析过程
计算机视觉算法借鉴人类生物感知的机制,旨在实现对客观世界的感知和理解。如图1-1b所示,在计算机视觉算法解析过程中,需要使用数码相机或数码摄像机等设备对三维空间进行拍摄,这一过程也被称为图像或视频采集,目的是获取数字图像或视频序列。然后,算法从这些图像或视频序列出发,对三维世界的景物进行推理和判断。
总之,无论是人类的感知过程还是计算机视觉算法的解析过程,都需要对客观世界的内容进行数据采集,并且都需要对这些数据进行信息解析。这样做的目的是获取具有指导意义的关于客观世界的结构和内容信息,从而使得计算机能够像人类一样理解和应对周围的环境。
1.1.2 计算机视觉的发展历史及应用 1. 计算机视觉发展历史 计算机视觉历经数十年的发展,其起源可追溯至图像分析和识别技术的早期探索阶段。随着时间的推移,三维视觉理解技术逐渐成熟,尤其是近年来人工智能技术的快速发展,计算机视觉迎来了迅猛发展的新阶段。
(1)第一阶段:图像分析和识别的初级阶段
20世纪50年代,数字图像处理技术进入初步探索阶段。在这个时期,研究人员提出了视觉通路中信息的分层处理机制,并在生物视觉研究领域取得了突破性进展。1957年,美国国家标准局的科学家Russell Kirsch扫描了一张其幼子的照片,并研制了一个图像处理系统,该系统将照片分割成176×176的网格,然后输入计算机,成功存入有限的存储空间,这就是历史上的第一张数字图像,也为计算机视觉研究奠定了基础。
从20世纪50年代开始,数字图像处理技术迎来了快速发展阶段,同时,二维图像分析和识别技术也逐步兴起。Russell等研究人员设计并开发了第一台数字图像扫描仪,该扫描仪能够将图片转换为灰度值,并被二进制机器理解。这些突破性进展标志着图像分析和识别技术的开端,并推动了光学字符识别、显微图像和航空图像分析等领域的计算机视觉研究。
1959年,神经生理学家David Hubel和Torsten Wiesel发表了在计算机视觉领域具有重要影响力的论文“Receptive Fields of Single Neurones in The Cat’s Striate Cortex”。该论文描述了视觉皮层神经元的核心反应特性,以及猫的视觉体验及皮层结构。在实验中,Hubel和Wiesel将微电极植入猫的视觉皮层,发现猫的不同视觉区域处理着不同的信息,例如直线、角度及物体移动的动作和方向。他们的研究揭示了视觉通路中的信息分层处理机制,这一发现深化了人们对视觉系统的理解,标志着计算机视觉技术的突破性进展。
(2)第二阶段:三维计算机视觉研究开端
20世纪60年代,计算机视觉进入了发展的第二阶段,这一时期出现了三维场景理解的研究工作,并在数字图像采集技术方面取得了一定的突破。
1965年,麻省理工学院博士生Lawrence Roberts在其论文中首次尝试探索三维场景理解问题。他提出从二维图像的拓扑信息推断出三维结构,为计算机视觉领域三维世界内容的理解技术研究奠定了理论基础。
1966年,麻省理工学院的Seymour Papert等人发起了夏季视觉项目,他们指导学生设计一个图像分割任务,旨在从图像中提取非重叠的目标,这一研究虽未成功,但这是计算机视觉任务研究的正式起步。
1969年,贝尔实验室的科学家Willard S. Boyle和George E. Smith在电荷耦合器件(CCD)的研发上取得了重大进展,这种器件能够将光子转化为电脉冲。这项技术的发展为计算机视觉领域实现高质量数字图像采集奠定了基础。
(3)第三阶段:计算机视觉理论体系形成
20世纪70年代中期,麻省理工学院人工智能实验室正式开设计算机视觉课程。1977年,David Marr提出了视觉计算理论框架,这是一个较为完善的视觉系统框架,包含计算理论层、表征与算法层、实现层三个层次的研究方法。Marr认为视觉是一个复杂的信息处理过程,分为基元图阶段、2.5维图阶段和三维模型阶段,旨在从二维图像中提取基本几何元素,恢复场景的深度、法线方向、轮廓等信息,并最终识别三维物体。这一自上而下的视觉处理框架,虽无反馈机制,但对计算机视觉领域产生了深远影响,为后续研究提供了理论基础和方法论指导。
1982年,即Marr去世后两年,他的具有重要影响力的论文“Vision: A Computational Investigation into The Human Representation and Processing of Visual Information”发表,同年,他的著作《视觉》出版,这标志着计算机视觉成为一门独立学科。
20世纪80年代中期,主动视觉、物体识别等新理论迅速发展。Marr的理论为该领域提供了基本的哲学思想和研究方法,也为该领域的研究提供了新的起点,因此,20世纪80年代被认为是计算机视觉领域的繁荣阶段。
与此同时,日本计算机科学家Kunihiko Fukushima受到Hubel和Wiesel的启发,建立了第一个卷积神经网络Neocognitron。这个模型包括多个卷积层,其感受野具有权重向量,能够进行模式识别。1989年,法国科学家Yann LeCun将一种支持式学习算法应用于Neocognitron框架中,后来进一步发展出第一个现代经典的卷积神经网络LeNet-5(1998年投入实际使用),并将其应用于字符识别及邮政编码识别的商业产品开发中。
(4)第四阶段:计算机视觉算法理论成熟和技术应用广泛
20世纪90年代,计算机视觉技术开始广泛应用于工业环境,同时多视图几何的视觉理论迅速发展。在这一时期,利用Marr理论无法解决图像识别及导航中存在的问题,促使学界涌现主动视觉、定性视觉、目的视觉等不同学派。这些学派围绕图像获取、摄像机标定、特征提取、立体匹配、三维重建及目标识别问题展开了深入探索。
在这一阶段感知分组问题仍然是计算机视觉领域需要解决的关键问题之一,1997年,加州大学伯克利分校教授Jitendra Malik发表了一篇论文,提出让机器使用图论算法将图像分割成较为合理的部分,尝试解决感知分组问题。
到了90年代末,研究人员基于特征进行对象识别研究,David Lowe发表论文“Object Recognition from Local Scale-Invariant Features”,提出了基于旋转、位置和具有光照不变性的局部特征,是当时计算机视觉领域较为经典的研究成果。
(5)第五阶段:计算机视觉技术飞速发展与人工智能算法并行推进
至21世纪初,传统的机器学习方法在计算机视觉技术发展中仍然发挥着重要的作用。2001年,Paul Viola和Michael Jones提出了首个实时人脸检测框架。他们利用机器学习方法,设计了一个强大的二元分类器,通过使用AdaBoost算法训练弱分类器并级联,实现了实时人脸检测,这一成果后来被富士通公司采用,设计和生产了基于Viola-Jones算法的实时人脸检测相机。
随着人工智能技术的发展,计算机视觉在全局优化问题上的研究取得进展,在大规模标注数据集的处理能力方面有很大提升。此外,视频分析问题也成为研究热点。随着计算机视觉领域的不断发展,基准图像数据集和标准评估指标的需求日益增长,以便比较不同模型的性能。
牛津大学及英国的研究者于2005年至2012年间组织了竞赛项目PASCAL VOC,提供了用于对象分类的标准化数据集和数据注释工具,其中数据集涵盖人、飞机、车辆、动物等20个不同类别的目标图像注释。该项目为评估目标检测算法提供了公开数据集。
2009年,可变形部件模型(Deformable Part Model,DPM)的提出标志着基于变形特征的模型构建技术研究的一个重要进展。DPM将目标对象分解为多个部分,并在这些部分之间施加约束,以提高对象检测任务的性能。
2010年,大型可视目标识别竞赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge,简称ImageNet挑战赛)首次举办,从此每年举行一次,为研究者提供了交流的平台。ImageNet比赛项目提供一个用于视觉对象识别软件研究的大型可视化数据库,包含超过1400万张图像,涵盖1000个对象类别。目前,ImageNet挑战赛已经成为目标分类和检测领域的基准。
自2012年起,卷积神经网络(Convolutional Neural Network,CNN)得到了迅猛发展。这一进步得益于计算机硬件性能的飞跃,特别是NVIDIA的可并行化图形处理单元(GPU)为深度学习的复杂计算提供了有力支持。同时,丰富的多模态数据集也为基于深度学习的计算机视觉技术提供了有效的数据资源。
计算机视觉的传统算法理论及技术被广泛应用于目标检测、图像分类、语义分割等任务。基于CNN的典型计算机视觉模型不断涌现。
2012年,Alex等人提出了AlexNet,这是一个基于深度卷积神经网络的模型,AlexNet通过多层卷积和池化层有效地提取图像特征,然后经过全连接层得到分类结果。这个模型能够处理多达1000个类别的分类任务(最后一层全连接层有1000个神经元,对应1000个类别)。在2012年的ImageNet挑战赛上,AlexNet取得了重大突破,这被认为是人工智能时代的一个标志性事件。AlexNet的成功推动了计算机视觉技术的进步,促进了基于深度学习的智能目标识别、智能目标分割、智能运动跟踪等算法的发展。
2014年,牛津大学计算机视觉组的Karen Simonyan和Andrew Zisserman提出深度卷积神经网络VGGNet,其以简单的网络结构著称,在2014年的ImageNet挑战赛上,VGGNet以出色的成绩获得了广泛关注。VGGNet的两个典型结构是VGG16和VGG19,它们成为许多后续研究和应用的基础架构。
2014年,谷歌团队提出了深度卷积神经网络GoogLeNet,该网络采用了Inception模块,利用多尺度的卷积核进行特征提取,显著提高了网络的表达能力。同时,GoogLeNet也因高效网络设计,在2014年的ImageNet挑战赛上取得了第一名的好成绩。
DeepLab V1是Liang-Chieh Chen等人于2014年提出的语义分割模型,该模型基于VGG16网络架构,采用了空洞卷积和多尺度融合来提高分割的准确性。2016年,Liang-Chieh Chen等人提出DeepLab V2,该模型采用多尺度特征融合策略,主干网络从VGG16替换为更强大的ResNet-101,并采用ASPP(Atrous Spatial Pyramid Pooling,空洞空间金字塔池化)编码提高网络性能。2017年,Liang-Chieh Chen提出DeepLab V3,该模型基于ResNet结构设计,使用空洞卷积结构,并结合批归一化处理,得到了很好的网络性能。2018年,Liang-Chieh Chen提出DeepLab V3+,它在DeepLab V3的基础上增加了解码器,融合空洞空间金字塔池化对网络性能进行改进。
2014年,Ian J. Goodfellow提出生成对抗网络(Generative Adversarial Network,GAN)模型,该模型由生成器和判别器构成。GAN模型在计算机视觉领域得到了广泛的应用,特别是在训练过程中,生成器的目标是生成尽可能真实的图片以欺骗判别器中的判别网络,而判别器则致力于区分生成图像的真伪。在这一过程中,生成器和判别器之间形成了一个动态的“博弈过程”。2017年,在计算机视觉会议ICCV(International Conference on Computer Vision)上,Jun-Yan Zhu等人提出CycleGAN,它通过两个GAN网络进行训练,实现不同风格图像之间的转换。2018年,Tero Karras等人提出StyleGAN网络,该网络能够精确控制生成图像的属性,实现了高质量、逼真图像的生成。
2014年,Ross Girshick等人在计算机视觉会议CVPR(Computer Vision and Pattern Recognition)上提出R-CNN(Region-based CNN),它是首个将CNN 引入目标检测领域的模型,其目标检测过程如下:产生候选区域、基于AlexNet进行特征提取、候选区域类别判断和使用回归器对候选框位置进行调整。在R-CNN模型中,特征提取阶段采用了AlexNet,其他阶段则仍然依赖计算机视觉传统算法中的目标检测技术,该模型成为目标检测传统方法向深度学习方法过渡的里程碑。
2015年,Kaiming He等人提出深度卷积神经网络ResNet,通过设计残差连接结构,使得网络层数显著增加,同时有效解决了深度网络训练中的梯度消失和梯度爆炸问题。ResNet在2015年的ImageNet挑战赛上取得了第一名的好成绩。
2015年,Ross B. Girshick等人提出了Faster R-CNN模型,结合R-CNN和Fast R-CNN的优点,改进网络性能。Faster R-CNN由卷积层RPN(Region Proposal Network)、ROI池化层和目标分类组成,将图像特征提取、候选框提取、边界框回归和目标分类设计在一个网络中,使得检测速度大大提升。
2016年,Kaiming He等人提出了Mask R-CNN,它将检测任务和分割任务并行,不仅提升了检测速度,而且获得了COCO 2016分割挑战赛的冠军。该网络包含两个阶段,第一个阶段为RPN生成候选框;第二个阶段包括分类和边界框回归,并且增加了全卷积网络分支来实现目标分割。
2016年,Joseph Redmon等人提出了YOLO(You Only Look Once)目标检测模型,通过使用神经网络进行回归估计,实现快速且高效的目标检测。与计算机视觉传统算法中的目标检测相比,YOLO的网络结构比较简单,具有很强的通用性和可扩展性,可以应用于多种不同的目标检测任务。YOLO在目标检测时,对整个图像只需要执行一次前向梯度传播,因此能够实现快速检测。目前出现了YOLOv1~YOLOv12的模型系列,这个系列算法的主干网络由初始的Darknet发展为灵活的多种框架。YOLO系列算法已经被广泛应用于各种计算机视觉任务,在工程领域的目标识别问题中起到引领作用。
2017年,谷歌团队的Ashish Vaswani等人在NeurIPS(Neural Information Processing Systems)会议上发表的“Attention Is All You Need”论文中提出了Transformer网络。Transformer由编码器(Encoder)和解码器(Decoder)组成,Encoder 和Decoder均包含6个模块,采用多头注意力(Multi-Head Attention)进行设计,使得模型可以并行训练,而且能够拥有全局信息。Transformer网络最初应用于自然语言处理(NLP)的问题研究,后来被拓展至计算机视觉领域。2021年,Alexey Dosovitskiy在ICLR(International Conference on Learning Representations)发表的论文“An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”中提出了ViT(Vision Transformer)网络。该网络将图像分解为固定大小的块,然后进行线性嵌入编码,将其作为Transformer的token进行处理。目前,ViT已经被广泛应用于计算机视觉领域,覆盖图像分割和目标识别等任务。在此基础上,衍生出Swin Transformer和SwinIR等视觉Transformer变体,它们被用于解决图像分割、图像复原等更复杂的问题。
视觉语言模型(Visual Language Model,VLM)是一类结合视觉和语言模态的模型,也被称为联合视觉语言模型。VLM的主要特点是结合了图像和自然语言处理技术,通过将图像与文本联合学习,实现对视觉内容的深入理解。VLM技术在视觉理解方面主要解决两个典型问题:①结合文本信息(提示词)的输入,对视觉数据中的图像或者视频进行充分理解和解析,并输出图像理解的结果;②根据图像内容和上下文信息生成相关的自然语言描述,为计算机赋予更接近人类的视觉理解能力。
GPT(Generative Pre-trained Transformer)模型起源于2018年,采用Transformer架构设计,并在大规模语料库上进行预训练,在各种通用自然语言处理任务上表现出色。GPT模型经历了多个版本的迭代,包括2018年推出的GPT-1、2019年推出的GPT-2、2020年推出的GPT-3、2023年发布的GPT-4,以及2024年发布的GPT-4o。特别值得一提的是,GPT-4V在视觉输入的安全部署方面,展现出在多模态方面的强大处理能力。
2. 计算机视觉技术的应用 随着技术的持续进步,计算机视觉已广泛应用于医学、生物学、军事等多个领域,并在指纹识别、人脸识别、图像和视频检索、电影特效制作、虚拟现实及电子商务等领域扮演了重要角色。此外,计算机视觉技术在计算机辅助诊断、数字图像编码及农业领域的应用成果也逐步显现。
计算机视觉在医疗领域有着广泛的应用。早在1966年,莱德利首次提出了计算机辅助诊断(Computer Aided Diagnosis,CAD)的概念。医学影像是计算机辅助诊断的主要工具,而X光作为最早的医学影像技术之一,自1895年德国物理学家威廉·康拉德·伦琴发现X射线以来,为医学影像的获取奠定了基础。1972年,英国EMI公司的工程师豪斯费尔德发明了X射线计算机断层成像(简称CT),并首次将其用于头颅诊断,由此发展出了基于头颅断层影像的三维重建技术。1975年,该公司又成功研发了全身无损伤CT诊断装置,豪斯费尔德也因此获得了诺贝尔生理学或医学奖。目前,医学影像领域除了X射线技术,还发展了多种影像技术。X射线影像技术包括血管摄影、心血管摄影、CT、牙齿摄影和X光片等。伽马射线影像技术包括伽马摄影、正电子发射断层扫描(PET)和单光子发射断层扫描(SPECT)。磁共振成像技术包括核磁共振(NMR)成像和磁共振成像(MRI)。超声波影像技术则包括A型超声检查、B型超声检查、M型超声检查和D型多普勒超声检查。这些技术的发展极大地推动了医疗诊断的进步。随着计算机辅助诊断技术的发展,医学影像在其中扮演了重要角色。人工智能技术的快速发展进一步推动了医学影像智能分割与重建技术的进步,使得智能化水平得到显著提升。基于人工智能的CAD技术已被广泛应用于疾病诊断和治疗决策中。
在计算机视觉技术发展初期,图像处理的主要目标是提升图像质量,以解决采集过程中由噪声、干扰信号、编码等因素导致的图像质量下降问题,使图像更符合人类视觉感知的需求。20世纪70年代中期,出现了图像区域分割技术,标志着图像处理技术进入了包括图像解释在内的中级阶段。到了70年代末,Marr提出了视觉计算理论,标志着图像处理技术进入高级阶段,即图像理解阶段,计算机视觉技术迅速发展。
随着技术的发展,计算机视觉在图像压缩和编码领域取得了显著进展。图像压缩和编码技术在多个实际应用中具有重要价值,包括可视电话、会议电视、数字电视和高清晰度电视等。在技术发展的早期,美国国家航空航天局(National Aeronautics and Space Administration,NASA)采用了专用差分脉冲编码调制技术进行图像压缩。随后,自适应编码策略被引入,发展出自适应差分脉冲编码调制技术。随着压缩技术的不断进步,出现了频率域处理方法,最初主要采用傅里叶变换,后来发展出离散余弦变换和帧间运动补偿技术。进入80年代,国际标准化组织推出了H系列和MPEG标准,这些标准为运动图像压缩编码技术的发展奠定了基础。1993年,MPEG-1编码标准发布,随后在1994年推出了MPEG-2标准,专门用于高清晰度电视图像的编码。到了2000年,MPEG-4编码的出现进一步推动了移动通信技术的快速发展。
20世纪90年代初,小波理论和小波变换方法的诞生为数字图像的分解与重构提供了更有效的手段。图像分解旨在将原始图像分解为结构和纹理两部分,这在图像处理领域是一个极具挑战性的逆问题。新技术的发展使得这一问题得到了有效解决。小波压缩理论及技术的发展为图像信息的安全传输带来了新的进展。
计算机视觉技术从20世纪70年代开始在农业领域得到应用和发展,主要用于动植物和农产品等生物体的检测和质量评估。以下是计算机视觉技术在农业领域的几个主要应用:①果品形状与缺陷检测及分级。从1985年开始,Rehkugler利用图像的灰度值来检测苹果的缺陷。后来,Sarkar和Wolfe在研究中利用8邻域链码边界的曲率来描述西红柿的形状,并开发出计算机视觉西红柿品质分级装置。1989年,Miller等人在桃子分级研究中提出了一种较准确的损伤面积计算方法。1990年,Shearer研究了基于计算机视觉的圆椒颜色分级算法,该算法准确率较高。同年,Brandon开发的视觉系统能够获取胡萝卜顶部图像,并根据外形特征实现对胡萝卜顶部形状的分级。随后,苹果质量检测及橘子、桃子、西红柿等其他水果的分级应用也逐渐出现。②粮食作物质量的检测与分级。1985年,小麦品种分类技术出现。1986年,玉米籽粒裂纹计算机视觉无损检测技术问世,检测精度达到90%。随后,人们研究了小麦品种分级的视觉算法、玉米籽粒分类的算法及蚕豆品质评价算法等。③植物生长状态监测。1992年,人们利用图像分析手段对植株叶子的生长情况进行监测,以进一步控制灌溉系统。Vande Vooren等人在1992年利用图像分析测定蘑菇的各种形态学特征,描述蘑菇的形状特征,并预测同一胚芽体细胞的发芽状况。后来,人们利用计算机视觉分析手段研究了基于水稻生长情况及施肥量来预测产量的数学模型。此外,计算机视觉技术还广泛应用于杂草与病虫害防治,以及农业生物孵化研究等方面。
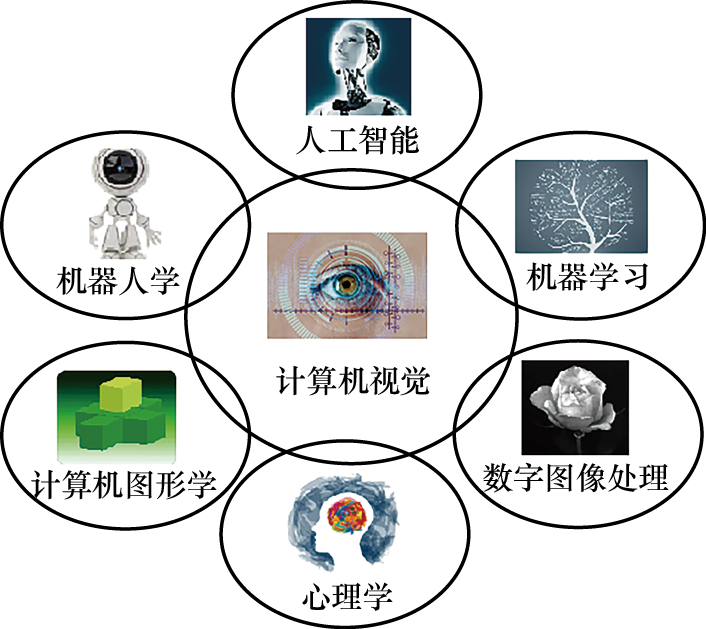
1.1.3 与其他学科之间的关系 计算机视觉的核心任务是模拟人类视觉感知机制,通过分析图像或视频数据,结合机器学习等优化方法,实现对视觉信息的分析和理解。计算机视觉算法的研究过程通常包括数据采集、图像预处理、图像分析、算法优化、分析结果表达等。如图1-2所示,计算机视觉与计算机图形学、数字图像处理、人工智能、机器人学、机器学习、心理学都有着密切的联系。
图1-2 计算机视觉与其他学科之间的关系图
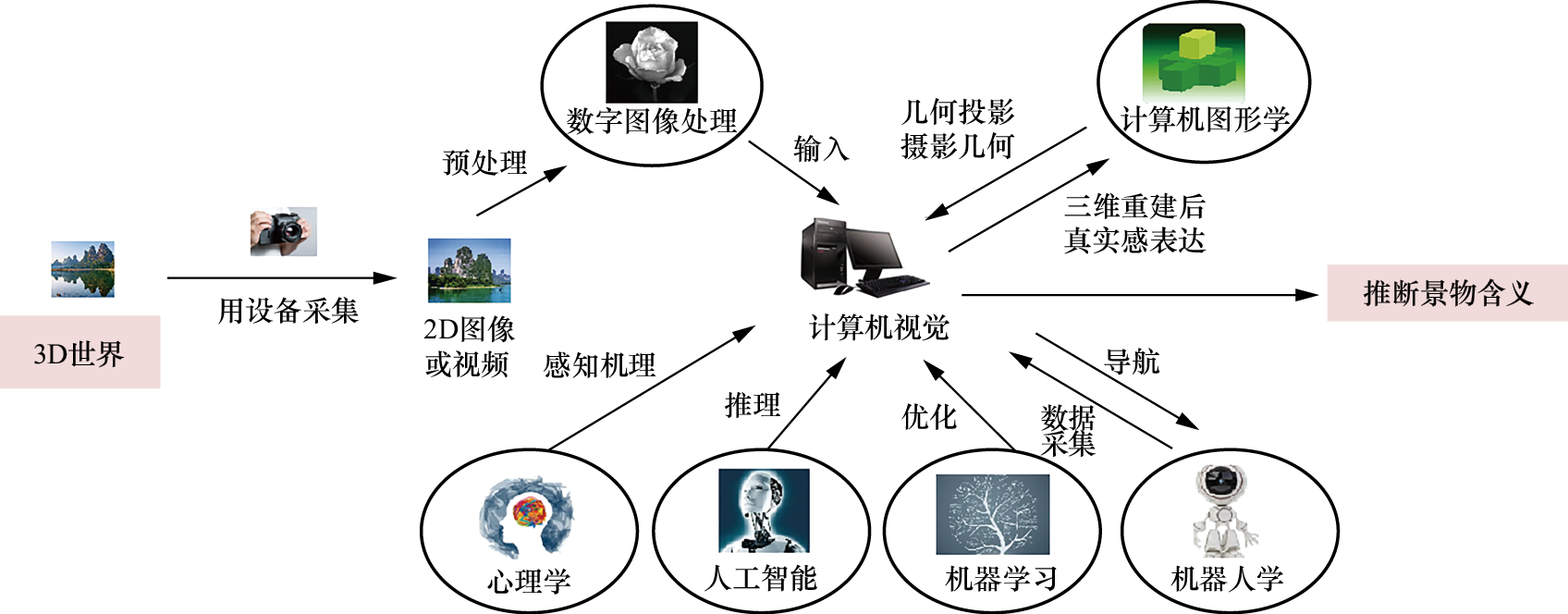
图1-3揭示了计算机视觉与其他学科之间的具体关系。
图1-3 计算机视觉与其他学科之间的具体关系
1)计算机视觉与数字图像处理之间的关系。计算机视觉算法研究的第一阶段就是图像的预处理。数字图像预处理主要包括两个方面的问题:图像采集过程常受到环境影响或设备干扰,采集得到的数字图像经常出现暗光、多噪声等现象,需要对图像进行去噪声、图像增强、图像复原等预处理,以增强图像,改善图像质量。此外,随着人工智能及深度学习技术的发展,在基于深度学习的计算机视觉算法研究中,需要建立数据集,因此要对采集的大量图像及视频数据进行预处理,包括去噪、增强处理,以及对数字图像进行镜像、平移、旋转和剪切等。可见,计算机视觉与数字图像处理之间有着密切的联系,数字图像处理是采集数据之后的第一步预处理过程。经过数字图像处理后,高质量的图像被输入计算机视觉算法中,如果缺少数字图像处理技术的辅助,计算机视觉算法将难以实现对客观世界的准确理解。
2)计算机视觉与机器学习之间的关系。计算机视觉算法致力于挖掘三维世界的信息,需要依赖复杂的视觉成像模型和感知原理。在视觉问题的研究中,为了获得优化的结果,机器学习算法常被用作优化工具。机器学习算法的目标是从有限的观测数据中学习、抽取或挖掘出一般性规律。因此,在计算机视觉研究中,机器学习的优化框架是不可或缺的支撑;同时,机器学习的模型优化过程也是计算机视觉获得稳定解的保障。
3)计算机视觉与人工智能之间的关系。计算机视觉技术和人工智能技术是两个相互交叉的学科。计算机视觉算法在认识世界的同时,需要人工智能提供高效的推理规则和优化过程。目前,人工智能借助深度神经网络推理机制,在计算机视觉领域广泛应用。计算机视觉能否在实践中充分发挥作用,人工智能技术是关键。
4)计算机视觉与机器人学之间的关系。机器人是实体设备,在物理世界可以运动。机器人经常使用多个相机,这样可以扩展机器人的视野,赋予机器人强大的空间感知能力。这部分相当于计算机视觉系统的数据采集部分,采集的数据形式是图像序列,机器人内部的计算机视觉算法作为导航及交互的指挥中心,对采集的实时数据进行感知、分析,然后将分析得到的结果作为机器人行为决策的依据。例如,机器人依靠激光雷达的反馈采样,经过分析,以便实现避障、导航。因此,机器人可以说是计算机视觉的工作和执行部件,机器人通过计算机视觉技术感知周围环境,以便得到控制动作的依据。计算机视觉可以在机器人控制中发挥关键作用,它是机器人的“指挥中心”。如图1-4所示,扫地机器人对目标进行快速定位。
图1-4 扫地机器人
5)计算机视觉与计算机图形学之间的关系。计算机图形学和计算机视觉是两个相互作用的领域。例如,在计算机视觉领域,当使用多视图成像技术恢复摄像机的成像模型时,需要将物体在三维空间中的坐标转换到摄像机坐标系中,这一转换过程依赖于计算机图形学中的3D坐标变换算法,然后才能使用小孔成像模型将这些坐标投影到图像平面上,完成成像过程。此外,计算机视觉在重建结果时,为了增强真实感,需要计算机图形学的技术支持。
6)计算机视觉与心理学之间的关系。在心理学中,感知是指人依靠意识对内外部环境信息的觉察,产生对客观世界的感觉、注意和知觉,它是人们获取知识的关键途径。计算机视觉的研究则需要模拟这种生物感知过程,借鉴心理学中关于感知与认知的理论,对三维世界进行理解。例如,计算机视觉研究中会利用心理学的感知机制,模拟人类的注意力机制,解决特定视觉理解问题。总的来说,如果缺乏心理学的支撑,计算机视觉的研究难以实现深层次突破。
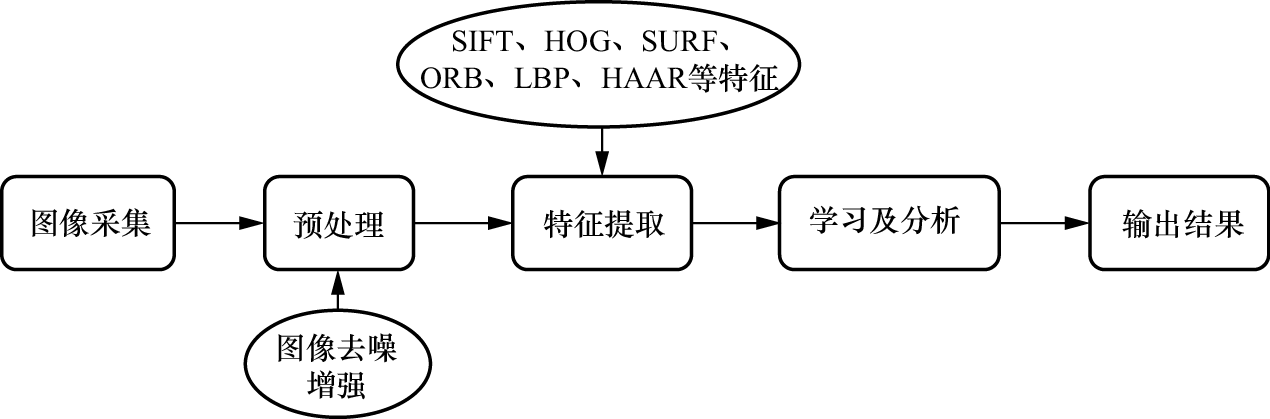
1.1.4 计算机视觉算法流程 在计算机视觉技术的发展过程中,虽然传统算法和深度学习算法在研究机理上有所不同,但它们的处理流程大致相同,主要包括图像或视频采集、预处理、获取特征和学习及分析四个部分,如图1-5所示。
图1-5 计算机视觉算法流程
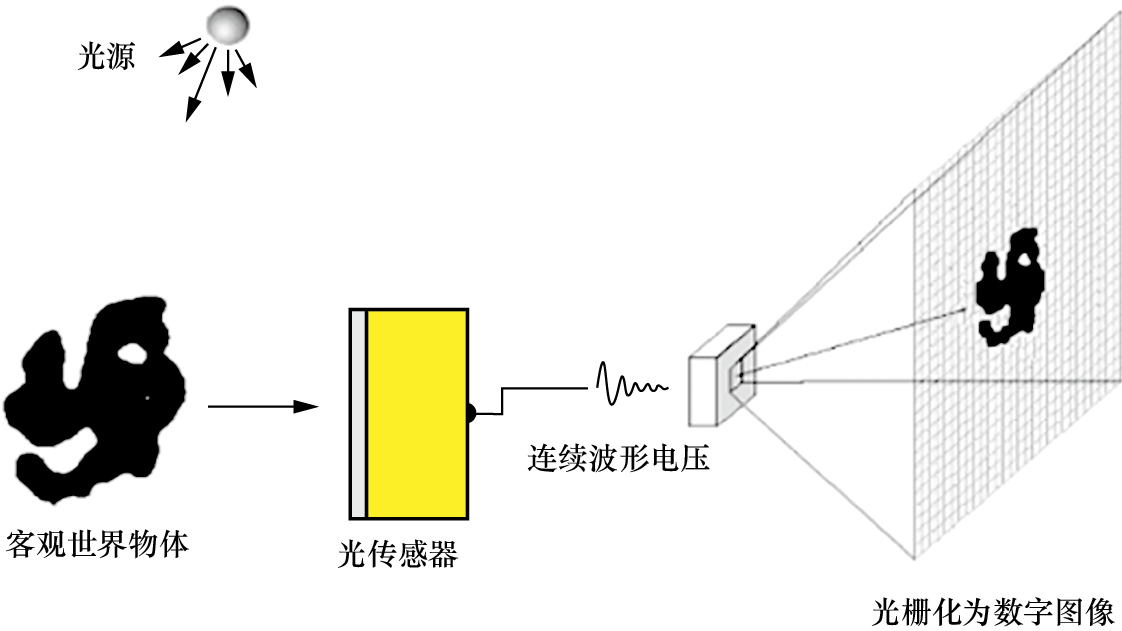
1. 图像或视频采集阶段 为了获取图像,环境中的光照必须照射到物体表面,形成明暗不同的反射或透射光能量分布。图像采集设备捕捉这些能量分布,并通过光传感器将光能量转换为电信号。传统的工业控制中多采用光导摄像管摄像机,而近年来,电荷耦合器件(Charge-Coupled Device,CCD)因体积小、重量轻、分辨率和灵敏度高、价格低廉等优点而迅速发展,并广泛应用于图像处理和机器视觉系统。无论是摄像头、CCD数码相机还是扫描仪,图像传感器都是核心部件,负责将光能量图转换为电信号。
在采集物体表面的连续能量后,首先得到的是连续波形电压。然而,计算机只能处理离散化的数字信息,显示器只能显示离散的光栅数据。因此,为了在计算机内存储、处理和显示图像,需要经过光传感器采样和光栅化处理,将连续波形电压转换为数字图像,如图1-6所示。
图1-6 数字图像获取过程
2. 预处理阶段 如图1-7所示,在计算机视觉传统算法中,为了提高采样图像的质量,需要进行去噪、对比度拉伸、图像复原等预处理步骤,目的是增强图像中的有用信息,改善图像质量。
图1-7 计算机视觉传统算法的流程
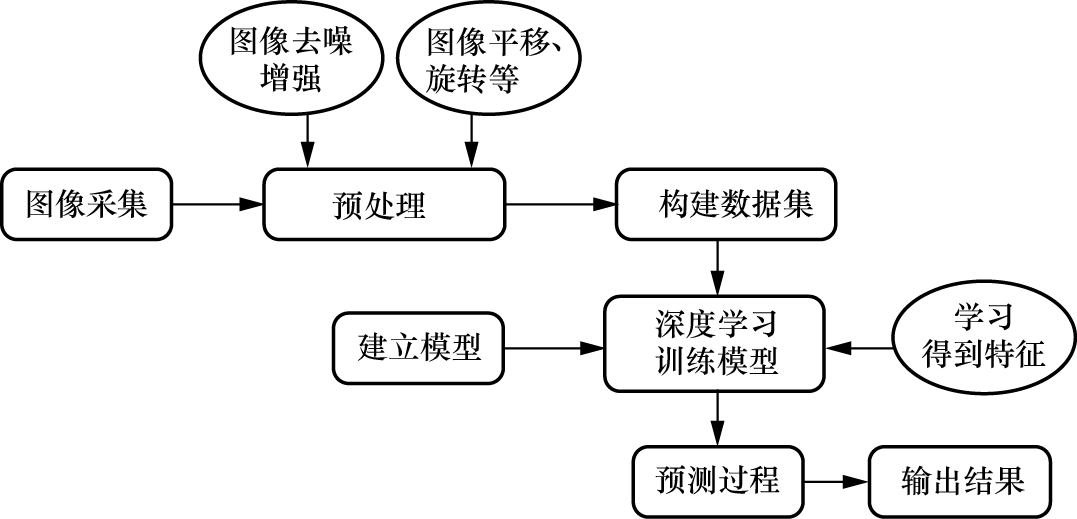
如图1-8所示,在深度学习算法研究中,还需要对采集的大量图像和视频数据进行预处理,如进行平移、旋转和剪切等,以增强模型的泛化能力。
3. 获取特征阶段 在计算机视觉传统算法中,为了获得图像的特征,人们利用定义的各种特征提取算法,手动提取图像中的特征,常见的特征提取算法有尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)、方向梯度直方图(Histogram of Oriented Gradient,HOG)、加速稳健特征(Speeded Up Robust Feature,SURF)、ORB(Oriented FAST and Rotated BRIEF)、局部二值模式(Local Binary Pattern,LBP)、HAAR等。
图1-8 计算机视觉深度学习算法的流程
与传统算法不同,深度学习算法中的特征提取是通过神经网络自动学习实现的。例如,CNN能够通过多层结构学习到图像的多层特征,从简单的边缘和纹理信息到复杂的模式和对象部分,无须人工干预,这使得深度学习算法在计算机视觉任务中表现出色,尤其是在图像分类、目标检测和语义分割等领域。
4. 学习及分析阶段 在计算机视觉早期发展阶段,为了获得满意的视觉分析结果,研究者主要依靠人工设计和优化算法来解决问题。随着时间的推移,他们开始更多地采用机器学习的优化模型。机器学习的典型任务包括分类、回归和聚类等,其中分类和回归属于监督学习范畴。分类任务就是根据数据的特征或属性来确定样本的类别。
近年来,深度卷积神经网络(Deep Convolutional Neural Network,DCNN)的强大功能极大地推动了计算机视觉技术的进步。DCNN能够提取多尺度空间特征,并具有良好的特征融合能力,这使得许多具有挑战性的计算机视觉问题取得了重大突破。DCNN凭借局部连接、权值共享和多层特征融合学习,在图像识别、目标检测、语义分割等任务中表现出色,同时也为计算机视觉算法质量的提高奠定了基础。
1.2 数字图像基础1.2.1 数字图像基本概念 人类获取三维空间世界信息的方式主要包括通过视觉感知客观环境,或利用采集设备对客观环境进行能量采样以获得数据信息。摄像头、数码相机及扫描仪等是典型的图像采集设备。
由于计算机仅能处理离散化数据,因此,采集得到的输出电压(如图1-6所示)必须经过采样处理以得到离散的数字信息。采样可以沿垂直和水平方向进行,如图1-9所示。采样后形成矩形阵列的像元点阵,每个采样点被称为像素,将其量化后形成每个像素的离散化能量强度。对于整幅图像,通过直接进行二维图像的点阵采样,即可获得二维图像的像素阵列,如图1-9c所示。
图1-9 图像采样示意图
图像采样方法主要包括均匀采样和非均匀采样两种。均匀采样又分为等行间距采样和等列间距采样。具体来说,图1-9a展示了等行间距采样,而图1-9b展示了等列间距采样。另外,图1-9c和图1-10a分别展示了同时采用等行间距和等列间距的采样方式。非均匀采样根据图像内容的特性来调整采样密度,在颜色变化剧烈和细节丰富的区域采用较高的采样密度;而在颜色变化平缓、细节较少的区域,如平缓区或背景区,则采用较低的采样密度。自适应采样就是一种典型的非均匀采样方法,如图1-10b所示。
图1-10 图像均匀采样和非均匀采样
如前所述,数字图像是通过采集设备对现实世界中的三维实体(借助于环境光照能量)进行数据捕捉,然后通过采样和量化处理得到的离散数据表示。数字图像可以用一个二元组<P , G >来表示,其中P 代表像素坐标的集合,G 代表像素的颜色集合或灰度集合。<P , G >定义从像素坐标集合P 到像素颜色或灰度集合G 的映射关系。
其中
图1-11 灰度图像和彩色图像实例
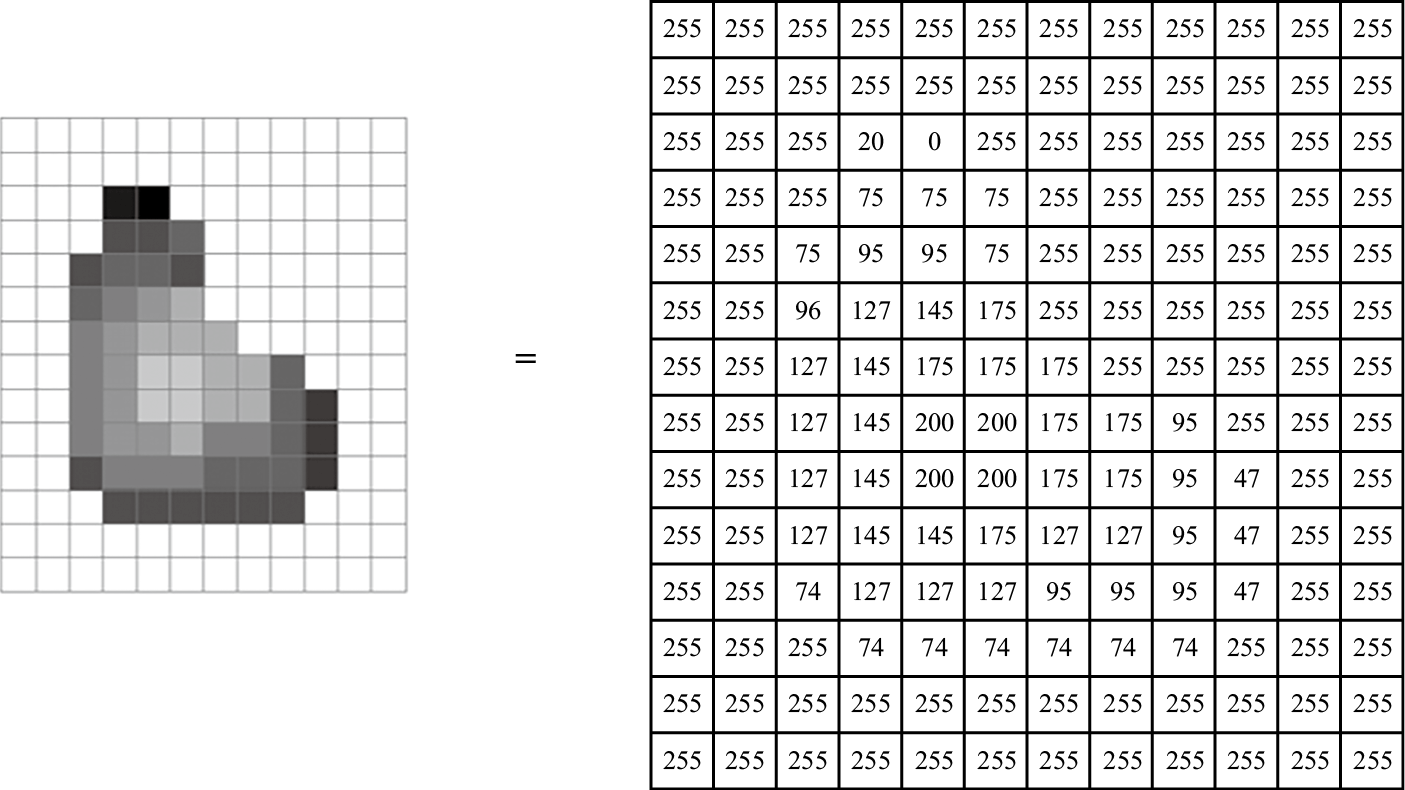
如图1-12所示,图1-12a展示了像素阵列形式,图1-12b展示了灰度值,图1-12c则提供了带有坐标实例的灰度图像,该图像的水平宽度为511,垂直高度为479。图中特别标注了第0行第0列、第58行第278列和第478行第510列的像素位置,其中(510, 478)处的像素灰度值为75。灰度图像通常用矩阵来表示灰度值阵列,如图1-13所示。图1-14进一步展示了一个具有256个强度等级的灰度图像实例,其中图1-14a是完整的灰度图像,图1-14b是图像的局部样例,图1-14c则是该局部样例的灰度值阵列,每个像素对应一个0到255之间的灰度值。
图1-12 图像及其像素示意图
图1-13 灰度图像及阵列表示实例
图1-14 灰度图像的实例
图1-15给出了一个RGB色彩空间的彩色图像实例。每个像素由R、G和B三个通道分量组成,每个分量占一字节的内存,像素的颜色由三个分量确定。
图1-15 RGB彩色图像实例
(1)设备坐标系与图像坐标系
在实际应用中,根据不同的需求,图像可以使用多种坐标系来表示。常见的坐标系包括设备坐标系和图像坐标系。
设备坐标系,如图1-12a所示,是将计算机屏幕的左上角设为坐标原点,以像素为单位进行度量。在这个坐标系中,水平向右的方向定义为x 轴正方向,垂直向下的方向定义为y 轴正方向。
图像坐标系是计算机视觉领域常用的另一种坐标系,其原点位于图像的中心。在这个坐标系中,同样地,水平向右的方向定义为x 轴正方向,垂直向下的方向定义为y 轴正方向,如图1-16所示。这种坐标系便于进行图像处理和视觉分析。
(2)二值图像实例
二值图像是一种特殊的灰度图像,它只有两个强度等级,通常表示为0和1。在二值图像中,每个像素被标记为0或1,其中0通常用来表示背景,而1用来表示前景。图1-17展示了一个二值图像的实例,从该图像中可以观察到,每个像素要么是0,要么是1。
图1-16 图像坐标系示例图
图1-17 二值图像的实例
(3)像素邻域
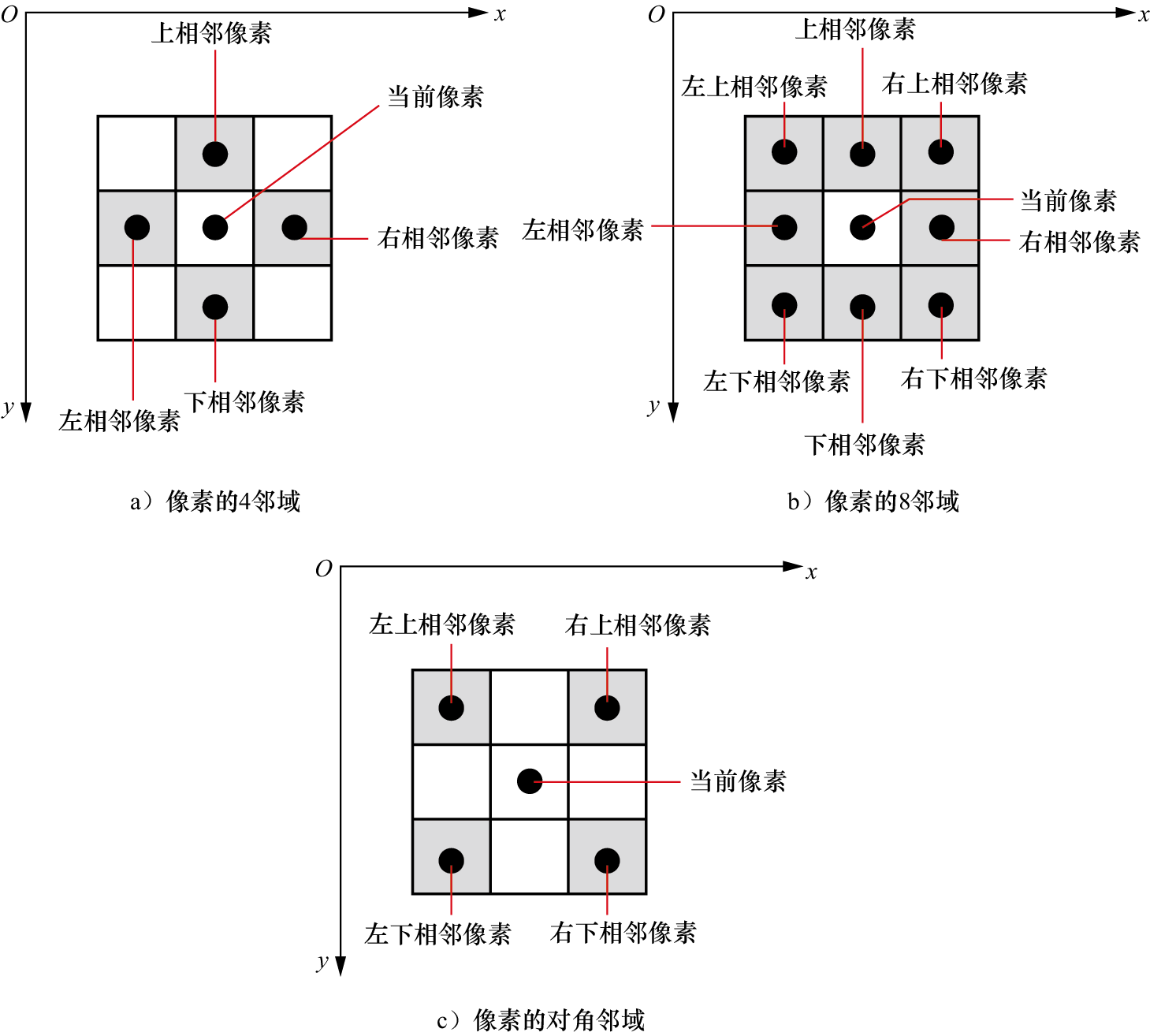
在计算机视觉研究中,像素邻域是一个重要的概念,它指的是某个中心像素周围的一组像素。不同邻域的选择,对计算机视觉算法的结果影响较大。常见的邻域有4邻域、8邻域、对角邻域等。图1-18中给出了几种邻域的示意图。
图1-18 不同像素邻域类型
1.2.2 数字图像质量影响因素 影响图像质量的因素较多,除了摄像机性能因素,还有空间分辨率、强度等级分辨率、对比度和清晰度等。
1. 空间分辨率 空间分辨率是指图像中可以辨认细微结构的最小几何尺度,常说的分辨率就是指空间分辨率。图像的空间分辨率通常用像素描述,如果水平方向上有
图1-19给出了具有不同空间分辨率的数字图像实例。在该实例中,可以明显地看出,图像的空间分辨率越高,图像越清晰,表明图像的质量越高;当图像分辨率降低时,图像质量就会下降;如分辨率缩小为原来的1/16时,如图1-19e所示,图像模糊不清。
图1-19 具有不同空间分辨率的数字图像实例
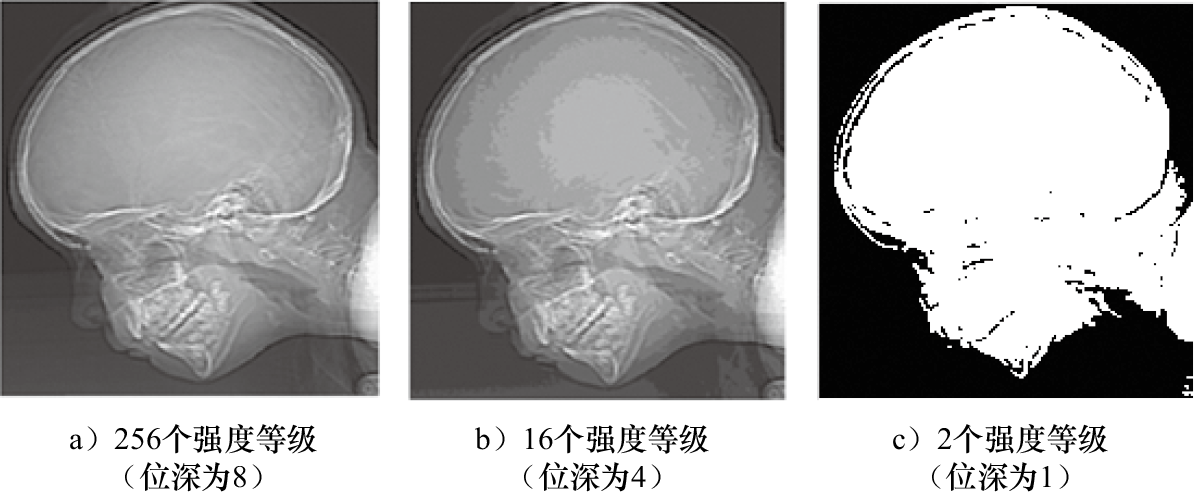
2. 强度等级分辨率 强度等级分辨率也称为细节层次,通常用位深来表示。位深又称为位分辨率,指的是一个像素的灰度值所占用的二进制位数。例如一个具有256个强度等级的图像,其位深为8,我们称之为8-bit图像;而一个只有2个强度等级的图像,其位深为1,我们称之为1-bit图像。图像的强度等级越高,图像位深也就越大,从而图像能够描述的细节也更加精细。图1-20展示了具有不同强度等级分辨率的图像实例。通过观察这些图像,我们可以发现,强度等级越高,比如256个强度等级的图像(位深为8),其图像细节展现得最为清晰;当强度等级为16(位深为4)时,图像的细节仍然较为可观;而强度等级为2(位深为1)时,图像的细节表现则相对较差。
图1-20 具有不同强度等级分辨率的图像实例
3. 对比度 图像的对比度通常通过图像中所有像素的最大强度与最小强度的比值来衡量。这个比值越大,图像展现的渐变层次越多,从而能够表现出更丰富的细节。高对比度的图像通常具有较高的清晰度,能够清晰地展现灰度层次。相反,如果图像的对比度较低,则图像会显得模糊,细节难以辨识。例如,在图1-21的图像实例中,图1-21a具有较高的对比度,因此能够清晰地呈现细节;而图1-21b的对比度较低,导致图像看起来模糊不清。
图1-21 不同对比度的图像实例
4. 清晰度 清晰度是衡量图像细节和边缘锐利程度的指标。图像清晰度高,细节内容能够被清楚地分辨,边缘锐利程度会非常明显。相反,清晰度低的图像会显得模糊,细节难以辨认。图像的清晰度受亮度和饱和度的影响:亮度表示颜色的相对明暗程度,通常以百分比表示,增加亮度可以提高图像的清晰度;而饱和度则是指色彩的纯度,也以百分比来度量,饱和度高的图像看起来更加清晰,饱和度低则图像显得模糊。图1-22给出了不同亮度及饱和度的图像实例。从图1-22a和图1-22b的对比中可以明显看出,增加亮度及饱和度,图像的清晰程度明显提高。
图1-22 不同亮度及饱和度的图像实例
1.2.3 数字图像基本运算 在计算机视觉算法研究中,常需要对图像进行运算、缩放及空域变换等操作,具体包括代数运算、逻辑运算、几何运算、图像缩放及图像变形。
1. 代数运算 数字图像的代数运算涉及对两幅图像的对应像素进行算术操作。这些运算的本质是对两幅图像上相同位置的像素进行加、减、乘、除等基本运算,这些基本运算可以单独使用,也可以组合起来形成更复杂的复合运算。
图像代数运算的基本形式如下:
其中
图像的代数运算在实际应用中具有重要价值,例如加运算可用于消除图像的随机噪声,还能通过叠加不同图像合成新的视觉效果,如构建光照变化的2D图像或合成特效;减运算则能实现运动检测,通过从当前帧减去静止背景帧来分离运动目标,这在视频监控等领域尤为有用;乘运算则用于抑制图像的特定区域,通过设置掩模值(保留区域为1,其余为0)并与原始图像相乘,可以突出前景运动目标,从而在图像处理和计算机视觉任务中发挥关键作用。
2. 逻辑运算 逻辑运算在图像处理中扮演着重要角色,它通过对两幅图像的对应像素进行逻辑操作来实现。这些操作包括与(AND)、或(OR)和补(NOT)运算。对于灰度或彩色图像,在进行逻辑运算之前,通常需要先进行二值化处理,将图像转换为仅包含前景和背景两部分的形式。在逻辑运算中,与和或运算属于双目运算,是对两幅图像的二值化结果进行逻辑比较;补运算是单目运算,它用于对单幅图像的二值化输入进行取反操作。这些逻辑运算可以组合使用,形成复合逻辑运算,以实现更复杂的图像处理效果。在逻辑运算过程中,像素的位置保持不变,运算仅涉及对应像素的二值化信息。逻辑运算在图像增强处理等领域具有实用价值,例如,补运算可以增强图像的对比度,使得图像更易于分析和理解,从而对后续视觉任务提供辅助。
3. 几何运算 图像的几何运算包括图像的平移、旋转、放大、缩小和镜像,它可以改变图像的空间位置关系,但不改变图像的色彩特性。在基于深度学习的计算机视觉算法中,图像几何运算经常用于构建数据集。图1-23给出了图像几何运算的实例。
图1-23 图像的几何运算实例
4. 图像缩放 图像缩放是对图像进行放大或缩小的操作,其中缩小可能使图像看起来更清晰,放大则可能导致图像质量下降,因此需要通过插值算法来改善。缩放分为等比缩放和非等比缩放,等比缩放保持图像原始宽高比,非等比缩放则会改变图像原始宽高比。在传统数字图像处理中,常采用最近邻插值法和双线性插值法等技术来重新采样和处理图像的灰度或颜色信息。尽管近年来基于深度学习的图像超分辨率技术取得了新进展,提供了高质量的图像超分辨率方法,但传统数字图像处理算法因简单实用,在计算机视觉研究的数据集构建中仍发挥着重要作用。
5. 图像变形 图像的变形技术具有一定的实用价值,广泛应用于动画生成、图像融合、全景图像的拼合等。目前出现了基于传统算法的变形技术和基于深度学习的智能变形策略。常见的图像变形有刚体变换、仿射变换和透视变换三类,实例如图1-24所示。
图1-24 常见图像变形
图像变形常通过仿射变换实现,为了获取两幅图像的仿射变换映射关系,一般先获取两幅图像之间的对应点,再基于对应点建立2D图像的仿射变换矩阵。
1.2.4 数字图像的空域处理 数字图像的空域处理主要是在图像的二维空间内进行。其中,点运算是一种基本的处理方法,它针对图像中每个像素的灰度或色彩进行运算,目的是调整像素的灰度值或改变图像的对比度。对灰度图像而言,点运算的核心在于对每个像素点的灰度值进行调整,以此来增强图像的显示效果。
1. 线性点运算和非线性点运算 根据运算的性质可以将图像的点运算分为线性点运算和非线性点运算两种。
线性点运算的灰度变换函数可以采用线性方程描述,即:
其中,r 为输入的像素灰度值,s 为输出的像素变换后的灰度值。
非线性点运算是指对像素的灰度值采用非线性变换处理方法,典型方法包括对数变换和幂变换。
对数变换的一般表达式为:
其中k 为参数,r 为输入的像素灰度值。对数变换的作用是对低灰度区进行扩展,对高灰度区进行压缩。
幂变换的一般形式为:
其中,r 为输入的像素灰度值。
2. 直方图 灰度直方图是一种统计方法,常用于数字图像的统计分析,即统计图像中各灰度级出现的频数,绘制出各个灰度级所对应的统计数目。其中,横坐标表示灰度级,纵坐标表示频数。灰度直方图可表示为:
其中,
在实际应用中,常使用灰度直方图的归一化形式:
从图1-25的对比中可以看出,图像经过直方图均衡化处理后,清晰度有了显著提升。对比两个直方图可以发现,均衡化处理后直方图的分布被拉伸,统计直方图变得更加均匀。
图1-25 直方图均衡化的结果
1.2.5 图像滤波处理 数字图像处理一般分为空域处理和频域处理。空域处理利用每个像素的邻域信息,通过空域滤波器对图像进行操作,生成滤波后的图像。空域平滑与锐化是常见的滤波处理:空域平滑的目的是去除图像的噪声成分,有均值滤波法、中值滤波法和超限像素平滑法等方法;空域锐化的目的是加强图像轮廓,使图像看起来比较清晰。空域锐化滤波器通常基于空域差分原理,求取图像中突出的细节信息来强化边缘成分,去除模糊成分,实现锐化效果。
频域处理是将图像变换到频域中,然后采用频域处理策略对图像进行处理。频域处理的首要步骤就是将图像从空域(时域)变换到频域,然后利用频域滤波器,根据图像频谱进行不同的滤波处理,从而达到图像平滑或锐化的目的。由于图像中灰度均匀的平坦区域对应傅里叶变换后频谱的低频成分,灰度变化频繁的边缘及细节对应傅里叶变换后频谱的高频成分,合理构造滤波器以将图像变换域中的高频或低频成分过滤掉,便可以得到图像的平滑或锐化结果。
滤波器种类很多,按其特性的不同,可以分为低通滤波器、高通滤波器、带通滤波器和带阻滤波器等。
1)低通滤波器。低通滤波器是容许低频信号通过,但是减弱(或减少)高频信号通过的滤波器。这种滤波器通过设定一个特定的频率点,即截止频率,来决定信号是否能够通过。当信号的频率高于这个截止频率时,将被滤波器抑制。常见的低通滤波器有理想的低通滤波器、巴特沃斯低通滤波器、高斯低通滤波器和梯形低通滤波器等。
2)高通滤波器。高通滤波器是容许高频信号通过,但是减弱(或减少)低频信号通过的滤波器。当信号频率低于截止频率时,将被阻止。常见的高通滤波器有理想的高通滤波器、巴特沃斯高通滤波器、高斯高通滤波器和梯形高通滤波器等。
3)带通滤波器。带通滤波器是指能通过某一频率范围内的频率信号,但是将其他范围的频率分量衰减到极低水平的滤波器。带通滤波器用于带通滤波,它与带阻滤波器的概念相反。
4)带阻滤波器。带阻滤波器是指能通过大多数频率信号,但是将某些范围的频率分量衰减到极低水平的滤波器。与带通滤波器的概念相反,通常阻带范围较小。
1.3 机器学习与人工智能技术人工智能技术迅猛发展,已经广泛应用于工业、农业、国防等领域,本节主要介绍与计算机视觉相关的机器学习与人工智能技术。
1.3.1 人工智能技术的发展 近年来,深度学习技术迅猛发展,并催生了众多研究成果。这项技术已广泛应用于多个领域,包括车牌识别、人脸识别、运动目标跟踪、指纹识别等。人工智能(Artificial Intelligence,AI)旨在研究如何赋予机器类似人类的智能,这是科学家们经过数十年科学探索始终追求的目标。
人工智能概念的起源可追溯至“图灵测试”的创新思想。1950年,阿兰·图灵在“Computing Machinery and Intelligence”中提出“图灵测试”方法,即辨别机器是否具备“智能”,为人工智能技术的产生及发展奠定了基础,并且也促使模式识别、计算机视觉和自然语言处理等相关技术得到迅速发展。随着智能技术的不断进步,1956年在达特茅斯会议上针对“如何用机器模拟人的智能”这一议题,约翰·麦卡锡首次提出了“人工智能”这一概念,标志着人工智能学科的正式确立。人工智能技术经过了初期推理理论发展阶段、专家系统推理阶段、机器学习的理论发展阶段,以及深度学习的快速发展阶段。
1)初期推理理论发展阶段。在人工智能概念提出后的早期,研究者深入探讨了推理理论,并取得了一系列令人瞩目的研究成果。1957年,罗森布拉特提出人工神经网络的早期模型,并提出感知器概念。1960年,维德罗采用Delta学习规则对感知器进行训练,进而催生基于最小二乘法的线性分类器。这一时期还诞生了一些创新成果,如几何定理证明器、语言翻译器、跳棋程序等,掀起人工智能发展的第一个高潮。然而,随着研究的深入,人们逐渐意识到初期理论的推理规则过于简单。1969年,马文·明斯基在《感知器》一书中指出了人工神经网络的局限性。同时,初期研究的智能项目未能实现预期结果,人工智能研究领域遭遇瓶颈,这导致人工智能的研究进入低谷。当时,面临的技术瓶颈主要包括计算机性能不足、问题的复杂性和数据量的严重不足。
2)专家系统推理阶段。在20世纪80年代,人工智能领域迎来了一个新的崛起时期,其中显著的发展是复杂系统推理技术的出现,其典型代表是知识库的建立和应用。1980年,卡内基梅隆大学研发了XCON专家系统,这个系统通过将知识库与推理机相结合,形成了一个具有完整专业知识和经验的计算机智能系统。同一时期,为了解决实际问题,一系列特定领域的专家推理系统相继开发。这些系统模拟人类专家的知识和经验,以解决特定领域的问题。专家系统的研发标志着人工智能从一般推理策略的研究转向了运用专门知识推理的实际应用,实现了重大的技术突破。这一阶段的发展催生了许多硬件和软件公司,如Symbolics、Lisp Machines和IntelliCorp、Aion等。专家系统在医疗、地质等领域的成功应用,推动了人工智能技术的快速发展,也为其后续演进奠定了理论基础,使得知识库系统和知识工程成为80年代AI研究的热点方向。
3)机器学习的理论发展阶段。20世纪80年代中期,随着人工智能技术的发展,人们发现专家系统存在诸多问题,如应用领域狭窄、缺乏常识性知识、知识获取困难、推理方法单一等,这些问题使得专家系统难以实现对复杂智能行为的动态描述。为此,研究者开始转向从实际数据出发,试图挖掘本质的、内在的规律,以更好地满足实际应用需求。在80年代末期,机器学习的研究路线应运而生。并且,由于机器学习在多个领域取得了显著成效,因此成为当时的研究热点,推动了人工智能技术的实用化进程。随后,出现了诸如IBM公司的“国际象棋世界冠军”智能比赛系统及“智慧地球”概念等AI研究新成果,以及一系列典型理论成果。1982年,约翰·霍普菲尔德提出Hopfield网络,使用全新方式进行信息学习和处理。1986年,ID3决策树算法问世,它被应用于数据挖掘与分类。1990年,Schapire提出Boosting初步算法,Freund在后续研究中进一步发展了该算法。1995年,Freund和Schapire提出Boosting的改进策略,即AdaBoost(Adaptive Boosting)算法,同年Vapnik和Cortes提出了支持向量机(Support Vector Machine,SVM)策略。2001年,Breiman提出随机森林,缓解了机器学习中的过拟合问题。
4)深度学习的快速发展阶段。2006年,杰弗里·辛顿在深度学习领域取得了重大突破,人工智能迎来了新一轮研究热潮,催生了如谷歌、商汤科技等全球AI行业的领军企业。AI技术如今已广泛应用于图像分类、语音识别、知识问答、人机对弈、无人驾驶等众多场景,正处于智能化技术飞速迭代的关键时期。
1.3.2 机器学习概念及常用算法 1. 机器学习概念 机器学习即通过计算机算法从数据中学习规律,并用这些规律对新的数据进行预测。具体来说,机器学习可以定义为:对于给定样本(x i y i i ≤N ,N 为自然数,建立计算模型,自动寻找一个决策函数f (·) 来建立x 和y 之间的关系。
其中,
实际上,机器学习可以看作根据给定样本进行模型构建及参数优化的过程。机器学习的主要处理框架包含训练过程、预测过程及测试过程三部分。
1)训练过程也被称为模型训练,是指建立学习模型并通过学习特征来确定其参数的过程。在图1-26中,上半部分描述了模型的建立及训练的过程,输入的是一些观察数据,在模型拓扑结构确定的情况下,得到的结果是具有特定拓扑结构的模型参数。
2)预测过程是模型的应用阶段。在这个过程中,模型利用其确定的拓扑结构及训练获得的参数,通过网络计算得出输入实例数据的预测结果。这一过程被称为预测过程。图1-26的下半部分展示了模型的应用过程。
图1-26 机器学习框架
3)测试过程是机器学习训练过程中的一个关键环节,它涉及对所建立和训练的模型性能的评估和分析。在这一阶段,可能需要不断地调整模型,以确保其达到预期的性能水平。
通常,整个学习数据集可以分为三个部分:训练集、验证集和测试集。训练集用于模型的训练过程;验证集是从数据中划出的一个独立子集,它用于对模型性能进行初步评估;测试集则用于评估最终模型的泛化能力,它不用于调整参数或选择算法特征。验证集可以根据需要多次使用,以优化模型质量。在机器学习的实际应用中,往往需要进行以下几步,即先对输入的数据进行预处理,然后进行特征提取,再输入机器学习模型中进行学习、测试或者预测处理。
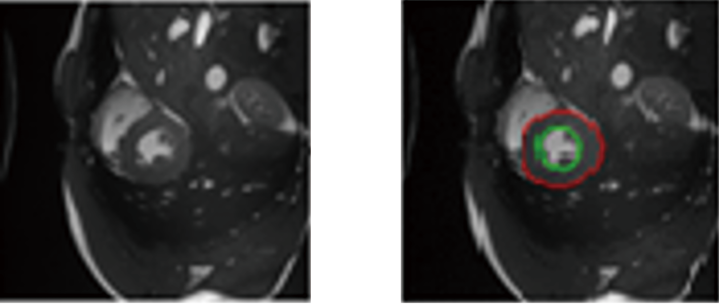
机器学习在解决实际问题方面应用广泛。例如,在语音识别系统中,输入一段语音信号后,机器学习模型能够通过分析该信号,输出相应的文本结果。在数字图像识别领域,机器学习模型能够学习并识别数字图像,输出图像对应的数字。而在医学影像病灶识别系统中,输入医学影像后,机器学习模型经分析可自动识别并分割病灶区域,如图1-27所示,从而为医生提供辅助诊断支持。
图1-27 机器学习系统
机器学习算法从总体类别看,可分为监督学习和非监督学习。监督学习使用一组带有已知学习目标的样本,即标注数据,来训练模型。在这个过程中,通过调整模型参数,使得模型的输出与预期目标尽可能一致。样本学习目标作为调整参数的指导,目的是让模型的输出结果与这些目标相匹配。一旦模型的输出与样本学习目标一致,参数调整过程就可以停止。样本学习目标通常通过人工标注获得,例如医学CT影像中肝肿瘤区域的人工标注可以作为训练模型的依据。
非监督学习则不同,它处理的是没有标注的数据,即输入数据没有附带学习目标。在这种情况下,模型需要根据样本之间的关系进行学习。例如,在分类问题中,非监督学习可以通过聚类方法对样本进行分组,尽量使同一类别内的样本差异最小化,而不同类别之间的差异最大化,从而实现分类的目的。非监督学习的目标不是预先给定的,而是在给定条件和特征后,让算法自行学习。非监督学习方法包括概率密度函数估计的直接方法和基于样本间相似性度量的聚类方法。
监督学习和非监督学习在本质上存在差异。监督学习要求训练样本集必须由带标签的样本组成,学习的目标是达到预先标注的标准。非监督学习则不需要标注的数据,它只有要分析的数据集本身,没有预先设定的标签。在监督学习中,一旦学到预期的规律,就可以停止学习,而不需要严格遵循数据标注的要求。
2. 机器学习算法步骤 传统机器学习与深度学习的算法步骤有所不同。传统机器学习算法的主要步骤包括数据准备、数据预处理、特征提取、机器学习算法的选择、模型参数学习过程、模型使用过程。
(1)数据准备
在数据准备阶段,收集的数据可以是数值型,如股票价格、房屋销售量,也可以是图像和视频等多媒体数据。这些数据可以通过图像采集设备采集或从网络公开数据源获取。
(2)数据预处理
这一阶段主要完成数据的预处理任务,具体包括以下步骤。首先处理数据中的缺失值,然后去除重复的数据记录。接着采用归一化或标准化方法,例如将数据范围从[min, max]映射到[0, 1],以此避免模型参数受到极值的影响。图像数据的预处理通常还要纳入图像增强、图像变换增强及图像尺度变换增强等措施。
(3)特征提取
在数值型数据处理中,特征提取可通过直接运算将数据转化为特征描述,或利用学习算法自动挖掘有效特征。在传统学习方法中需要人为设计准则来选取特征,而数字图像的特征提取涉及角点、边缘、区域和轮廓等多种对象。这些特征类型包括颜色、纹理和形状等,其中颜色特征描述颜色分布,纹理特征反映纹理的规律性,形状特征则涉及物体的几何形状,这些特征对于图像的识别和分析至关重要。
(4)机器学习算法的选择
在实际处理过程中,可根据问题的不同类别选择合适的学习模型。针对某一类问题,通常有多种不同的算法可供选择。从模型的假设空间角度来看,机器学习模型可分为线性模型和非线性模型两种。而从数据学习挖掘的算法模型角度来看,常见的机器学习模型及对应算法如下所示。
1)回归模型:统计学习的算法,根据对误差的衡量,探索变量之间的关系。常见的回归算法包括最小二乘法、逐步回归及多元自适应回归样条等。
2)基于实例的学习模型:用于对决策问题建模,常见的算法包括K最近邻法、学习向量量化算法及自组织映射算法。
3)决策树模型:根据数据的属性构建树状结构的决策模型,可解决分类和回归问题。常见的算法包括分类及回归树、随机森林、多元自适应回归样条等。
4)贝叶斯模型:基于贝叶斯定理的学习算法,用来解决分类和回归问题。常见算法包括朴素贝叶斯算法、平均单依赖估计和贝叶斯置信网络。
5)基于核的学习模型:数据先映射到高阶向量空间,然后在高维空间解决分类或者回归问题。常见算法包括支持向量机算法、径向基函数算法及线性判别分析法。
6)聚类模型:按照中心点或者分层的方式对输入数据按照最大共同点进行归类,试图找到数据的内在结构,常见的聚类算法包括K最近邻法及期望最大化算法。
7)降低维度模型:分析数据的内在结构,试图利用较少的信息来归纳或者解释数据并进行非监督学习。常见算法包括主成分分析、偏最小二乘回归算法及投影追踪算法等。
8)关联规则学习模型:通过寻找变量之间的关联规则来解释数据依赖关系。常见算法包括 Apriori算法等。
9)集成学习模型:将一些相对较弱的学习模型进行独立训练,然后把它们的结果整合起来进行整体预测。常见算法包括Boosting、AdaBoost、随机森林等。
10)人工神经网络模型:模拟生物神经网络的模型,用于解决分类和回归问题。该模型是机器学习的一个庞大分支,有多种算法,深度学习模型是其中一种,基于人工神经网络模型的算法有感知器神经网络、反向传递算法、Hopfield网络、学习向量量化算法等。
机器学习中的典型任务包括分类、回归及聚类。分类与回归属于监督学习范畴。在分类任务中,依据数据的特征或属性来判断样本的类别。例如在文本分类问题中,对输入的文本(如句子或词语)进行特征学习,判断其情感倾向是褒义还是贬义,这属于二分类问题。再比如在手写数字图像分类中,需要判断图像中显示的是哪个数字,如图1-28所示。由于可能的数字类别是从0到9的任意一个,这实际上是一个多分类问题,此例中具有10个类别。
图1-28 手写数字识别的分类问题实例图
常用的分类算法有决策树分类算法、朴素的贝叶斯分类算法、基于支持向量机的分类器、神经网络分类算法,K最近邻法、模糊分类法等。
回归任务研究的是因变量(目标)与自变量(预测器)之间的关系,是对数值型连续随机变量进行建模。对于数据样本,则按照某种模型进行拟合,以确定模型参数。例如,如果学习变量之间存在线性关系,则线性回归算法适用。常见的回归算法包括线性回归、逻辑回归、多项式回归、逐步回归、岭回归、套索回归及ElasticNet回归,其中线性回归、逻辑回归和多项式回归应用最广泛。线性回归的因变量是连续值,自变量可以是连续或离散的,变量间的依赖关系是线性关系。当变量学习的类型属于二元(真/假)分类问题时,使用逻辑回归对变量的所属类别的概率进行统计分析。多项式回归利用多项式方程对变量之间的关系进行拟合。
(5)模型参数学习过程
在机器学习中,主要涉及三个关键问题:学习模型的选择、学习准则及模型优化。关于学习模型的选择,前文已有详细说明,此处不再赘述。以下将重点阐述模型参数学习中的学习准则及模型优化等相关问题。
1)学习准则问题。机器学习的目的是从有限的观测数据中学习、抽取或挖掘具有普遍性的规律。在这个过程中,评价数据间规律的抽取质量至关重要。学习过程中需要按照特定的模型条件对数据间的关系进行约束,以确保挖掘出的规律更加符合数据本身的特性。总的来说,对于所有训练数据样本,利用机器学习算法优化模型e 达到极小。
为了度量学习模型的预测结果与真实结果之间的差异,在监督学习中,会基于数据标签,以网络预测误差最小化为约束条件。而在非监督学习中,确定机器学习准则通常不依赖标签信息,而是通过其他方式,例如最大化数据的一致性、最小化数据的重构误差或最大化数据的生成概率等。
实际上,为了评估学习过程中挖掘的规律是否符合实际情况,人们通常采用损失函数作为学习过程的约束。学习模型的质量常常通过期望风险来衡量,且通常采用基于损失函数最小化的经验风险来评估和约束模型的性能,其中常见损失函数的类型有0-1损失、链损失、互熵损失(也称为交叉熵损失)、平方损失、指数损失及绝对值损失等。从学习模型的性能角度来看,在经验风险最小化过程中常出现模型的过拟合与欠拟合现象。过拟合是指训练模型的质量在训练数据上表现良好,在未知数据上表现较差,即错误率很高。而欠拟合是指在训练数据和未知数据上表现都很差,即错误率都很高。
2)模型优化问题。在机器学习模型已经确定的情况下,寻找模型的最优参数是优化问题的关键。模型的性能不仅取决于其拓扑结构,还与模型中的参数设置密切相关,这些参数被称为超参数。超参数的选取是优化过程中需要考虑的一个重要方面,它们可以基于算法研究人员的经验进行设定,或者通过优化过程来寻找最优值。机器学习模型中参数的优化算法分为一阶优化算法和二阶优化算法。一阶优化算法通过利用参数的梯度值来最小化损失函数。二阶优化算法则基于二阶导数信息来最小化损失函数,由于二阶优化算法的计算成本较高,其在实际中并未得到广泛使用。
梯度下降法是常用的一阶优化算法,包括批量梯度下降法、随机梯度下降法和小批量梯度下降法。批量梯度下降法优化所有样本的平均损失函数,每次迭代计算量大,但梯度方向准确。随机梯度下降法优化单个样本的损失函数,计算速度快,但梯度估计波动大。小批量梯度下降法结合了两者的优点,每次迭代选取部分样本计算平均梯度,既高效又稳定。
(6)模型使用过程
在机器学习模型训练完成后,通常须评估模型性能,然后才能用于预测。
常用的模型评估方法有Hold-Out评估和交叉验证。Hold-Out评估需要将数据划分为训练集、验证集和测试集,分别用于模型训练、性能评估和预测能力测试。交叉验证则在数据有限时,通过轮流使用子集作为测试集来构建和评估模型。
回归模型评估常使用均方根误差、相对平方误差、平均绝对误差、相对绝对误差、决定系数和标准化残差图等指标。分类模型评估则常采用混淆矩阵。
1.3.3 机器学习与深度学习 从模型学习手段的角度来看,机器学习策略可以归为两大类:基于频率理论的学习策略和基于贝叶斯理论的学习策略。
1. 基于频率理论的学习策略 基于频率理论的学习策略是假设模型参数θ 是确定的、未知的,其关键问题是如何根据观察数据估计参数θ ,常用的方法就是极大似然估计:
基于频率理论的学习策略衍生出了基于统计学习的方法,该方法涵盖了多种策略,包括正则化、核方法、集成学习和层次化等。
在统计学习的核方法中,支持向量机(SVM)算法和径向基函数(RBF)算法是两个典型的实例。AdaBoost学习算法和随机森林算法则是集成学习策略在频率学习领域的应用。随着机器学习技术的不断进步,层次化神经网络的传统学习方法衍生了一系列深度学习模型,如多层感知器(Multilayer Perceptron,MLP)、自动编码器(AutoEncoder)、卷积神经网络(CNN)和循环神经网络(RNN)。随着学习和计算能力的提升,这些具有深层次结构的典型机器学习模型被统称为深度学习模型。
可以看出,深度学习中的自动编码器、卷积神经网络等都是由基于频率理论的机器学习模型发展而来的。如图1-29所示,这些模型支持更深的层次结构,并具有较强的特征学习能力。此外,在基于频率理论的统计学习中,例如在线性回归的学习过程中,均方差损失函数的定义就采用了极大似然估计的频率统计思想。
图1-29 基于频率理论的学习策略与深度学习模型之间的关系
2. 基于贝叶斯理论的学习策略 基于贝叶斯理论的学习策略是假设模型参数θ 是一个随机变量,并且服从概率分布θ ~p (θ )(称为先验概率),然后根据贝叶斯理论,将参数的先验概率、后验概率及似然规律相联系。
在基于贝叶斯理论的学习策略中,概率图模型是一种典型的贝叶斯学习模型,它主要包括有向图模型、无向图模型及有向和无向图混合模型。在有向图模型中,贝叶斯网络(Bayesian Network)是一个典型实例;在无向图模型中,马尔可夫网络(Markov Network)是核心代表;而在混合模型中,混合网络(Mixed Network)是典型实例。在概率图模型的学习过程中,通常不使用损失函数来控制学习过程,而是通过生成模型来确保学习模型的质量。
随着网络计算能力的提升,基于有向图模型,发展出了支持深度学习机制的模型。如图1-30所示,这些模型包括Sigmoid信念网络和生成对抗网络(GAN)等。在有向图模型的基础上,结合深度学习策略,发展出了深层玻尔兹曼机(Deep Boltzmann Machine)。在混合模型中,进一步融入深度学习机制,形成了深度信念网络(Deep Belief Network,DBN)。这些深化的生成模型,即深度生成模型(Deep Generative Model),在人工智能研究中扮演着重要的角色。
图1-30 基于贝叶斯理论的学习策略与深度学习模型之间的关系
1.3.4 深度学习技术的发展 深度学习作为机器学习的一个重要分支,近年来受到了国内外学者的广泛关注,它经历了多个发展阶段。
1. 深度学习的起源 1943年,沃伦·麦卡洛克和数学家沃尔特·皮茨合作提出了MP(McCulloch-Pitts)模型,并首次提出了构建了人工神经元的数学模型。这一模型被视为人工神经网络的起源,为后续神经网络模型的发展奠定了基础。1949年,加拿大心理学家唐纳德·赫布提出了无监督学习的赫布学习规则,建立了基于样本相似性进行分类的“网络模型”,为神经网络的学习算法打下了基础。
20世纪50年代末,基于MP模型和赫布学习规则,美国科学家罗森布拉特模拟人类学习过程,建立了由两层神经元(输入层和输出层)组成的感知器,并在1957年提出了线性模型的“感知器”。感知器能够实现数据的二分类,对神经网络的发展具有里程碑意义。然而,1969年著名AI先驱马文·明斯基和西蒙·派珀特合著的图书《感知器》指出了感知器的局限性,这导致在20世纪70年代人工神经网络技术的研究进入了低潮。在此后的十几年中,神经网络的研究几乎停滞不前。
2. 深度学习的人类记忆模拟阶段 1982年,物理学家约翰·霍普菲尔德为模拟人类联想记忆功能,提出了Hopfield神经网络。他设计了连续型和离散型两种类型的算法,分别应用于优化计算和联想记忆。Hopfield网络在理论上具有重要意义,尽管它存在容易陷入局部最小值等缺陷。
随后,在1986年,杰弗里·辛顿等人在论文中阐述了一种多层感知器的反向传播(Back Propagation,BP)算法。BP算法能够有效解决非线性分类问题,使得人工神经网络的学习能力再次引起广泛的关注。然而,20世纪80年代计算机硬件性能有限,计算能力不足以支持大规模神经网络的研究,BP算法在应用过程中出现了“梯度消失”问题。
与此同时,90年代中期,一些浅层机器学习算法(如支持向量机)相继出现,并且这些浅层模型在分类任务上取得了较好的效果。这些发展在一定程度上取代了人工神经网络在学术和工业界的地位,使得人工神经网络的发展再次进入低潮时期。
3. 深度学习的复苏与爆发 2006年,杰弗里·辛顿和他的学生鲁斯兰·萨拉赫丁诺夫在《科学》上发表文章,正式提出了深度学习的概念,并给出了“梯度消失”问题的解决方案。他们的策略包括在无监督学习中进行逐层预训练,然后使用有监督的反向传播算法进行微调。这一创新工作在学术界引起巨大反响,吸引了众多世界知名高校研究团队的关注,并促使他们跟踪深度学习的最新前沿技术。这股热潮迅速蔓延到工业界,推动人工智能技术以惊人的速度发展。
2016年,谷歌公司开发的基于深度学习的人工智能程序AlphaGo在围棋比赛中以4 : 1的比分战胜了国际顶尖围棋高手李世石。这一胜利标志着在围棋领域,基于深度学习技术的智能已经超越了人类的能力。
近年来,深度学习的相关算法在医疗、金融、艺术、无人驾驶等多个领域取得了显著的应用成果。人们持续关注深度学习和人工智能的最新热点和动态,深度学习已经成为推动人工智能发展的关键力量。
1.3.5 神经元与人工神经网络 在神经网络的研究历程中,科学家们最初的目标是建立能够模仿人脑神经系统的数学模型。这类模型由人工神经元构成,简称神经网络。人脑中的神经元是负责信息传递的特殊细胞,人脑神经系统大约包含800亿到1000亿个基本神经元,每个神经元通过上千个突触与其他神经元相连。
早在20世纪初,科学家就已经发现神经元由细胞体和细胞突起组成。细胞体能够产生兴奋或抑制的生理活动;树突和轴突这两种细胞突起分别负责接收和传递兴奋信息。每个神经元可以被视为具有两种状态:兴奋和抑制。当神经元接收到的信号达到一定阈值时,它会进入兴奋状态,产生电脉冲,并通过突触传递给其他神经元。
人工神经网络是一种在结构、实现机理和功能上模拟人脑神经网络的学习模型。它由人工神经元节点相互连接而成,节点之间的连接都赋予了一定的权重,这些权重代表了一个节点对另一个节点的影响程度。在传输路径上,前一个节点的信息经过加权处理后传递到下一个节点,从而模拟了人脑神经信号的传递过程。
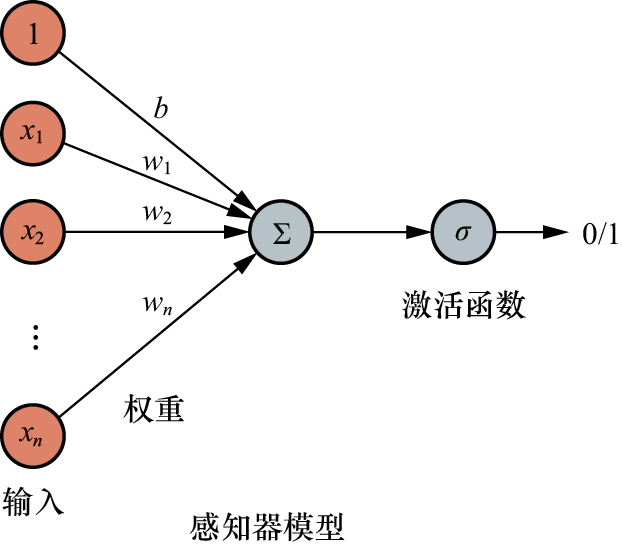
(1)简单感知器的第一代人工神经网络
第一代人工神经网络的发展可以追溯到1943年,当时麦卡洛克和皮茨合作提出了人工神经元的MP数学模型。接着,在1949年,心理学家唐纳德·赫布提出了基于赫布学习规则的无监督学习方法。进一步地,美国科学家罗森布拉特在1957年创新性地提出了感知器的概念,并在Cornell航空实验室的IBM 704机器上开发了神经感知器Mark1,后者能够识别一些英文字母。
在那个时期,学习模型初步具备了机器学习的思想,感知器本质上是一个单一的神经元,它能够对生物神经元进行简单的数学模拟。感知器包含了与生物神经元结构相对应的部件。到了20世纪60年代,人工神经网络得到了进一步的发展,出现了更完善的神经网络模型,包括感知器和自适应线性元件等。如图1-31所示,这些模型标志着人工神经网络技术的进步。然而,如图1-32所示,感知器的结构相对简单,它本质上并不适用于多层神经网络结构。这一局限性在后来的研究中逐渐显现,导致了人工神经网络研究在一段时间内的停滞。
图1-31 第一代人工神经网络实例
图1-32 感知器的结构图
(2)多层结构的第二代人工神经网络
20世纪80年代,人工智能领域兴起了一个研究热点。1986年,大卫·鲁姆哈特、杰弗里·辛顿和罗纳德·威廉姆斯系统阐述了反向传播(BP)算法,该算法通过引入多个隐藏层来代替感知器中的单个特征层,并采用反向传播来计算网络参数,解决了多层神经网络的学习问题,并成为流行的神经网络学习算法。1989年,杨立昆(Yann LeCun)等人成功地将卷积神经网络应用于手写体字符识别问题,促进多层神经网络技术得到不断的发展。
逐步地,人工神经网络从信息处理的角度对人脑神经元网络进行抽象,建立了某种简单模型,并按不同的连接方式组成不同的网络,目前已有近40种神经网络模型。根据连接的拓扑结构,神经网络模型可分为前馈网络(即前向传播网络)和反馈网络(即反向传播网络)。
假定神经元接受n 个输入I = (x 1 , x 2 , …, x n z 表示一个神经元所获得的输入信号x z 进一步映射,得到输出结果为a ,那么:
其中,w n 维权重向量,b 为偏置。
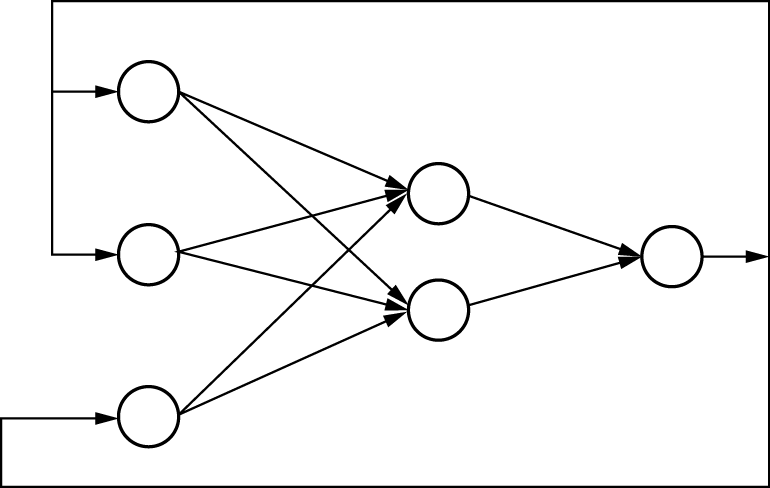
图1-33展示了多层神经网络的结构。该结构包含四层神经元节点,实现了三层感知信息的传递。神经元隶属于不同的层次,每一层的神经元能够接收来自前一层的信号,并传递信号至下一层。网络的第一层被称为输入层,负责接收初始信号;最后一层是输出层,输出最终处理结果;而位于输入层和输出层之间的层次被称为隐藏层。整个网络设计为无反馈模式,信号仅从输入层单向传播至输出层。每层神经元节点的数量根据需求来确定。例如,在处理手写数字识别问题时,由于需要识别的数字类别共有10种(即0~9),因此可以设计输出层的神经元节点数为10,每个节点分别输出对应数字类别的概率。
第二代人工神经网络通过解决多层信息感知问题提出了BP传输机制,但是BP算法容易陷入局部最优解,而且随着网络层数的增加,训练难度也越来越大。此外,第二代人工神经网络还存在一个问题,即反向传播的信号会随着层数的增加而逐渐减弱,这一问题限制了网络的层数,使得深层网络的训练变得非常困难。
图1-33 多层神经网络的结构
(3)深层结构的深度神经网络
1958年,Hubel和Wiesel的研究揭示了人脑皮层视觉信号传导机制的一个重要特性:在后脑皮层中存在方向选择性细胞。他们证实大脑皮层会对原始信号进行低级抽象,并逐渐向高级抽象迭代。进一步研究也表明,大脑皮层在认知活动中对信号的感知同样依赖复杂的模块层次结构。人类视觉系统的信息处理分级行为,即从低级的边缘特征到形状特征,再到整个目标行为特征,与多层神经网络信息特征传输与抽取的思想是一致的。
为了模仿人脑视觉信号传输的机理,研究者们引入了多层传输的感知器。2006年,杰弗里·辛顿及其同事提出了基于深度学习的深度信念网络(DBN)。该网络采用了贪心无监督训练方法,解决了隐藏层参数难以训练的问题,提高了深层网络的训练效率。深度神经网络(Deep Neural Network,DNN)的研究从此得到了发展。实际上,随着GPU、FPGA等器件的高性能计算,以及神经网络硬件和分布式深度学习技术的浮现,深度学习中的挑战性问题得到了解决。深度学习项目于2010年得到了美国国防部DARPA计划的资助;2011年,微软研究院和谷歌公司采用DNN将语音识别错误率降低20%~30%,取得10年来研究的最好成果;2012年,杰弗里·辛顿将ImageNet图片分类问题的Top5错误率由26%降低至15.3%。同期,吴恩达与杰夫·迪恩在Google Brain项目中采用10亿个神经元的深度网络,在图像识别领域取得突破性进展;2014年,谷歌公司将语言识别的精准度从2012年的84%提升到98%;人脸识别系统FaceNet在LFW数据集上达到99.63%的准确率;2016年,DeepMind公司研发了深度学习围棋软件AlphaGo,使用了1202个CPU集群和176个GPU,最终战胜人类围棋冠军李世石。国内在深度学习方面也取得了显著成效。2012年,华为成立“诺亚方舟实验室”,从事自然语言处理、人机交互等研究;2013年,百度成立“深度学习研究院”进行图像识别、检索等研究;同年,腾讯建立深度学习平台Mariana;2015年,阿里巴巴发布人工智能平台DTPAI。
目前,深度学习技术正在迅速发展,并已广泛应用于生活,成为人工智能技术发展的主要方向。它为机器超越人类能力提供了一种有效的手段,深度神经网络(DNN)技术具有巨大的潜力和挖掘空间。从神经网络的拓扑结构来看,根据网络中信息传输机制的不同,目前常见的神经网络类型包括深度神经网络、卷积神经网络(CNN)和循环神经网络(RNN)等。这些网络结构各具独特特点和适用场景,为解决复杂问题提供了多样化的技术方案。
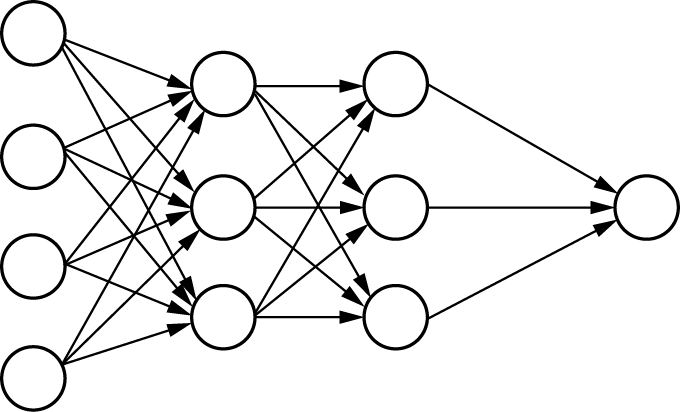
1.3.6 神经网络结构 常用的神经网络结构主要包括3种:前馈神经网络、反馈神经网络和图神经网络。前馈神经网络简称前馈网络,它由多层Logistic回归模型堆叠而成。在这种网络中,神经元从输入层开始,逐层传递信息,直至到达输出层。在传递过程中,信息通过中间的隐藏层,但层与层之间不进行反馈,结构如图1-34所示。
图1-34 前馈神经网络示意图
反馈神经网络简称反馈网络,具有强大的联想记忆和优化计算能力。在这种网络中,神经元不仅可以接收自身或其他神经元的信号,还会将其输出信号反馈给其他神经元。反馈网络中最简单且应用广泛的模型是Hopfield网络,它具有联想记忆功能。除此之外,循环神经网络(RNN)和玻尔兹曼机也属于反馈网络的范畴。反馈网络能够根据不同的状态和时间点进行描述。反馈网络的连接结构可以用有向循环图或无向图表示,具体如图1-35所示。图神经网络的拓扑结构为图结构,它可以向相邻节点或者自身传播信息,每个节点由一个或一组神经元构成。
图1-35 反馈神经网络示意图
深度神经网络的基本神经元包含计算和映射两部分。计算部分对输入信号进行加权求和,映射部分则通过激活函数处理这些求和结果。神经元接收n 个输入I =(x 1 , x 2 , …, x n z ,再通过激活函数将z 映射为输出a (如图1-36所示)。激活函数的作用是将无限的输入信号转换为有限的输出。它满足以下特点:一是作为连续且可导的非线性函数;二是函数及其导数应尽可能简单,以提升网络计算效率;三是其导函数的值域应位于一个适当的区间内。
图1-36 神经元信号处理过程
常用的Sigmoid激活函数有Logistic 函数和Tanh 函数。
(1)Logistic函数
Logistic函数定义为:
Logistic函数将实函数挤压至0~1之间,如图1-37所示。
图1-37 Logistic 函数曲线
Logistic函数的神经元具有以下功能:其输出可以直接被视为概率分布,这使得神经网络能够与统计学习模型结合使用。此外,该神经元还可以作为软门发挥作用,用于控制其他神经元的输出信息量。
(2)Tanh 函数
Tanh 函数定义为:
Tanh 函数将实函数映射到−1~1之间,如图1-38所示。
图1-38 Tanh函数曲线
除此之外,修正线性单元(Rectified Linear Unit,ReLU)函数也是常用的激活函数,为一个斜坡函数,定义如下:
ReLU函数可实现单侧抑制等功能。在模拟人脑稀疏的神经元激活特性时,使用Sigmoid激活函数会导致神经网络产生非稀疏的激活模式;而ReLU函数能够产生稀疏的激活效果,这与大脑神经元的稀疏激活机制相符。因此,ReLU函数在深度学习中可模拟更接近于人脑神经元的激活方式。
1.3.7 卷积神经网络 1. 卷积单元结构 从本质上看,卷积神经网络(CNN)属于前馈网络,由多层神经元组成,每层神经元只响应前一层局部范围内的特征。正如其名,CNN主要依赖卷积运算来处理数据。在CNN中,感受野是一个核心概念,它受到生物学中感受野的启发。在生物学领域,感受野指的是视网膜上能够激活特定神经元的特定区域。类似地,在CNN中,每个神经元的感受野定义了该神经元能够“看到”或“感受”到的空间区域。在CNN技术出现之前,多采用人工的全连接神经网络,即相邻层的任意两个神经元之间都有连接,如图1-39所示。
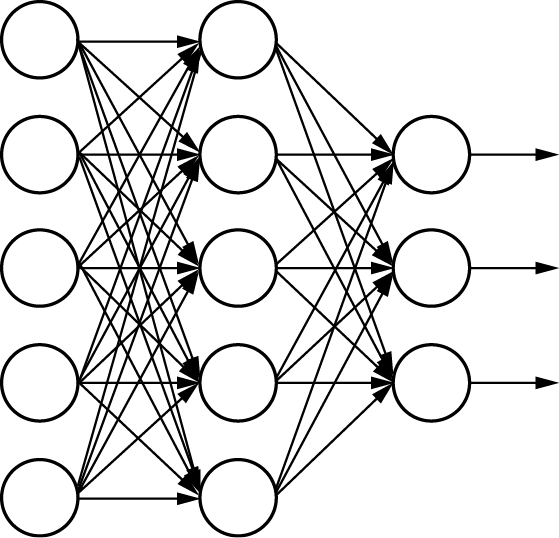
图1-39 全连接神经网络
尽管输入全部数据信息会对输出预测有一定帮助,然而,当输入层的特征维度过高时,全连接神经网络需要训练的参数会大幅增加,计算速度就会变得很慢。例如,对一张输入为32×32像素的RGB三通道手写数字识别图像来说,输入神经元就有3072个,对于全连接神经网络,需要训练的参数过多。CNN采用层次化运算结构,通过卷积层和池化层的堆叠,有效地提取图像中的特征。这种结构不仅减少了训练参数的数量,防止了过拟合,还提高了模型的泛化能力。在特征提取过程中,CNN能够自动学习图像的局部特征,如边缘、纹理和形状,并随着网络深度的增加,将这些局部特征组合成更复杂的对象表示,从而有助于图像的特征分析。
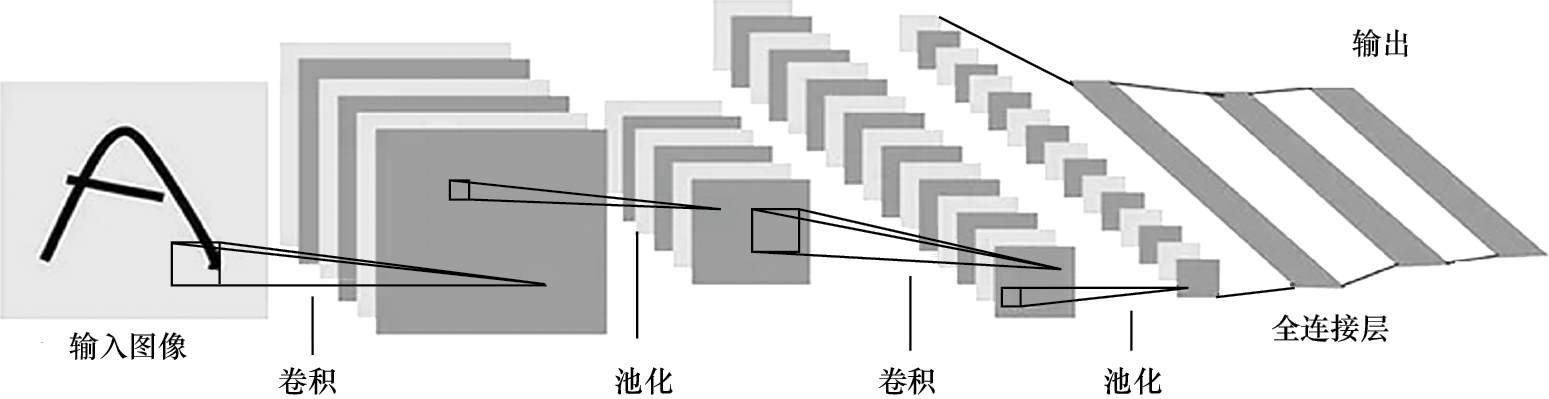
2. 卷积运算及特征 卷积神经网络主要用于图像特征的学习,通常由若干个卷积层(或称为卷积单元)组成。以图1-40所示的卷积神经网络为例,该网络包含两个卷积单元和一个全连接层。每个卷积单元内部包含卷积运算和池化操作,经过这两个卷积单元处理后,特征将被传递到全连接层进行进一步处理。
图1-40 卷积神经网络实例
对于卷积层来说,其基本的运算是卷积运算,卷积核有一定尺度,经过一个卷积核的运算后得到一张特征图。同理,利用多个卷积核,便可以得到多张特征图。进行多层的卷积处理,还可以进一步得到多层特征结构,关于这部分的知识将在后面章节中详述。
3. 几种典型的卷积神经网络 (1)LeNet
LeNet采用卷积神经网络结构,是一个经典的卷积特征学习模型,由杨立昆等人在1994年解决手写字符识别与分类问题时提出。他们采用LeNet开发的系统实现了98%的准确率,并成功地在美国的银行系统中投入使用。然而,由于当时缺乏大规模的训练数据集,加之计算机硬件性能有限,LeNet在处理更复杂的问题时并未达到预期效果。LeNet的网络结构相对简单,它包含了两个卷积单元。
第一个卷积单元包括1次2D卷积运算和池化处理。其中卷积运算中卷积核的大小为5×5,卷积核数量为6个,一共可以得到6张特征图。然后,利用池化对特征图进行下采样,特征图大小变为原来的1/2,即在水平方向和垂直方向上特征大小分别减半。第二个卷积单元包括1次2D卷积运算和池化处理。卷积核大小为5×5,数量变为16个,输出结果为16张特征图。然后是全连接层,有3层神经元,神经元个数分别为120、84和10,最后的10个神经元节点输出10个概率,表示当前手写数字是“0” “1” “2”等的类别概率。
(2)VGGNet
VGGNet是由牛津大学的视觉几何组(Visual Geometry Group,简称VGG)与谷歌DeepMind公司共同提出的深度卷积神经网络。该网络在2014年的ImageNet挑战赛中荣获亚军,VGGNet也因此而周知。
VGGNet结构灵活,可以根据需要调整卷积模块中的卷积层数量和卷积核大小。它共有5个卷积单元模块,每个卷积单元模块后面跟一个池化层,最后是3个全连接层。VGG16具有5个卷积单元模块,卷积核均为3×3,池化都使用大小为2×2、步幅(步长)为2的池化运算,卷积核数量分别为64、128、256、512、512。从VGG16到VGG19,网络通过增加卷积核的尺度来增大感受野,并通过使用更小的卷积核来减少网络参数的数量。由于在整个网络中多次使用了ReLU激活函数,这增强了网络的学习能力,使得模型能够更好地捕捉和学习数据中的复杂特征。
VGGNet的设计理念体现了增加网络层数的有效性。通过使用小尺度的卷积核进行逐层卷积,不仅可以逐步扩大感受野,还能有效减少参数的数量。此外,随着网络层数的加深,网络的精度也得到了提升。
(3)ResNet
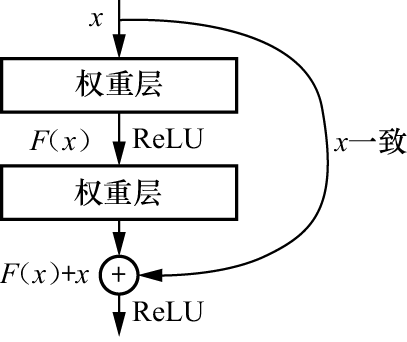
残差神经网络(ResNet)是由微软研究院的何凯明等人在2015年提出的。该网络构建的卷积神经网络深度达到152层。ResNet通过采用残差块的设计,解决了由网络深度增加带来的计算资源消耗大、模型容易过拟合及梯度消失等问题。残差神经网络由多个残差块堆叠而成,具体结构如图1-41所示。
图1-41 残差块的结构
残差块有两个分支:F (x )和x 。F (x )分支负责回归残差量,此分支有两种策略,一种是采用1×1 卷积层的瓶颈结构,另一种为基于两个3×3卷积层的瓶颈块。ResNet以残差块作为基本单元,其最大的优点是具有强大的可扩展性。这种设计使得网络能够方便地从深度和宽度两个维度进行扩展,从而在提升网络性能方面取得更好的效果。
1.4 计算机视觉编程基础1.4.1 Python语言简介 Python的创始人是来自荷兰的Guido van Rossum。他大学毕业后进入一个数学与计算机学术研究机构,加入ABC语言的开发团队,积累了宝贵的编程设计经验,形成对 Python 的最初设计思想。ABC是由Guido参与设计的一种教学语言,ABC语言具有风格优美和功能强大的特点,是专门为非专业程序员设计的。后来,Guido改进ABC,并加强与其他语言如 C、C++和Java的结合,特别是他借鉴了UNIX系统解释器Bourne Shell的风格和设计思想,利用简单脚本实现系统的管理功能,创建了Python语言。
Python语言功能强大,是一种面向对象、解释型脚本语言。Python的特点在于其简单清晰的语法和卓越的可扩展性,主要体现在Python的模块化设计上。Python拥有脚本语言中最丰富和最强大的标准库,这些库涵盖了文件I/O、图形用户界面(GUI)、网络编程、数据库交互、文本处理等众多应用领域。Python语言需要按照一定格式的缩进规范进行编写。此外,Python具有跨平台的特性,只要在目标平台上安装了相应的Python解释器,就可以在该平台运行Python代码。
Python语言的演化是一个不断发展和完善的过程。1989年,Guido启动了Python项目,到了1991年2月,Python 0.9.0公布。这也标志着第一个Python解释器的诞生,这个解释器是用C语言实现的,调用C语言库。在当时,Python已经包含类、函数、异常处理、列表和字典等数据类型,并且具有模块化的设计,这为后续功能扩展打下了坚实的基础。1994年1月,Python 1.0正式发布,标志着Python语言开始了一个新的阶段。2000年,Python 2.0发布。2001年,Python 2.1发布。从2004年开始,Python的使用率迅速增长。到了2008年12月,Python 3.0正式发布,这是一个重要的里程碑。
在Python的发展历程中,Python 2.7是一个特别稳定的版本,它在2010年7月3日发布,是2.x系列的最后一个版本,旨在帮助Python 2.x的用户将代码迁移到3.0版本。虽然Python 2.7与Python 3.0在功能上相似,但它们之间仍存在一些差异。特别是,Python 3.0并不完全兼容Python 2.7,这是用户在使用时需要特别注意的。下面简述Python语法基础。
1. 变量、标识符及表达式 Python变量采用标识符表示,其由字母、数字、下划线组成,但不能以数字开头。标识符中字母大小写是有差异的。使用变量前需要先赋值,没有默认值的机制,例如x = 3。Python中的数学表达式表示如2 + 2 + 4 - 2/3。Python 可以在同一行显示多条语句,方法是用分号(;)隔开。
2. 输入输出功能 Python可以接收用户的输入,例如x =input("x:"),运行后,用户终端的输入值就存入变量x中。Python也可以方便地打印变量的结果,例如print(x),即打印变量x的结果。此外,Python也可以使用格式控制符,例如print('%10.3f'%PI),即可打印出PI的值,格式为字段宽为10,小数部分的精度为3。同时,Python也支持字符串的串接、输出功能,例如在赋值hi = "hello"之后,输入print(hi + "world")可以输出字符串“helloworld”。
3. 数据结构及循环 在Python中,序列是最基础的一种数据结构。Python有6个与序列有关的内置类型:列表(List)、元组(Tuple)、字典、字符串、buffer对象和xrange对象。最常见的类型是列表和元组。
1)列表。列表中的元素可以是相同类型或者不同类型,所有元素用“[]”括起来,元素之间用逗号分隔开,例如list = [1, 2, 3, 4, 5, 6, 7],list是用户命名的列表变量。访问列表中元素如list[1:5],即访问第1个到第5个元素(序号从0开始)。
【例1-1】 列表具有合并功能。
[1,2] + [3,4] 输出结果为[1, 2, 3, 4]。
列表类型提供一些内置方法,可以添加元素。
【例1-2】 列表添加元素。
L = [12, 'Hi', 10.023]
L.append('Tues') 通过print(L)输出为[12, 'Hi', 10.023, 'Tues']。列表解析功能即利用表达式生成列表元素,例如[x*x for x in [0, 1, 2, 3]]可以生成列表[0, 1, 4, 9],这一功能很有用。
2)元组。与列表类似,元组类型可以看作一种“不变”的列表,也是通过下标访问元素,用“()”表示,元组内部元素用逗号隔开。但是其中元素不能二次赋值,相当于只读列表。
【例1-3】 元组的元素不能重新赋值。
tuple = ('abd', 76 , 2.13, 'Shn', 71.2 )
list = ['abd', 76 , 2.13, 'Shn', 71.2] tuple[2] = 200是非法操作,而list[2] = 200是合法操作。
3)字典。字典是除列表以外最灵活的内置数据结构类型,是一种可变容器模型,且可存储任意类型对象,与列表不同,字典是无序的对象集合。列表与字典之间的区别在于,字典当中的元素是通过键来存取的,而不是通过下标存取。
字典由键(key)及其对应的值(value)组成。字典的键值对之间用冒号(:)分隔,元素之间用逗号(,)分隔,字典数据列在花括号({})中。
【例1-4】 字典实例。
dict = {'name': 'Wang', 'like': 231, 'url': 'abc'} 字典中的键必须具有唯一性及不可变性,值则没有这个约定。字典也被称作关联数组或哈希表。
当同一个键被赋值两次时,旧值会被替换,最新值有效。键用数字、字符串或元组表示,但不能为列表。
可以输出某一个键对应的值,例如print(dict['name']),结果为“Wang”。
4)Python函数。为使用Python的数学计算功能,首先要通过import math导入数据计算库,然后再使用,例如math.cos(0.0)的结果为1。
对于Python,用户可以自定义函数并调用。
【例1-5】 Python的自定义函数实例。
def add_one(res):
print("Function got res", res)
return res + 1 5)Python循环。对于Python,有for循环和while循环。
【例1-6】 Python的for循环实例。
for value in [0, 1, 2, 3, 4, 5]:
print(value * value) 或者
mylist = [1,5,7]
for i in range(len(mylist)):
print(mylist[i]) while循环功能的编写与C语言类似:
n = 10
while n > 0:
print(n)
n = n-1 6)Python面向对象编程功能。Python支持面向对象的编程功能,可以自定义类。
【例1-7】 Python的自定义类实例。
class student:
def __init__(self, name, age):
self.name = name
self.age = age
def greet(self):
print("Hello, my name is %s!" % self.name) 其中student是类的名称,构造函数__init__用于对类中成员进行初始化。greet是一个成员函数。定义后可以声明类对象,例如stu = student("Wang", 22)。在定义类时,可以采用继承的方法。
【例1-8】 Python的自定义类的继承实例。
在例1-7的基础上,可以定义继承类elderStudent。
class elderStudent(student):
def __init__(self, name):
super().__init__(name, 22)
def greet(self):
print("Hi!") 1.4.2 图像处理的软件包 计算机视觉算法中经常需要利用OpenCV、PIL和Skimage处理图像。下面对这几种软件包进行简单介绍。
(1)OpenCV
OpenCV(Open Source Computer Vision Library)是一个开源的跨平台计算机视觉库,它提供了丰富的数字图像处理算法,广泛应用于各种场景。OpenCV的核心最初是用C语言编写的,并提供了面向对象的接口风格。它支持多种编程语言,包括C++、Python、Java和MATLAB,并且能够在多种操作系统上运行,如Windows、Linux、Android和macOS。OpenCV的历史可追溯到1999年,它由Intel公司创立。1999年1月,为了满足计算机视觉人机界面开发需求,出现OpenCV的早期0.X版本。2000年6月,第一个开源版本OpenCV alpha 3发布。同年12月,针对Linux平台的OpenCV beta 1问世。
随着OpenCV在功能和性能上的不断完善,各个发展版本相继推出。2006年,OpenCV 1.0正式发布,进一步完善了跨平台特性,并增加了对macOS的支持,同时对机器学习算法进行了优化。从2009年到2012年,在OpenCV 2.X系列的开发过程中,库架构基于C++进行了重写,同时保留了C API的功能。2012年,OpenCV 2.4发布。OpenCV 3.X系列则引入了OpenCL加速策略,特别是OpenCV 3.3对神经网络的支持能力显著提升。在性能大幅提升之后,OpenCV 4.0.0于2018年发布。
如今,OpenCV软件包已经广泛应用于图像分割、目标识别、人机交互等多个领域。它提供了丰富的数字图像处理功能,包括图像的灰度化和阈值化处理、图像增强的滤波处理等,为研究人员和开发者提供了强大的工具支持。
(2)Skimage
Skimage包的全称是Scikit-image,它是一组图像处理算法的集合,由志愿者社区团队基于Python编写,并遵循BSD开源许可证。目前,它已经成为图像处理的理想工具包,提供了一个高效且强大的图像算法函数库,能够满足研究人员的使用需求,并具备实际应用价值。它对SciPy.ndimage进行了扩展,提供了更多图像处理功能。Skimage包有许多子模块,主要子模块包括:读取、保存和显示图像的io模块,处理颜色空间变换的color模块,实现图像增强及边缘检测的filters模块,绘制基本图形的draw模块,处理几何变换的transform模块,形态学处理的morphology模块,调整图像强度的exposure模块,检测与提取特征的feature模块,测量图像属性的measure模块,分割图像的segmentation模块,恢复图像的restoration模块及util模块。
(3)PIL
PIL(Python Imaging Library)是一个功能强大的Python第三方图像处理库,曾被视作Python的官方图像处理库。PIL有着悠久的历史,但它只支持Python 2.7及之前的版本。随着Python 3的推出,出现了一个移植到Python 3的库,名为Pillow。Pillow是PIL的一个派生分支,它支持Python 3,并且随着时间的推移,Pillow已经发展成为比原始PIL功能更加强大的图像处理库。Pillow包括以下模块:Image、ImageChops、ImageColor、ImageDraw、ImageEnhance、ImageFile、ImageFilter、ImageFont、ImageGrab(Windows-only)、ImageMath、ImageOps、ImagePalette、ImagePath、ImageQt、ImageSequence、ImageStat、ImageTk、ImageWin和PSDraw。
1.4.3 深度学习编程框架 随着深度学习技术的深入研究及快速发展,近些年涌现了一系列深度学习框架,如Theano、Caffe、TensorFlow、PyTorch、PaddlePaddle、Chainer和MXNet等。下面以TensorFlow和PyTorch为例介绍深度学习编程框架。
1. TensorFlow框架基础 (1)TensorFlow的发展历程
2015年11月,针对人工智能研究领域的实际需求,谷歌公司对2011年推出的DistBelief深度学习基础架构进行了深入改进,开发了一个面向应用开发的框架系统——TensorFlow。TensorFlow主要应用于图像识别等领域,既适用于小规模的单台计算机设备,也适用于多台设备的中心服务器环境。
随着技术的不断进步,TensorFlow框架得到了快速发展。2016年4月,谷歌公司发布了TensorFlow 0.8,该版本支持分布式功能,并在初步版本的基础上进行了大量功能更新。性能上,它能够支持100个GPU同时工作,具有强大的分布式处理功能,并对人工智能产业产生巨大影响。同年,TensorFlow升级到0.9版本,重大功能得到提升,后续对iOS的支持意味着人工智能技术可以在移动端进一步拓展应用领域。
2017年,谷歌公司公布了TensorFlow 1.0.0-alpha,随后又推出了TensorFlow 1.0.0-rc0。TensorFlow 1.0在性能上进一步完善,以模型优化速度为提升动力,取得了显著的改进效果。2018年3月,谷歌公司发布了TensorFlow 1.7.0,其中集成了NVIDIA的Tensor RT软件包,对GPU硬件计算环境进行了高度优化,优化速度提升了数倍。
2018年7月,TensorFlow 1.9发布,支持多种平台(CPU、GPU、TPU)和各种设备终端的硬件环境,如桌面设备、服务器集群、移动设备、边缘设备等。此外,它支持结合Java API进行联合开发,以适应页面环境相关应用,并更新了Keras软件包,用于计算机视觉的图像分析。同时,它与TensorFlow.js 1.0相结合,构建了浏览器环境下的智能识别系统。
2019年10月,谷歌公司推出了TensorFlow 2.0,该版本在软件框架上进行改进,注重使用的简单性和易用性,可以结合Keras轻松构建模型,并在多个平台上实现稳定部署。它提供了强大的实验工具,同时简化了API,便于开发应用。
在近些年的发展中,TensorFlow不断推出新版本。这些不断更新的框架在并行计算、任务调度、复杂任务处理等方面进行了优化,提供了高性能的开发能力。
(2)TensorFlow使用基础
TensorFlow在处理深度学习模型时,遵循“定义”与“执行”分离的机制。首先,用户需要定义网络图,这包括模型的架构和计算任务。接下来,将数据注入网络图中,然后执行训练或预测操作。TensorFlow使用网络图来表示计算任务,而运行这些任务的上下文被称为会话(Session)。网络图的执行是在会话中进行的,其中使用张量(Tensor)存储数据,并用变量(Variable)表示网络模型中可优化的参数。
使用TensorFlow的过程首先涉及建立数据流图,然后以张量的形式将自定义数据输入数据流图中进行计算。这个数据流图对应机器学习中的学习模型。在定义数据流图时只须提供框架结构,在训练阶段才需要将训练数据按批次注入图中并进行计算,以优化网络的参数。
在TensorFlow中,张量是一个重要的概念,有多种类型。
1)零阶张量,即纯量或标量,例如[5]。
2)一阶张量,即一维向量形式,例如[3, 8, 1]。
3)二阶张量,即矩阵形式张量,例如[[65, 4, 98], [2, 4, 7], [5, 2, 7]]。
此外,还可以定义更高阶的张量。
下面阐述TensorFlow使用过程中的基本问题。
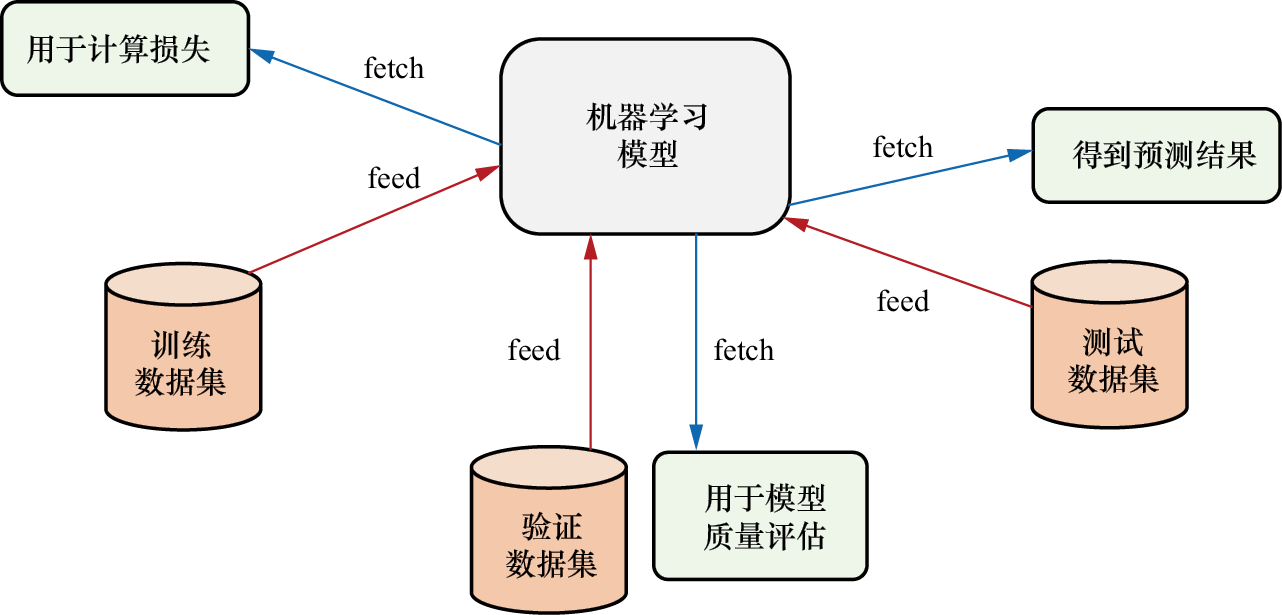
1)数据交互问题。深度学习模型通常以网络图的框架形式表示,并在获取数据后动态执行训练或预测任务。网络图在注入数据后开始工作,执行训练或预测操作。在TensorFlow中,网络图与数据集之间的交互通过注入数据(feed)和取回结果(fetch)来实现。
注入数据是指将数据集中的数据输入网络的计算图中,以便进行计算。取回结果则是在网络执行计算后,将计算结果从网络中取出。这两个过程合称为数据交互,它描述了数据集与机器学习模型之间的数据交换过程。针对不同的数据集,数据交互如图1-42所示。
图1-42 机器学习模型与数据集的交互示意图
2)Session的创建与使用。在TensorFlow的使用中,首先需要理解几个基本概念:张量是网络图中的数据容器,用于存储和传递数据;变量是深度学习模型中的可调参数,如卷积核权重和神经网络的权重与偏置,它们在网络训练过程中被优化;占位符则充当输入数据的载体,允许在模型运行时再提供具体数据;节点操作是计算图中的基本计算单元,它接收张量作为输入,执行计算并输出新的张量,这些操作共同描述了张量之间的运算关系,并通过网络图来执行各种计算任务。
在TensorFlow中,数据流图中的节点操作在得到执行之前,必须先创建Session对象,创建时有三个可选参数:①target,表示是否在分布式环境中运行会话,如果不在分布式环境中使用Session对象,该参数默认为空。②graph,指定了Session对象中加载的Graph对象,如果不指定,默认加载当前默认的数据流图,但是如果有多个图,就需要传入加载的图对象。③config,Session对象的一些配置信息,CPU/GPU使用上的限制及优化设置,例如allow_soft_placement选项可以把不适合在 GPU 上运行的节点操作全部放到CPU上运行;gpu_options.allow_growth可以设置逐步增长 GPU 显存使用量。
【例1-9】 创建一个Session对象,采用默认数据流图。
sess = tf.Session()
sess = tf.Session(graph=tf.get_default_graph) 【例1-10】 创建Session对象,然后再运行Session,最后关闭Session。
a=tf.constant([3,5,7,1])
b=tf.constant([2,4,6,8])
theresult=a+b
sess=tf.Session ()
print (sess.run(theresult))
sess.close 3)Session的数据注入机制。常采用数据字典方式来实现数据的注入功能,例如创建占位符,然后在数据字典(例如feed_dict)中为占位符注入数据,再传入数据流图中。
【例1-11】 创建占位符,再注入数据实例。
x= tf.placeholder(dtype=tf.float32)
y= tf.placeholder(dtype=tf.float32)
sub = x-y
product = x*y
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) #启动图后,变量初始化
print(' x + y = {0}'.format(sess.run(sub,feed_dict={x:3,y:4})))
print(' x * y = {0}'.format(sess.run(product,feed_dict={x:3,y:4}))) 2. PyTorch框架基础 (1)PyTorch的发展历程
Torch深度学习框架的开发始于2002年。Torch最初采用Lua语言作为其深度学习框架的编程接口,由于Lua语言使用受限,Facebook后来决定将Torch的Lua接口移植到Python。2016年,Facebook发布了PyTorch 0.1.1(alpha-1版本)。
PyTorch的发展经历了以下阶段:①2016年发布PyTorch 0.1.1,PyTorch和Torch共享的是底层的C语言API库,当时PyTorch借鉴了Torch的张量和模块等概念。②随着技术的不断发展,PyTorch改进并行计算和异构计算(CPU/GPU混合)性能,引入了多进程计算功能,集成了CuDNN的GPU深度学习计算库。③PyTorch 0.3.0支持更多损失函数和优化器。④PyTorch 0.4.0对分布式计算的支持更加完善,增加了对Windows操作系统的支持,实现了张量和变量的合并。⑤PyTorch 1.0在分布式计算方面对不同的后端提供较好的支持,并且可以把PyTorch的动态计算图编译成静态计算图。⑥PyTorch 1.1支持TensorBoard对张量的可视化功能,引入了新的API,支持分布式张量,并对开放神经网络交换格式有更好的支持。⑦PyTorch 1.2增强了TorchScript的功能,同时增加了Transformer模块,也提供对视频、文本和音频训练数据载入的功能。⑧PyTorch 1.3增加了移动端处理,而且增加了对模型量化功能的支持;引入了新的JIT编译器,并进一步改进分布式训练。⑨PyTorch 1.4支持C++ API,并进一步改进分布式训练功能。⑩PyTorch 1.5支持同步和异步Tensor传输,引入TensorPipe。⑪ PyTorch 1.6支持自动混合精度训练。⑫ PyTorch 1.7支持CUDA 10.2,改进分布式训练质量。⑬ PyTorch 1.8优化量化支持和支持CUDA11.1。⑭ PyTorch 1.9继续改进TorchScript和数据加载工具。
(2)PyTorch使用基础
以下是PyTorch的一些主要功能和模块。
1)自动求导功能:PyTorch 提供了一个自动求导的工具包 autograd,它能够自动计算神经网络中的梯度,这对模型的训练至关重要。
2)张量概念:PyTorch中的张量是一个多维数组,它支持多种数值计算,并且可以利用 GPU 进行加速计算,这使得PyTorch能够有效处理大规模数据计算。
3)nn模块:PyTorch的nn模块提供了一系列高级抽象,使得构建和训练神经网络更加容易。nn包定义了一组模块,这些模块可以用于神经网络的构建,如构建卷积层、池化层和全连接层等。
4)优化器:PyTorch 提供了多种常用的优化器,如 SGD、Adam、RMSProp等,这些优化器有助于用户更有效地训练模型。
5)常见类和封装:在PyTorch中,nn.Module类可以派生神经网络的模块,并且它提供了一个封装参数的方式,便于参数的管理和状态的保存,用户可以自定义网络结构,并通过nn.Module来封装网络中的层和操作。
1.4.4 深度学习编程实例 本小节给出一个基于PyTorch的深度学习编程实例。
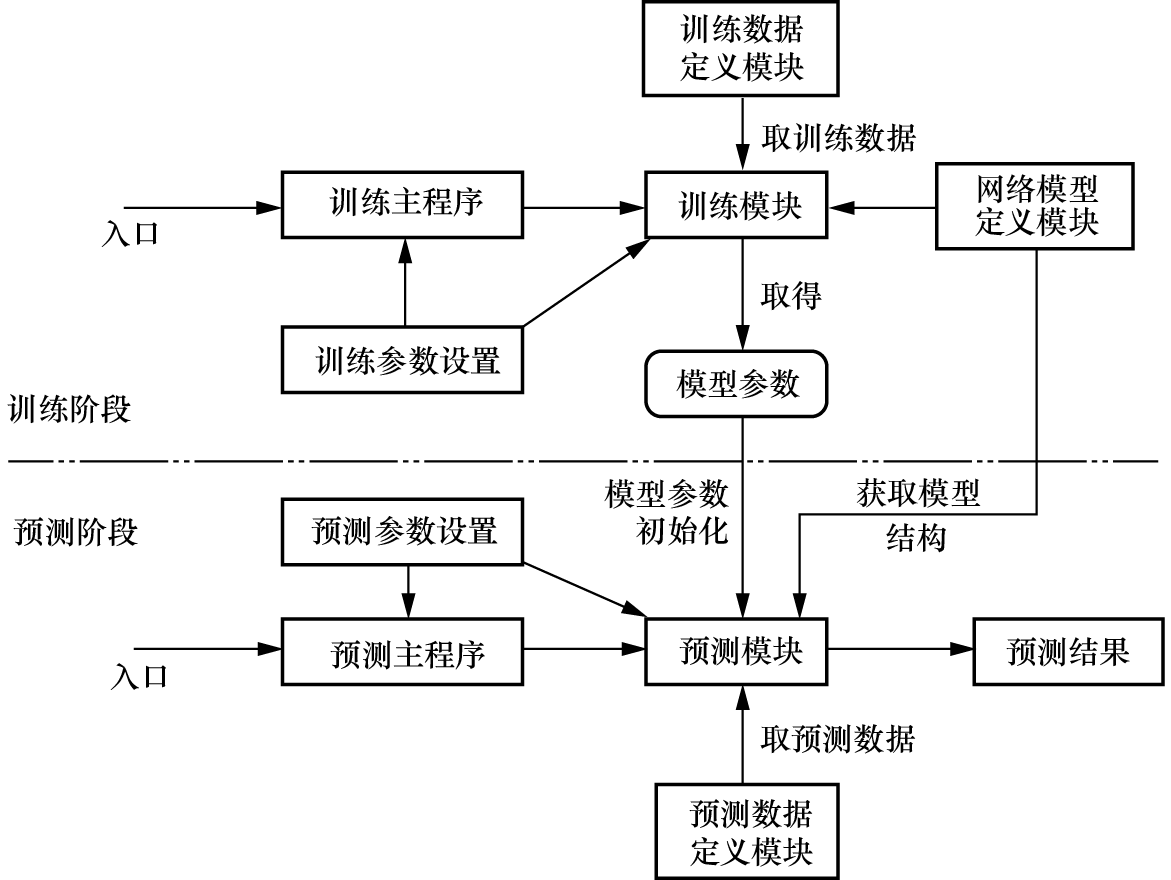
深度学习的算法框架一般包括训练阶段、预测阶段和评估阶段。这里着重阐述训练阶段和预测阶段的程序设计,如图1-43所示。
图1-43 深度学习的算法框架
训练阶段的程序结构主要包括训练主程序、训练数据定义模块、网络模型定义模块、训练参数设置和训练模块,各部分的功能如下。
1)训练主程序:训练程序入口。
2)训练数据定义模块:对训练数据进行初始化设置(包括数据路径及位置信息),为训练时取数据做准备。
3)网络模型定义模块:利用网络模型定义网络的拓扑结构。
4)训练参数设置:设置训练过程需要的参数,用于程序训练过程的参数及超参数设置,如学习率、epoch、批次等。
5)训练模块:用于网络训练。在初始化时,设置数据载入器、网络优化器及已有模型参数的初始化等;在训练过程中,通过取数据、输入数据和网络的优化控制,实现模型的迭代优化。
预测阶段的程序结构主要包括预测主程序、预测数据定义模块、网络模型定义模块、预测参数设置和预测模块,各部分的功能如下。
1)预测主程序:预测程序入口。
2)预测数据定义模块:对预测数据进行初始化设置(包括数据路径、位置信息及文件名信息等),为预测时取数据做准备。
3)网络模型定义模块:网络学习模型,与训练阶段的模型相同。
4)预测参数设置:设置预测过程需要的参数,用于程序预测过程的参数及超参数设置,如批次等。
5)预测模块:用于网络预测的初始化和预测过程。在初始化时,设置预测数据载入器,用已经训练的模型参数初始化网络等;在预测过程中,通过取数据、输入预测数据并预测,得到模型的预测结果。
习题 一、基础知识练习题 1.什么是计算机视觉?请举例说明计算机视觉的含义。
2.计算机视觉的任务和目的是什么?在计算机视觉技术发展过程中生物视觉起到什么作用?
3.计算机视觉技术主要应用在哪些领域?请举例说明。
4.计算机视觉与其他学科的关系如何?请列举两个相关学科的例子。
5.什么是数字图像?计算机视觉研究中数字图像处理起到什么作用?
6.什么是机器学习?常见的机器学习模型有哪些?
7.深度学习和机器学习之间有什么关系?
8.什么是卷积神经网络?请举例说明。
9.Python的列表、元组和字典有什么区别?请举例说明。
10.常见的深度学习编程框架有哪几种?
二、算法题 1.查找或编写一段带有循环功能的Python代码,说明其功能。
2.参考网络资源和技术,读取以下代码并说明其功能。
cv2.namedWindow('input_image', cv2.WINDOW_AUTOSIZE)
cv2.imshow("input_image",img)
cv2.waitKey(0)
cv2.destroyAllWindows() 3.如何利用OpenCV保存一幅图像?给出语句形式。
4.读取以下代码并说明其功能。
from skimage import io
import matplotlib.pyplot as plt
path = "E:/data/fruits.bmp"
img=io.imread(path)
io.imshow(img)
plt.show() 5.查阅资料或者参阅以下代码,实现多视图显示图像的功能。
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
from skimage import io
#读取灰度图
img = io.imread("E:\\image1.jpg")
img1= io.imread("E:\\image1.jpg",as_gray=True)
plt.subplot(121)
plt.title('before')
plt.imshow(img)
plt.subplot(122)
plt.title('after')
plt.imshow(img1,cmap='Greys_r')
plt.show()







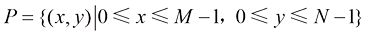 (1-1)
(1-1)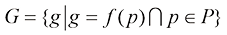 (1-2)
(1-2)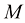 和
和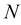 分别表示图像在水平及垂直方向的像素数量,
分别表示图像在水平及垂直方向的像素数量,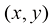 表示数字图像的像素点在设备坐标系下的坐标,
表示数字图像的像素点在设备坐标系下的坐标,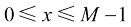 ,
, 。对于灰度图像,如图1-11a所示,函数值
。对于灰度图像,如图1-11a所示,函数值 表示
表示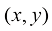 位置处像素的灰度值,其范围通常在0到255之间,0表示黑色,255表示白色;对于彩色图像,如图1-11b所示,函数值
位置处像素的灰度值,其范围通常在0到255之间,0表示黑色,255表示白色;对于彩色图像,如图1-11b所示,函数值




 个像素,垂直方向有
个像素,垂直方向有 ,也可以用与设备相关的每一英寸内的像素数(Dots Per Inch,DPI)描述图像的空间分辨率,DPI数值越大表示图像的空间分辨率越高。
,也可以用与设备相关的每一英寸内的像素数(Dots Per Inch,DPI)描述图像的空间分辨率,DPI数值越大表示图像的空间分辨率越高。


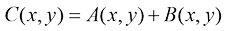 (1-3)
(1-3)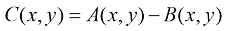 (1-4)
(1-4)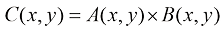 (1-5)
(1-5)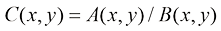 (1-6)
(1-6)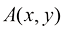 和
和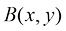 分别为两幅输入图像在
分别为两幅输入图像在

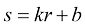 (1-7)
(1-7)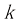 和
和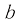 为线性变换系数。
为线性变换系数。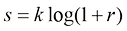 (1-8)
(1-8)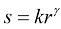 (1-9)
(1-9)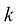 和
和 是参数,不同的取值直接影响变换结果。
是参数,不同的取值直接影响变换结果。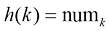 (1-10)
(1-10) 表示灰度级为
表示灰度级为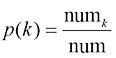 (1-11)
(1-11)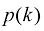 表示灰度级为
表示灰度级为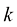 的像素统计概率,
的像素统计概率, 表示图像中像素的总数。利用直方图均衡化,实现图像的对比度拉伸,如图1-25所示。
表示图像中像素的总数。利用直方图均衡化,实现图像的对比度拉伸,如图1-25所示。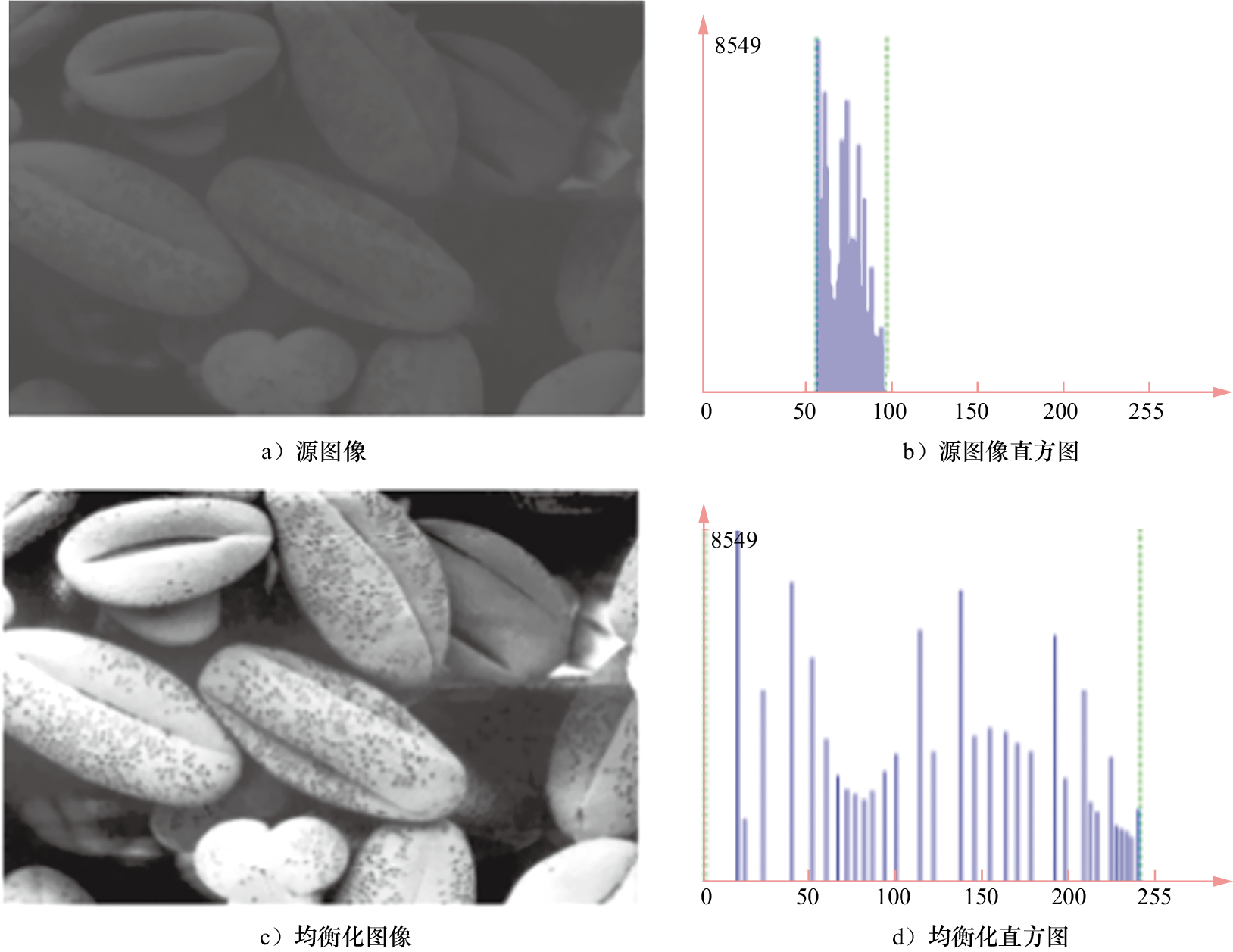
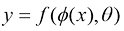 (1-12)
(1-12)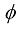 和
和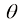 分别表示机器学习的模型和模型参数。
分别表示机器学习的模型和模型参数。

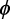 ,使该模型预测的结果与真实结果y之间相差极小,即使得模型预测误差e达到极小。
,使该模型预测的结果与真实结果y之间相差极小,即使得模型预测误差e达到极小。 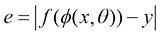 (1-13)
(1-13)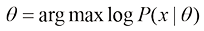 (1-14)
(1-14)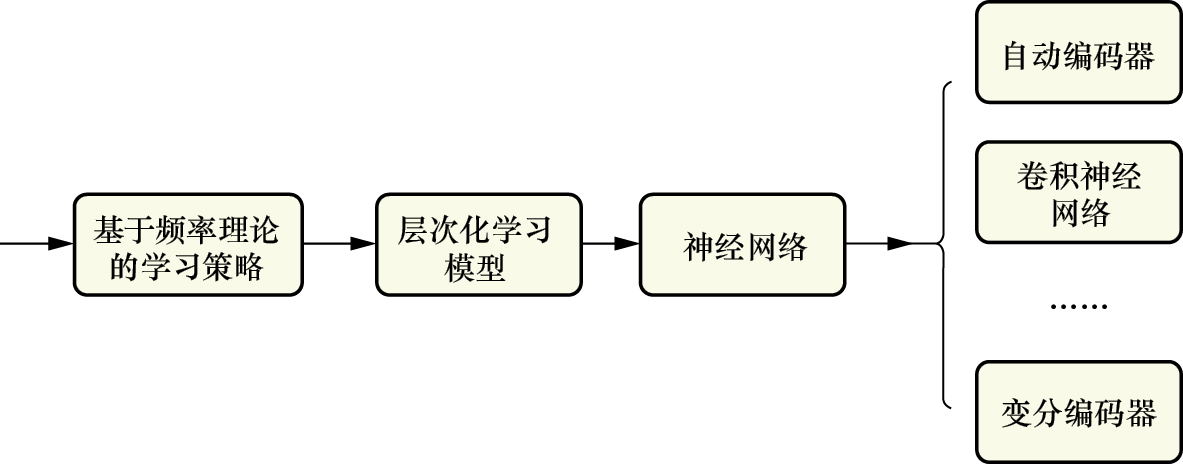
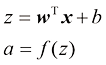 (1-15)
(1-15)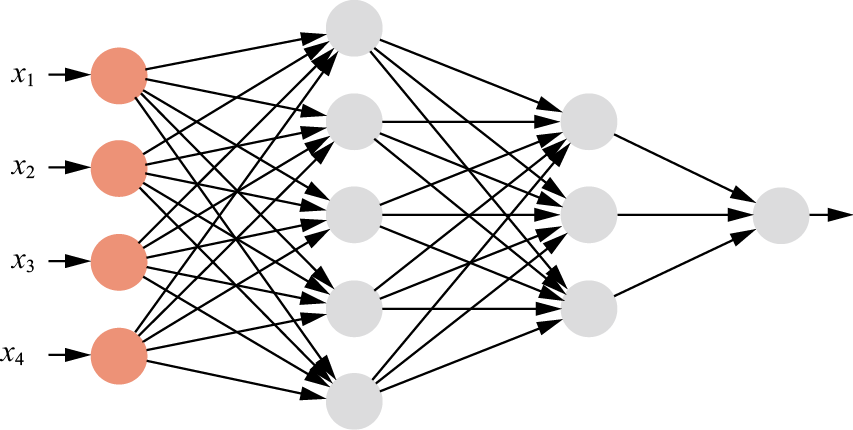

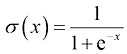 (1-16)
(1-16)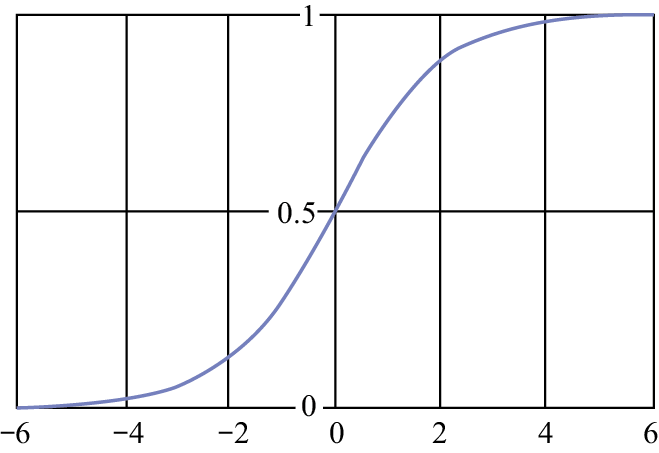
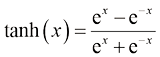 (1-17)
(1-17)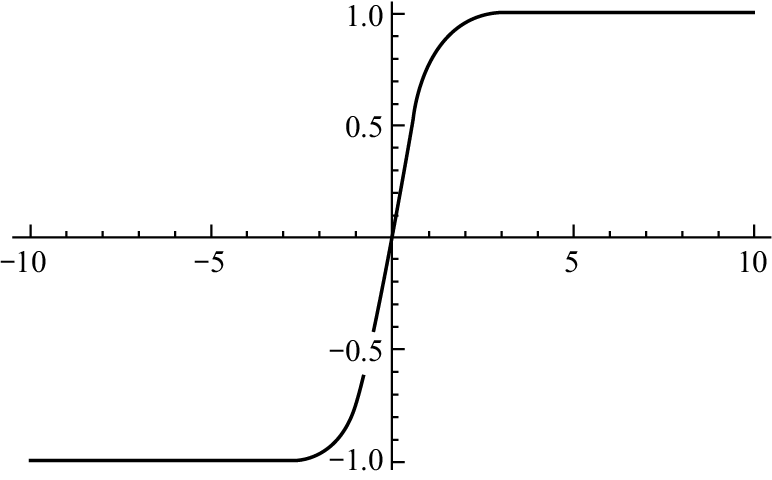
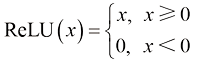 (1-18)
(1-18)