
详情
数据湖仓是一个现代化的开放式架构,拥有当今热门的开源数据技术的广度和灵活性。本书从初学者的角度出发,通过对数据湖仓重要概念的剖析,对数据湖仓的相关知识进行深入浅出的讲解。全书共18章,对数据湖仓的基础知识、数据工程、业务价值、数据集成等方面进行深入探讨,同时展望数据架构的演化趋势,使读者能够领会数据湖仓的精髓,最终轻松、全面地管理数据湖仓项目。
本书适合数据架构师、业务人员和系统开发人员,以及对数据管理、数据分析感兴趣的读者阅读。

书名:数据湖仓
ISBN:978-7-115-63888-5
本书由人民邮电出版社发行数字版。版权所有,侵权必究。
您购买的人民邮电出版社电子书仅供您个人使用,未经授权,不得以任何方式复制和传播本书内容。
我们愿意相信读者具有这样的良知和觉悟,与我们共同保护知识产权。
如果购买者有侵权行为,我们可能对该用户实施包括但不限于关闭该帐号等维权措施,并可能追究法律责任。
著 [美] 比尔·恩门(Bill Inmon)
[美]戴夫·拉皮恩(Dave Rapien)
[美]瓦莱丽·巴特尔特(Valerie Bartelt)
译 上海市静安区国际数据管理协会
责任编辑 秦 健
人民邮电出版社出版发行 北京市丰台区成寿寺路11号
邮编 100164 电子邮件 315@ptpress.com.cn
网址 http://www.ptpress.com.cn
读者服务热线:(010)81055410
反盗版热线:(010)81055315
The Data Lakehouse: The Bedrock for Artificial Intelligence, Machine Learning, and Data Mesh
Copyright ©2023 by Bill Inmon, Dave Rapien, Valerie Bartelt
Simplified Chinese translation copyright © 2024 by Posts and Telecommunications Press
Published by arrangement with DAMA China and Technical Publications.
ALL RIGHTS RESERVED.
本书简体中文版由DAMA联合Technical Publications授权人民邮电出版社有限公司出版。未经出版者书面许可,对本书的任何部分不得以任何方式或任何手段复制和传播。
版权所有,侵权必究。
数据湖仓是一个现代化的开放式架构,拥有当今热门的开源数据技术的广度和灵活性。本书从初学者的角度出发,通过对数据湖仓重要概念的剖析,对数据湖仓的相关知识进行深入浅出的讲解。全书共18章,对数据湖仓的基础知识、数据工程、业务价值、数据集成等方面进行深入探讨,同时展望数据架构的演化趋势,使读者能够领会数据湖仓的精髓,最终轻松、全面地管理数据湖仓项目。
本书适合数据架构师、业务人员和系统开发人员,以及对数据管理、数据分析感兴趣的读者阅读。
组长:胡 博
成员(按姓氏拼音排序):
白晓曦 成于念 郭泰圣 蒋 晟 金 里
雷 霆 李建昆 李新功 刘健玲 刘 泉
刘 睿 刘 申 吕顺锋 毛 军 孙军亮
孙熙麟 王 远 许其威 杨怡然 张 峰
张 印
这是DAMA中国(上海市静安区国际数据管理协会)团队翻译的第2本有关数据湖仓的英文图书,同样由享有“数据仓库之父”美誉的比尔·恩门及其团队所著。在此,我不得不赞叹比尔的高产,本书英文原著的出版,距离他的上一本图书《构建数据湖仓》面世还不到1年的时间。当拿到这本书的英文版时我都惊呆了,毕竟《构建数据湖仓》这本书的中文版才在2023年4月底上市,我们在7月就又拿到了比尔的新作品。比尔老先生诚挚地询问了我们这本书是否也能在中国出版。当然,也要对DAMA中国团队的志愿者表示感谢,他们的热情和效率丝毫不亚于作者本人,只用1个月的时间就完成了翻译工作。
特别感谢本书的作者比尔·恩门、戴夫·拉皮恩和瓦莱丽·巴特尔特,同时也要感谢DAMA中国团队的成员,他们是杨怡然(前言)、孙军亮(第1章)、孙熙麟(第2章)、李新功(第3章)、吕顺锋(第4章)、张峰(第5章)、王远(第6章)、白晓曦(第7章)、刘泉(第8章)、张印(第9章)、蒋晟(第10章)、李建昆(第11章)、郭泰圣(第12章)、刘健玲(第13章)、刘申(第14章)、成于念(第15章)、毛军和刘睿(第16章)、金里(第17章)、许其威和雷霆(第18章)。此外,也要特别感谢DAMA在中国的7位理事。近年来DAMA中国在知识体系、出版、培训及认证方面做了大量的工作,出版图书十余本,帮助两万余人获取了数据治理工程师(CDGA)、数据治理专家(CDGP)以及首席数据官认证(CCDO),这对于在国内推广和普及数据管理知识至关重要。因此,这届理事会成员的名字应该被铭记,他们是:汪广盛、毛颖、黄万忠、代国辉、蔡春久、郑保卫以及胡博。
比尔在前言中说“本书是为数据架构师、业务人员和系统开发人员准备的”,但我认为本书应该是为每一个人准备的。在数据已经成为生产要素的今天,每个人都应该进一步提升自己的数据素养,而本书正是一份合适的资料。和《构建数据湖仓》一样,本书的内容浅显易懂,案例丰富,读者在轻松阅读的同时能够系统地了解和熟悉数据湖仓架构,以及数据湖仓作为新型数字经济基础设施的重要性。
胡博 博士
DAMA中国理事
环顾四周,可以发现到处都有人为人工智能、机器学习或数据网格(Data Mesh)等技术的革新而兴奋不已。
事实上,新技术的出现和技术的进步确实孕育着巨大的发展前景。
但是,这些新技术的发展都有一个共同的前提:必须有可靠的数据来支持这些技术的应用。拥有可支持人工智能、机器学习和数据网格运行的数据源只是一种基本假设。
每个人都希望他所在的组织能够以数据驱动的方式运营。
但很多时候往往事与愿违。遗憾的是,人工智能、机器学习和数据网格与它们的前辈一样容易受到“垃圾进,垃圾出”(Garbage In,Garbage Out,GIGO)范式的影响。GIGO适用于人工智能、机器学习和数据网格,就像适用于其他已开发的技术一样。
事实上,目前仍缺乏坚实的数据基础设施,以有效支持各种新技术的运用。
然而,数据湖仓的出现改变了这一现状。数据湖仓架构不仅为新技术和复杂技术提供了数据基础,同时也为构建更深入的分析能力奠定了基础。
为了确保这些技术能够发挥作用,必须建立可靠的数据基础,同时其中仅仅有数据是不够的,还要确保这些数据具备以下特性:
● 可信;
● 具有延展性;
● 能够被共享。
只有拥有了具备上述特性的数据,我们才能推进如人工智能、机器学习和数据网格等新技术的运用。因此,一个合适的数据湖仓将提供强大的数据基础设施。
那么,支持未来应用程序的基础数据需要具备哪些品质呢?
针对这个问题,必须考虑不同类型的数据,特别是结构化数据、文本数据和模拟/物联网数据。这3种类型的数据具有不同的属性。针对其中某种数据类型的技能并不一定适用于其他类型的数据,像南极洲、亚马孙河和撒哈拉沙漠一样,这3个地方虽然都在地球上,但它们的地质风貌是完全不同的。
换句话说,不同类型的数据在检索、操作和使用规则以及使用方法上有很大的差异。然而,为了支持应用程序和数据处理,我们必须了解不同类型数据的不同特性。
本书讲述了现代信息系统中数据发展和生存所需的数据基础。没错,这本书是关于数据湖仓的。
本书是为数据架构师、业务人员和系统开发人员准备的。
希望本书的内容对你有用。我们也希望你在人工智能、机器学习和数据网格方面取得成功。
比尔·恩门
戴夫·拉皮恩
瓦莱丽·巴特尔特
2023年6月
本书提供如下资源:
● 本书思维导图;
● 异步社区7天VIP会员。
要获得以上资源,您可以扫描下方二维码,根据指引领取。

作者、译者和编辑尽最大努力来确保书中内容的准确性,但难免会存在疏漏。欢迎您将发现的问题反馈给我们,帮助我们提升图书的质量。
当您发现错误时,请登录异步社区(https://www.epubit. com),按书名搜索,进入本书页面,单击“发表勘误”,输入勘误信息,单击“提交勘误”按钮即可(见右图)。本书的作者、译者和编辑会对您提交的勘误信息进行审核,确认并接受后,您将获赠异步社区的100积分。积分可用于在异步社区兑换优惠券、样书或奖品。
我们的联系邮箱是contact@epubit.com.cn。
如果您对本书有任何疑问或建议,请您发邮件给我们,并请在邮件标题中注明本书书名,以便我们更高效地做出反馈。
如果您有兴趣出版图书、录制教学视频,或者参与图书翻译、技术审校等工作,可以发邮件给我们。
如果您所在的学校、培训机构或企业想批量购买本书或异步社区出版的其他图书,也可以发邮件给我们。
如果您在网上发现有针对异步社区出品图书的各种形式的盗版行为,包括对图书全部或部分内容的非授权传播,请您将怀疑有侵权行为的链接通过邮件发送给我们。您的这一举动是对作者权益的保护,也是我们持续为您提供有价值的内容的动力之源。
“异步社区”是由人民邮电出版社创办的IT专业图书社区,于2015年8月上线运营,致力于优质内容的出版和分享,为读者提供高品质的学习内容,为作译者提供专业的出版服务,实现作者与读者在线交流互动,以及传统出版与数字出版的融合发展。
“异步图书”是异步社区策划出版的精品IT图书的品牌,依托于人民邮电出版社在计算机图书领域四十余年的发展与积淀。异步图书面向IT行业以及各行业使用信息技术的用户。
每个终端用户(End User)都有一个共同的需求:访问想要的数据。事实上做到这点也确实不难,因为目前已经存在很多方式可以达到轻松访问数据的目的。如图1.1所示,终端用户可以通过多种方式访问数据,例如通过报告、电子表格、互联网信息或者知识图谱等方式访问数据。实际上,目前已经存在数百种访问数据的方式。
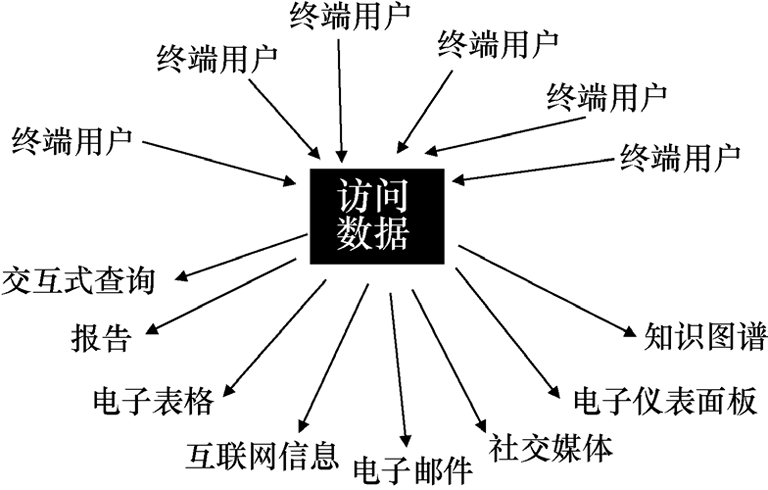
图1.1 终端用户可以通过多种方式访问数据
然而,与此同时又出现了一个问题:“我真的能够相信我正在访问的这些数据吗?”终端用户很快就会发现,访问数据和相信正在访问的数据是两回事。
访问数据和相信数据不是同一回事。
下面举个例子来说明访问不可信数据的情况。有人创建了一个电子表格,其中显示比尔·恩门每个月赚100万元。于是,在计算机数据库中就会出现一条每月赚取100万元的记录。
然而,事实并非如此。比尔·恩门并不是每个月都能赚100万元,但这条数据确实存储在计算机数据库中,是真实的数据内容。由此可见,尽管某些终端用户可以访问这条数据,但数据所传达的信息却可能是虚假的。
如果我们基于这样的信息做出决策,后果可想而知。尽管这条数据是可访问的,但并不可信。从某种角度来看,这条数据不仅是错误的,更可怕的是它还具有误导性,给人一种它是可信的这样的错觉。这就好像是一个陷阱,等待着毫无警惕的人们依此做出错误的决策。
因此,访问数据和相信数据不是同一回事。如果数据不可信,可能会导致决策和判断出现严重错误。
 1.1 做一个成熟的终端用户
1.1 做一个成熟的终端用户在访问计算机系统时,终端用户必须进行一个隐含的步骤,即从仅仅想要访问数据转变为想要访问可信的数据。
幸运的是,这个步骤非常直观,如图1.2所示。
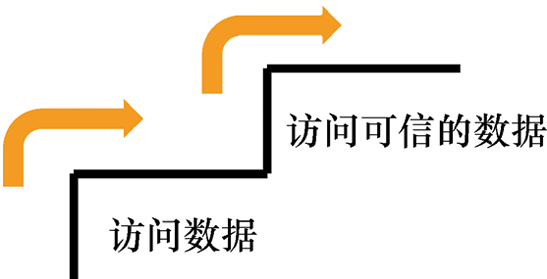
图1.2 隐含的步骤
图1.2展示的简单步骤只是成为成熟的终端用户或分析人员所需要的第一步。除此之外,终端用户还可能会在许多其他步骤中提出如下问题。
● 我能分析这些数据吗?
● 我能看到数据随时间的变化情况吗?
● 我能将这些数据与其他数据结合起来进行分析吗?
同时,在掌握计算机技术的过程中,终端用户还需要经历许多其他步骤,其中最基本的两个步骤如下。
● 我能访问自己的数据吗?
● 我能相信正在访问的数据吗?
下面我们进行一个判断数据可信度的简单练习。假设一位军事指挥官问了一个简单的问题:“我指挥的坦克有多少辆?”这个问题非常简单明了。指挥官希望从旗下两个营得到答案。
当指挥官问一个营的士兵时,会得到一个答案。但是,当指挥官问另一个营的士兵时,所获得的答案却完全不同。这时如果基于任意一个营的士兵的答案做出决策是一种冒险行为。
与上述情况类似,如图1.3所示,当指挥官询问ABC营可用坦克数量时,他们回答有1500辆。接着,指挥官询问XYZ营可用坦克数量,得到的答案是10 000辆。如果指挥官无法确定哪个答案是正确的,那么他可能做出灾难性的决策。
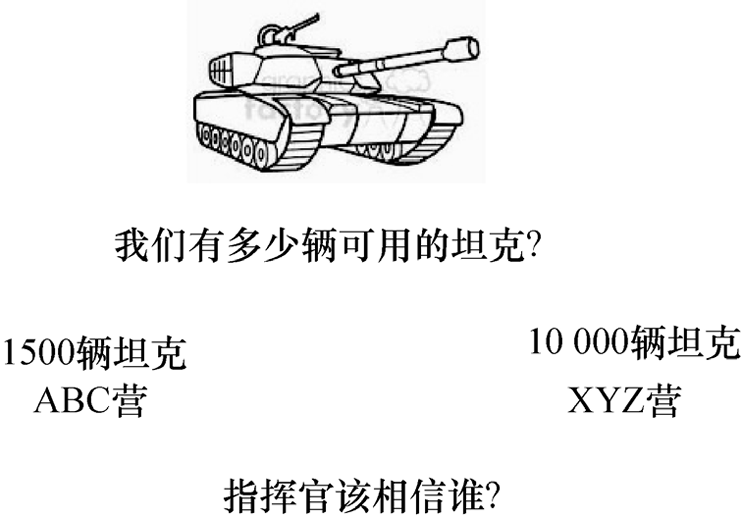
图1.3 判断数据可信度的简单练习
对指挥官来说,获取这些数据并不是最紧要的,理解所听到的数据才是问题的关键。
经过进一步调查,指挥官发现ABC营报告的是今天处于战备状态的坦克数量。这些坦克已得到保养和实地测试,装备齐全并位于指定位置。相比之下,XYZ营也有一些坦克,但是大部分处于预备役状态,尚未进行实地测试,装备不齐全并且存放在库房中。
事实上,指挥官所问的问题也需要更具体化。指挥官应该问“我们有多少辆处于战备状态的坦克”,或者问“我们有多少辆处于预备役状态的坦克”。由此可见,根据不可靠或不完全合格的信息做出决策是非常危险的。
要做出一个良好的决策,不仅要关注数据,还要获得可信数据的支持。
1.2 不断攀升的可信目标目标可以分为两种类型。
一种目标是特定目标。例如,在美式足球比赛中,为了得分,必须让足球越过球门线。球门线是固定的,它在比赛中不会移动。这就是一个特定目标的例子。
另一种目标是不断攀升的目标。例如,假设一个人希望成为一名出色的厨师,他决定从炒鸡蛋或烧开水开始练习。但很快他会发现,世界各地有很多菜肴可以供自己学习与烹饪实践,如墨西哥菜、中国菜、法国菜、日本菜等,可供学习的菜肴多种多样,永无止境。
那些梦想成为一名优秀厨师的人,一定不会尝试把世界上所有的菜肴都学会。毕竟总会有一些人们尚未尝试过的事情,学习烹饪也是如此。
然而,这并不意味着这个人不可能成为一名优秀的厨师。这仅仅意味着如果想要成为一名优秀的厨师,那么他的目标应该是不断攀升的。这一点与美式足球比赛中让足球越过球门线不同,烹饪有一个不断攀升的目标。
对数据可信度的追求是不断攀升的。如图1.4所示,我们需要不断提高数据的可信度,提高数据可信度的方法有很多种。与烹饪一样,提高数据的可信度是一个无止境的过程。
图1.4 需要不断提高数据的可信度
1.3 可信数据的要素可信数据的要素有哪些呢?除了简单的数据准确性以外,我们还需要了解以下内容:
● 数据的来源;
● 企业等组织首次采集数据的时间;
● 所有的数据转换情况;
● 是否进行了数据审核与编辑;
● 数据是否完整;
● 是否有能证实现有数据的其他数据;
● 数据的上下文情境;
● 数据采集和数据血缘的责任方;
● 采集数据的地点;
● 与数据相关的元数据及其上下文情境;
● 对数据进行的更改;
● 添加和附加到数据上的内容。
当然,以上只是简单列举。要想让终端用户完全理解数据,还需要了解与数据相关的许多其他方面的内容。
1.4 小结数据的可信度是技术世界所依赖的基础。如果数据不可信,世界就会受制于“垃圾进,垃圾出”(Garbage In,Garbage Out,GIGO)。





